

Chapter 3. Files - Part 4
From Expert Oracle Database Architecture: 9i and 10g Programming Techniques and Solutions, Berkeley, Apress, September 2005.
Part 1 | Part 2 | Part 3 | Part 4 | Part 5
Temp Files
Temporary data files (temp files) in Oracle are a special type of data file. Oracle will use temporary files to store the intermediate results of a large sort operation and hash operations, as well as to store global temporary table data, or result set data, when there is insufficient memory to hold it all in RAM. Permanent data objects, such as a table or an index, will never be stored in a temp file, but the contents of a temporary table and its indexes would be. So, you’ll never create your application tables in a temp file, but you might store data there when you use a temporary table.
Temp files are treated in a special way by Oracle. Normally, each and every change you make to an object will be recorded in the redo logs; these transaction logs can be replayed at a later date in order to “redo a transaction,” which you might do during recovery from failure, for example. Temp files are excluded from this process. Temp files never have redo generated for them, although they can have undo generated. Thus, there will be redo generated working with temporary tables since UNDO is always protected by redo, as you will see in detail in Chapter 9. The undo generated for global temporary tables is in order to support rolling back some work you have done in your session, either due to an error processing data or because of some general transaction failure. A DBA never needs to back up a temporary data file, and in fact to attempt to do so would be a waste of time, as you can never restore a temporary data file.
It is recommended that your database be configured with locally-managed temporary tablespaces. You’ll want to make sure that as a DBA, you use a CREATE TEMPORARY TABLESPACE command. You do not want to just alter a permanent tablespace to a temporary one, as you do not get the benefits of temp files that way.
One of the nuances of true temp files is that if the OS permits it, the temporary files will be created sparse — that is, they will not actually consume disk storage until they need to. You can see that easily in this example (on Red Hat Linux in this case):
ops$tkyte@ORA10G> !df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/hda2 74807888 41999488 29008368 60% /
/dev/hda1 102454 14931 82233 16% /boot
none 1030804 0 1030804 0% /dev/shm
ops$tkyte@ORA10G> create temporary tablespace temp_huge
2 tempfile '/d01/temp/temp_huge' size 2048m
3 /
Tablespace created.
ops$tkyte@ORA10G> !df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/hda2 74807888 41999616 29008240 60% /
/dev/hda1 102454 14931 82233 16% /boot
none 1030804 0 1030804 0% /dev/shm
Note: df is a Unix command to show “disk free.” This command showed that I have 29,008,368KB free in the file system containing /d01/temp before I added a 2GB temp file to the database. After I added that file, I had 29,008,240KB free in the file system.
Apparently it took only 128KB of storage to hold that file. But if we ls it
ops$tkyte@ORA10G> !ls -l /d01/temp/temp_huge
-rw-rw---- 1 ora10g ora10g 2147491840 Jan 2 16:34 /d01/temp/temp_huge
it appears to be a normal 2GB file, but it is in fact only consuming some 128KB of storage. The reason I point this out is because we would be able to actually create hundreds of these 2GB temporary files, even though we have roughly 29GB of disk space free. Sounds great — free storage for all! The problem is as we start to use these temp files and they start expanding out, we would rapidly hit errors stating “no more space.” Since the space is allocated or physically assigned to the file as needed by the OS, we stand a definite chance of running out of room (especially if after we create the temp files someone else fills up the file system with other stuff).
How to solve this differs from OS to OS. On Linux, some of the options are to use dd to fill the file with data, causing the OS to physically assign disk storage to the file, or use cp to create a nonsparse file, for example:
ops$tkyte@ORA10G> !cp --sparse=never /d01/temp/temp_huge /d01/temp/temp_huge2
ops$tkyte@ORA10G> !df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/hda2 74807888 44099336 26908520 63% /
/dev/hda1 102454 14931 82233 16% /boot
none 1030804 0 1030804 0% /dev/shm
ops$tkyte@ORA10G> drop tablespace temp_huge;
Tablespace dropped.
ops$tkyte@ORA10G> create temporary tablespace temp_huge
2 tempfile '/d01/temp/temp_huge2' reuse;
Tablespace created.
ops$tkyte@ORA10G> !df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/hda2 74807888 44099396 26908460 63% /
/dev/hda1 102454 14931 82233 16% /boot
none 1030804 0 1030804 0% /dev/shm
After copying the sparse 2GB file to /d01/temp/temp_huge2 and creating the temporary tablespace using that temp file with the REUSE option, we are assured that temp file has allocated all of its file system space and our database actually has 2GB of temporary space to work with.
Note: In my experience, Windows NTFS does not do sparse files, and this applies to UNIX/Linux variants. On the plus side, if you have to create a 15GB temporary tablespace on UNIX/Linux and have temp file support, you’ll find it goes very fast (instantaneous), but just make sure you have 15GB free and reserve it in your mind.
Control Files
The control file is a fairly small file (it can grow up to 64MB or so in extreme cases) that contains a directory of the other files Oracle needs. The parameter file tells the instance where the control files are, and the control files tell the instance where the database and online redo log files are.
The control files also tell Oracle other things, such as information about checkpoints that have taken place, the name of the database (which should match the DB_NAME parameter), the timestamp of the database as it was created, an archive redo log history (this can make a control file large in some cases), RMAN information, and so on.
Control files should be multiplexed either by hardware (RAID) or by Oracle when RAID or mirroring is not available. More than one copy of them should exist, and they should be stored on separate disks, to avoid losing them in the event you have a disk failure. It is not fatal to lose your control files — it just makes recovery that much harder.
Control files are something a developer will probably never have to actually deal with. To a DBA they are an important part of the database, but to a software developer they are not extremely relevant.
Redo Log Files
Redo log files are crucial to the Oracle database. These are the transaction logs for the database. They are generally used only for recovery purposes, but they can be used for the following as well:
- Instance recovery after a system crash
- Media recovery after a data file restore from backup
- Standby database processing
- Input into Streams, a redo log mining process for information sharing (a fancy way of saying replication)
Their main purpose in life is to be used in the event of an instance or media failure, or as a method of maintaining a standby database for failover. If the power goes off on your database machine, causing an instance failure, Oracle will use the online redo logs to restore the system to exactly the point it was at immediately prior to the power outage. If your disk drive containing your data file fails permanently, Oracle will use archived redo logs, as well as online redo logs, to recover a backup of that drive to the correct point in time. Additionally, if you “accidentally” drop a table or remove some critical information and commit that operation, you can restore a backup and have Oracle restore it to the point immediately prior to the accident using these online and archive redo log files.
Virtually every operation you perform in Oracle generates some amount of redo to be written to the online redo log files. When you insert a row into a table, the end result of that insert is written to the redo logs. When you delete a row, the fact that you deleted that row is written. When you drop a table, the effects of that drop are written to the redo log. The data from the table you dropped is not written; however, the recursive SQL that Oracle performs to drop the table does generate redo. For example, Oracle will delete a row from the SYS.OBJ$ table (and other internal dictionary objects), and this will generate redo, and if various modes of supplemental logging are enabled, the actual DROP TABLE statement will be written into the redo log stream.
Some operations may be performed in a mode that generates as little redo as possible. For example, I can create an index with the NOLOGGING attribute. This means that the initial creation of the index data will not be logged, but any recursive SQL Oracle performed on my behalf will be. For example, the insert of a row into SYS.OBJ$ representing the existence of the index will be logged, as will all subsequent modifications of the index using SQL inserts, updates, and deletes. But the initial writing of the index structure to disk will not be logged.
I’ve referred to two types of redo log file: online and archived. We’ll take a look at each in the sections that follow. In Chapter 9, we’ll take another look at redo in conjunction with rollback segments, to see what impact they have on you as the developer. For now, we’ll just concentrate on what they are and what their purpose is.
Online Redo Log
Every Oracle database has at least two online redo log file groups. Each redo log group consists of one or more redo log members (redo is managed in groups of members). The individual redo log file members of these groups are true mirror images of each other. These online redo log files are fixed in size and are used in a circular fashion. Oracle will write to log file group 1, and when it gets to the end of this set of files, it will switch to log file group 2 and rewrite the contents of those files from start to end. When it has filled log file group 2, it will switch back to log file group 1 (assuming we have only two redo log file groups; if we have three, it would, of course, proceed to the third group). This is shown in Figure 3-4.
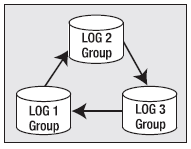
Figure 3-4. Log file groups
The act of switching from one log file group to the other is called a log switch. It is important to note that a log switch may cause a temporary “pause” in a poorly configured database. Since the redo logs are used to recover transactions in the event of a failure, we must assure ourselves that we won’t need the contents of a redo log file in the event of a failure before we reuse it. If Oracle isn’t sure that it won’t need the contents of a log file, it will suspend operations in the database momentarily and make sure that the data in the cache that this redo “protects” is safely written (checkpointed) onto disk itself. Once Oracle is sure of that, processing will resume and the redo file will be reused.
We’ve just started to talk about a key database concept: checkpointing. To understand how online redo logs are used, you’ll need to know something about checkpointing, how the database buffer cache works, and what a process called data block writer (DBWn) does. The database buffer cache and DBWn are covered in more detail a little later on, but we’ll skip ahead a little anyway and touch on them now.
The database buffer cache is where database blocks are stored temporarily. This is a structure in the SGA of Oracle. As blocks are read, they are stored in this cache, hopefully to allow us to not have to physically reread them later. The buffer cache is first and foremost a performance-tuning device. It exists solely to make the very slow process of physical I/O appear to be much faster than it is. When we modify a block by updating a row on it, these modifications are done in memory, to the blocks in the buffer cache. Enough information to redo this modification is stored in the redo log buffer, another SGA data structure. When we COMMIT our modifications, making them permanent, Oracle does not go to all of the blocks we modified in the SGA and write them to disk. Rather, it just writes the contents of the redo log buffer out to the online redo logs. As long as that modified block is in the buffer cache and is not on disk, we need the contents of that online redo log in the event the database fails. If at the instant after we committed, the power was turned off, the database buffer cache would be wiped out.
If this happens, the only record of our change is in that redo log file. Upon restart of the database, Oracle will actually replay our transaction, modifying the block again in the same way we did and committing it for us. So, as long as that modified block is cached and not written to disk, we cannot reuse that redo log file.
This is where DBWn comes into play. This Oracle background process is responsible for making space in the buffer cache when it fills up and, more important, for performing checkpoints. A checkpoint is the writing of dirty (modified) blocks from the buffer cache to disk. Oracle does this in the background for us. Many things can cause a checkpoint to occur, the most common event being a redo log switch.
As we filled up log file 1 and switched to log file 2, Oracle initiated a checkpoint. At this point in time, DBWn started writing to disk all of the dirty blocks that are protected by log file group 1. Until DBWn flushes all of these blocks protected by that log file, Oracle cannot reuse it. If we attempt to use it before DBWn has finished its checkpoint, we will get a message like this in our database’s ALERT log:
...
Thread 1 cannot allocate new log, sequence 66
Checkpoint not complete
Current log# 2 seq# 65 mem# 0: C:\ORACLE\ORADATA\ORA10G\REDO02.LOG
...
So, at the point in time when this message appeared, processing was suspended in the database while DBWn hurriedly finished its checkpoint. Oracle gave all the processing power it could to DBWn at that point in the hope it would finish faster.
This is a message you never want to see in a nicely tuned database instance. If you do see it, you know for a fact that you have introduced artificial, unnecessary waits for your end users. This can always be avoided. The goal (and this is for the DBA, not the developer necessarily) is to have enough online redo log files allocated so that you never attempt to reuse a log file before the checkpoint initiated by it completes. If you see this message frequently, it means a DBA has not allocated sufficient online redo logs for the application, or that DBWn needs to be tuned to work more efficiently.
Different applications will generate different amounts of redo log. A Decision Support System (DSS, query only) or DWsystem will naturally generate significantly less online redo log than an OLTP (transaction processing) system would, day to day. A system that does a lot of image manipulation in Binary Large Objects (BLOBs) in the database may generate radically more redo than a simple order-entry system. An order-entry system with 100 users will probably generate a tenth the amount of redo 1,000 users would generate. There is no “right” size for your redo logs, although you do want to ensure they are large enough for your unique workload.
You must take many things into consideration when setting both the size of and the number of online redo logs. Many of them are beyond the scope of this particular book, but I’ll list some of them to give you an idea:
- Peak workloads: You would like your system to not have to wait for checkpoint notcomplete messages, to not get bottlenecked during your peak processing. You will be sizing your redo logs not for “average” hourly throughput, but rather for your peak processing. If you generate 24GB of log per day, but 10GB of that log is generated between 9:00 am and 11:00 am, you’ll want to size your redo logs large enough to carry you through that two-hour peak. Sizing them for an average of 1GB per hour would probably not be sufficient.
- Lots of users modifying the same blocks: Here you might want large redo log files. Since everyone is modifying the same blocks, you would like to update them as many times as possible before writing them out to disk. Each log switch will fire a checkpoint, so you would like to switch logs infrequently. This may, however, affect your recovery time.
- Mean time to recover: If you must ensure that a recovery takes as little time as possible, you may be swayed toward smaller redo log files, even if the previous point is true. It will take less time to process one or two small redo log files than a gargantuan one upon recovery. The overall system will run slower than it absolutely could day to day perhaps (due to excessive checkpointing), but the amount of time spent in recovery will be shorter. There are other database parameters that may also be used to reduce this recovery time, as an alternative to the use of small redo log files.
Archived Redo Log
The Oracle database can run in one of two modes: ARCHIVELOG mode and NOARCHIVELOG mode. The difference between these two modes is simply what happens to a redo log file when Oracle goes to reuse it. “Will we keep a copy of that redo or should Oracle just overwrite it, losing it forever?” is an important question to answer. Unless you keep this file, you cannot recover data from a backup to the current point in time.
Say you take a backup once a week on Saturday. Now, on Friday afternoon, after you have generated hundreds of redo logs over the week, your hard disk fails. If you have not been running in ARCHIVELOG mode, the only choices you have right now are as follows:
- Drop the tablespace(s) associated with the failed disk. Any tablespace that had a file on that disk must be dropped, including the contents of that tablespace. If the SYSTEM tablespace (Oracle’s data dictionary) is affected, you cannot do this.
- Restore last Saturday’s data and lose all of the work you did that week.
Neither option is very appealing. Both imply that you lose data. If you had been executing in ARCHIVELOG mode, on the other hand, you simply would have found another disk. You would have restored the affected files from Saturday’s backup onto it. Lastly, you would have applied the archived redo logs and, ultimately, the online redo logs to them (in effect replaying the week’s worth of transactions in fast-forward mode). You lose nothing. The data is restored to the point in time of the failure.
People frequently tell me they don’t need ARCHIVELOG mode for their production systems. I have yet to meet anyone who was correct in that statement. I believe that a system is not a production system unless it is in ARCHIVELOG mode. A database that is not in ARCHIVELOG mode will, some day, lose data. It is inevitable; you will lose data if your database is not in ARCHIVELOG mode.
“We are using RAID-5, so we are totally protected” is a common excuse. I’ve seen cases where, due to a manufacturing error, all disks in a RAID set froze, all at about the same time. I’ve seen cases where the hardware controller introduced corruption into the data files, so they safely protected corrupt data with their RAID devices. RAID also does not do anything to protect you from operator error, one of the most common causes of data loss.
“If we had the backups from before the hardware or operator error and the archives were not affected, we could have recovered.” The bottom line is that there is no excuse for not being in ARCHIVELOG mode on a system where the data is of any value. Performance is no excuse; properly configured archiving adds little to no overhead. This and the fact that a “fast system” that “loses data” is useless would make it so that even if archiving added 100 percent overhead, you would need to do it. A feature is overhead if you can remove it and lose nothing important; overhead is like icing on the cake. Preserving your data, and making sure you don’t lose you data isn’t overhead — it’s the DBA’s primary job!
Only a test or development system should execute in NOARCHIVELOG mode. Don’t let anyone talk you out of being in ARCHIVELOG mode. You spent a long time developing your application, so you want people to trust it. Losing their data will not instill confidence in your system.
Note: There are some cases in which a large DW could justify being in NOARCHIVELOG mode if it made judicious use of READ ONLY tablespaces and was willing to fully rebuild any READ WRITE tablespace that suffered a failure by reloading the data.
Password Files
The password file is an optional file that permits remote SYSDBA or administrator access to the database.
When you attempt to start up Oracle, there is no database available that can be consulted to verify passwords. When you start up Oracle on the “local” system (i.e., not over the network, but from the machine the database instance will reside on), Oracle will use the OS to perform the authentication.
When Oracle was installed, the person performing the installation was asked to specify the “group” for the administrators. Normally on UNIX/Linux, this group will be DBA by default and OSDBA on Windows. It can be any legitimate group name on that platform, however. That group is “special,” in that any user in that group can connect to Oracle “as SYSDBA” without specifying a username or password. For example, in my Oracle 10g Release 1 install, I specified an ora10g group. Anyone in the ora10g group may connect without a username/password:
[ora10g@localhost ora10g]$ sqlplus / as sysdba
SQL*Plus: Release 10.1.0.3.0 - Production on Sun Jan 2 20:13:04 2005
Copyright (c) 1982, 2004, Oracle. All rights reserved.
Connected to:
Oracle Database 10g Enterprise Edition Release 10.1.0.3.0 - Production
With the Partitioning, OLAP and Data Mining options
SQL> show user
USER is "SYS"
That worked — I’m connected, and I could now start up this database, shut it down, or perform whatever administration I wanted to. However, suppose I wanted to perform these operations from another machine, over the network. In that case, I would attempt to connect using @tns-connect-string. However, this would fail:
[ora10g@localhost admin]$ sqlplus as sysdba
SQL*Plus: Release 10.1.0.3.0 - Production on Sun Jan 2 20:14:20 2005
Copyright (c) 1982, 2004, Oracle. All rights reserved.
ERROR:
ORA-01031: insufficient privileges
Enter user-name:
OS authentication won’t work over the network for SYSDBA, even if the very unsafe (for security reasons) parameter REMOTE_OS_AUTHENT is set to TRUE. So, OS authentication won’t work and, as discussed earlier, if you’re trying to start up an instance to mount and open a database, then there by definition is “no database” at the other end of the connection yet, in which to look up authentication details. It is the proverbial chicken and egg problem. Enter the password file. The password file stores a list of usernames and passwords that are allowed to remotely authenticate as SYSDBA over the network. Oracle must use this file to authenticate them and not the normal list of passwords stored in the database.
So, let’s correct our situation. First, we’ll start up the database locally so we can set the REMOTE_LOGIN_PASSWORDFILE. Its default value is NONE, meaning there is no password file; there are no “remote SYSDBA logins.” It has two other settings: SHARED (more than one database can use the same password file) and EXCLUSIVE (only one database uses a given password file). We’ll set ours to EXCLUSIVE, as we want to use it for only one database (i.e., the normal use):
SQL> alter system set remote_login_passwordfile=exclusive scope=spfile;
System altered.
This setting cannot be changed dynamically while the instance is up and running, so we’ll have to restart for this to take effect. The next step is to use the command-line tool (on UNIX and Windows) named orapwd:
[ora10g@localhost dbs]$ orapwd
Usage: orapwd file=<fname> password=<password> entries=<users> force=<y/n>
where
file - name of password file (mand),
password - password for SYS (mand),
entries - maximum number of distinct DBA and OPERs (opt),
force - whether to overwrite existing file (opt),
There are no spaces around the equal-to (=) character.
to create and populate the initial password file. The command we’ll use is
$ orapwd file=orapw$ORACLE_SID password=bar entries=20
That created a password file named orapwora10g in my case (my ORACLE_SID is ora10g). That is the naming convention for this file on most UNIX platforms (see your installation/OS admin guide for details on the naming of this file on your platform), and it resides in the $ORACLE_HOME/dbs directory. On Windows, this file is named PW%ORACLE_SID%.ora and is located in the %ORACLE_HOME%\database directory.
Now, currently the only user in that file is in fact the user SYS, even if there are other SYSDBA accounts on that database (they are not in the password file yet). Using that knowledge, however, we can for the first time connect as SYSDBA over the network:
[ora10g@localhost dbs]$ sqlplus sys/bar@ora10g_admin.localdomain as sysdba
SQL*Plus: Release 10.1.0.3.0 - Production on Sun Jan 2 20:49:15 2005
Copyright (c) 1982, 2004, Oracle. All rights reserved.
Connected to an idle instance.
SQL>
We have been authenticated, so we are in — we can now successfully start up, shut down, and remotely administer this database using the SYSDBA account. Now, we have another user, OPS$TKYTE, who has been granted SYSDBA, but will not be able to connect remotely yet:
[ora10g@localhost dbs]$ sqlplus 'ops$tkyte/foo' as sysdba SQL*Plus: Release 10.1.0.3.0 - Production on Sun Jan 2 20:51:07 2005 Copyright (c) 1982, 2004, Oracle. All rights reserved. Connected to: Oracle Database 10g Enterprise Edition Release 10.1.0.3.0 - Production With the Partitioning, OLAP and Data Mining options SQL> show user USER is "SYS" SQL> exit [ora10g@localhost dbs]$ sqlplus 'ops$tkyte/foo@ora10g_admin.localdomain' as sysdba SQL*Plus: Release 10.1.0.3.0 - Production on Sun Jan 2 20:52:57 2005 Copyright (c) 1982, 2004, Oracle. All rights reserved. ERROR: ORA-01031: insufficient privileges Enter user-name:
The reason for that is that OPS$TKYTE is not yet in the password file. In order to get OPS$TKYTE into the password file, we need to “regrant” that account SYSDBA:
SQL> grant sysdba to ops$tkyte;
Grant succeeded.
Disconnected from Oracle Database 10g
Enterprise Edition Release 10.1.0.3.0 - Production
With the Partitioning, OLAP and Data Mining options
[ora10g@localhost dbs]$ sqlplus 'ops$tkyte/foo@ora10g_admin.localdomain' as sysdba
SQL*Plus: Release 10.1.0.3.0 - Production on Sun Jan 2 20:57:04 2005
Copyright (c) 1982, 2004, Oracle. All rights reserved.
Connected to:
Oracle Database 10g Enterprise Edition Release 10.1.0.3.0 - Production
With the Partitioning, OLAP and Data Mining options
That created an entry in the password file for us, and Oracle will now keep the password “in sync.” If OPS$TKYTE alters his password, the old one will cease working for remote SYSDBA connections and the new one will start:
SQL> alter user ops$tkyte identified by bar;
User altered.
[ora10g@localhost dbs]$ sqlplus 'ops$tkyte/foo@ora10g_admin.localdomain' as sysdba
SQL*Plus: Release 10.1.0.3.0 - Production on Sun Jan 2 20:58:36 2005
Copyright (c) 1982, 2004, Oracle. All rights reserved.
ERROR:
ORA-01017: invalid username/password; logon denied
Enter user-name: ops$tkyte/bar@ora10g_admin.localdomain as sysdba Connected to: Oracle Database 10g Enterprise Edition Release 10.1.0.3.0 - Production With the Partitioning, OLAP and Data Mining options SQL> show user USER is "SYS" SQL>
The same process is repeated for any user that was a SYSDBA but is not yet in the password file.
--
Thomas Kyte is the Vice President of the Core Technologies Group at Oracle Corporation and has been with them since version 7.0.9 was released in 1993. Kyte, however, has been working with Oracle since version 5.1.5c. At Oracle Corp., Kyte works with the Oracle database, and more specifically, he helps clients who are using the Oracle database and works directly with them specifying and building their systems or rebuilding and tuning them. Prior to working at Oracle, Kyte was a systems integrator who built large scale, heterogeneous databases and applications for military and government clients. Tom Kyte is the same “Ask Tom” whose column appears in Oracle Magazine, where he answers questions about the Oracle database and tools that developers and DBAs struggle with every day.
Contributors : Tom Kyte
Last modified 2006-01-20 01:06 PM