

Chapter 3. Files - Part 3
From Expert Oracle Database Architecture: 9i and 10g Programming Techniques and Solutions, Berkeley, Apress, September 2005.
Part 1 | Part 2 | Part 3 | Part 4 | Part 5
Alert File
The alert file (also known as the alert log) is the diary of the database. It is a simple text file written to from the day the database is “born” (created) to the end of time (until you erase it). In this file, you will find a chronological history of your database — the log switches; the internal errors that might be raised; when tablespaces were created, taken offline, put back online; and so on. It is an incredibly useful file for seeing the history of a database. I like to let mine grow fairly large before “rolling” (archiving) them. The more information the better, I believe, for this file.
I will not describe everything that goes into an alert log — that is a fairly broad topic. I encourage you to take a look at yours, however, and see the wealth of information that is in there. Instead, in this section we’ll take a look at a specific example of how to mine information from this alert log, in this case to create an uptime report.
I recently used the alert log file for the http://asktom.oracle.com website and to generate an uptime report for my database. Instead of poking through the file and figuring that out manually (the shutdown and startup times are in there), I decided to take advantage of the database and SQL to automate this, thus creating a technique for creating a dynamic uptime report straight from the alert log.
Using an EXTERNAL TABLE (which is covered in much more detail Chapter 10), we can actually query our alert log and see what is in there. I discovered that a pair of records was produced in my alert log every time I started the database:
Thu May 6 14:24:42 2004
Starting ORACLE instance (normal)
That is, a timestamp record, in that constant fixed width format, coupled with the message Starting ORACLE instance. I also noticed that before these records there would either be an ALTER DATABASE CLOSE message (during a clean shutdown) or a shutdown abort message, or “nothing” — no message, indicating a system crash. But any message would have some timestamp associated with it as well. So, as long as the system didn’t “crash,” some meaningful timestamp would be recorded in the alert log (and in the event of a system crash, some timestamp would be recorded shortly before the crash, as the alert log is written to quite frequently).
I noticed that I could easily generate an uptime report if I
- Collected all of the records like Starting ORACLE instance %
- Collected all of the records that matched the date format (that were in fact dates)
- Associated with each Starting ORACLE instance record the prior two records (which would be dates)
The following code creates an external table to make it possible to query the alert log. (Note: replace /background/dump/dest/ with your actual background dump destination and use your alert log name in the CREATE TABLE statement.)
ops$tkyte@ORA10G> create or replace directory data_dir as '/background/dump/dest/'
2 /
Directory created.
ops$tkyte@ORA10G> CREATE TABLE alert_log
2 (
3 text_line varchar2(255)
4 )
5 ORGANIZATION EXTERNAL
6 (
7 TYPE ORACLE_LOADER
8 DEFAULT DIRECTORY data_dir
9 ACCESS PARAMETERS
10 (
11 records delimited by newline
12 fields
13 REJECT ROWS WITH ALL NULL FIELDS
14 )
15 LOCATION
16 (
17 'alert_AskUs.log'
18 )
19 )
20 REJECT LIMIT unlimited
21 /
Table created.
We can now query that information anytime:
ops$tkyte@ORA10G> select to_char(last_time,'dd-mon-yyyy hh24:mi') shutdown,
2 to_char(start_time,'dd-mon-yyyy hh24:mi') startup,
3 round((start_time-last_time)*24*60,2) mins_down,
4 round((last_time-lag(start_time) over (order by r)),2) days_up,
5 case when (lead(r) over (order by r) is null )
6 then round((sysdate-start_time),2)
7 end days_still_up
8 from (
9 select r,
10 to_date(last_time, 'Dy Mon DD HH24:MI:SS YYYY') last_time,
11 to_date(start_time,'Dy Mon DD HH24:MI:SS YYYY') start_time
12 from (
13 select r,
14 text_line,
15 lag(text_line,1) over (order by r) start_time,
16 lag(text_line,2) over (order by r) last_time
17 from (
18 select rownum r, text_line
19 from alert_log
20 where text_line like '___ ___ __ __:__:__ 20__'
21 or text_line like 'Starting ORACLE instance %'
22 )
23 )
24 where text_line like 'Starting ORACLE instance %'
25 )
26 /
SHUTDOWN STARTUP MINS_DOWN DAYS_UP DAYS_STILL_UP
----------------- ----------------- ---------- ---------- -------------
06-may-2004 14:00
06-may-2004 14:24 06-may-2004 14:24 .25 .02
10-may-2004 17:18 10-may-2004 17:19 .93 4.12
26-jun-2004 13:10 26-jun-2004 13:10 .65 46.83
07-sep-2004 20:13 07-sep-2004 20:20 7.27 73.29 116.83
I won’t go into the nuances of the SQL query here, but the innermost query from lines 18 through 21 collect the “Starting” and date lines (remember, when using a LIKE clause, _ matches precisely one character — at least one and at most one). It also “numbers” the lines using ROWNUM. Then, the next level of query uses the built-in LAG() analytic function to reach back one and two rows for each row, and slide that data up so the third row of this query has the data from rows 1, 2, and 3. Row 4 has the data from rows 2, 3, and 4, and so on. We end up keeping just the rows that were like Starting ORACLE instance %, which now have the two preceding timestamps associated with them. From there, computing downtime is easy: we just subtract the two dates. Computing the uptime is not much harder (now that you’ve seen the LAG() function): we just reach back to the prior row, get its startup time, and subtract that from this line’s shutdown time.
My Oracle 10g database came into existence on May 6 and it has been shut down four times (and as of this writing it has been up for 116.83 days in a row). The average uptime is getting better and better over time (and hey, it is SQL — we could easily compute that now, too).
If you are interested in seeing another example of mining the alert log for useful information, go to http://asktom.oracle.com/~tkyte/alert_arch.html. This page shows a demonstration of how to compute the average time it took to archive a given online redo log file. Once you understand what is in the alert log, generating these queries on your own becomes easy.
Data Files
Data files, along with redo log files, are the most important set of files in the database. This is where all of your data will ultimately be stored. Every database has at least one data file associated with it, and typically it will have many more than one. Only the most simple “test” database will have one file. In fact, in Chapter 2 we saw the most simple CREATE DATABASE command by default created a database with two data files: one for the SYSTEM tablespace (the true Oracle data dictionary) and one for the SYSAUX tablespace (where other nondictionary objects are stored in version 10g and above). Any real database, however, will have at least three data files: one for the SYSTEM data, one for SYSAUX data, and one for USER data.
After a brief review of file system types, we’ll discuss how Oracle organizes these files and how data is organized within them. To understand this, you need to know what a tablespace, segment, extent, and block are. These are the units of allocation that Oracle uses to hold objects in the database, and I describe them in detail shortly.
A Brief Review of File System Mechanisms
There are four file system mechanisms in which to store your data in Oracle. By your data, I mean your data dictionary, redo, undo, tables, indexes, LOBs, and so on — the data you personally care about at the end of the day. Briefly, they are
- “Cooked” operating system (OS) file systems: These are files that appear in the file system just like your word processing documents do. You can see them in Windows Explorer; you can see them in UNIX as the result of an ls command. You can use simple OS utilities such as xcopy on Windows or cp on UNIX to move them around. Cooked OS files are historically the “most popular” method for storing data in Oracle, but I personally expect to see that change with the introduction of ASM (more on that in a moment). Cooked file systems are typically buffered as well, meaning that the OS will cache information for you as you read and, in some cases, write to disk.
- Raw partitions: These are not files — these are raw disks. You do not ls them; you do not review their contents in Windows Explorer. They are just big sections of disk without any sort of file system on them. The entire raw partition appears to Oracle as a single large file. This is in contrast to a cooked file system, where you might have many dozens or even hundreds of database data files. Currently, only a small percentage of Oracle installations use raw partitions due to their perceived administrative overhead. Raw partitions are not buffered devices — all I/O performed on them is a direct I/O, without any OS buffering of data (which, for a database, is generally a positive attribute).
- Automatic Storage Management (ASM): This is a new feature of Oracle 10g Release 1 (for both Standard and Enterprise editions). ASM is a file system designed exclusively for use by the database. An easy way to think about it is as a database file system. You won’t store your shopping list in a text file on this file system — you’ll store only databaserelated information here: your tables, indexes, backups, control files, parameter files, redo logs, archives, and more. But even in ASM, the equivalent of a data file exists; conceptually, data is still stored in files, but the file system is ASM. ASM is designed to work in either a single machine or clustered environment.
- Clustered file system: This is specifically for a RAC (clustered) environment and provides for the appearance of a cooked file system that is shared by many nodes (computers) in a clustered environment. A traditional cooked file system is usable by only one computer is a clustered environment. So, while it is true that you could NFS mount or Samba share (a method of sharing disks in a Windows/UNIX environment similar to NFS) a cooked file system among many nodes in a cluster, it represents a single point of failure. In the event that the node owning the file system and performing the sharing was to fail, then that file system would be unavailable. The Oracle Cluster File System (OCFS) is Oracle’s offering in this area and is currently available for Windows and Linux only. Other third-party vendors do provide certified clustered file systems that work with Oracle as well. The clustered file system brings the comfort of a cooked file system to a clustered environment.
The interesting thing is that a database might consist of files from any and all of the preceding file systems — you don’t need to pick just one. You could have a database whereby portions of the data were stored in conventional cooked file systems, some on raw partitions, others in ASM, and yet other components in a clustered file system. This makes it rather easy to move from technology to technology, or to just get your feet wet in a new file system type without moving the entire database into it. Now, since a full discussion of file systems and all of their detailed attributes is beyond the scope of this particular book, we’ll dive back into the Oracle file types. Regardless of whether the file is stored on cooked file systems, in raw partitions, within ASM, or on a clustered file system, the following concepts always apply.
The Storage Hierarchy in an Oracle Database
A database is made up of one or more tablespaces. A tablespace is a logical storage container in Oracle that comes at the top of the storage hierarchy and is made up of one or more data files. These files might be cooked files in a file system, raw partitions, ASM-managed database files, or files on a clustered file system. A tablespace contains segments, as described next.
Segments
We will start our examination of the storage hierarchy by looking at segments, which are the major organizational structure within a tablespace. Segments are simply your database objects that consume storage — objects such as tables, indexes, rollback segments, and so on. When you create a table, you create a table segment. When you create a partitioned table, you create a segment per partition. When you create an index, you create an index segment, and so on. Every object that consumes storage is ultimately stored in a single segment. There are rollback segments, temporary segments, cluster segments, index segments, and so on.
Note: It might be confusing to read “Every object that consumes storage is ultimately stored in a single segment.” You will find many CREATE statements that create mulitsegment objects. The confusion lies in the fact that a single CREATE statement may ultimately create objects that consist of zero, one, or more segments! For example, CREATE TABLE T ( x int primary key, y clob ) will create four segments: one for the TABLE T, one for the index that will be created in support of the primary key, and two for the CLOB (one segment for the CLOB is the LOB index and the other segment is the LOB data itself). On the other hand, CREATE TABLE T ( x int, y date ) cluster MY_CLUSTER, will create no segments.We’ll explore this concept further in Chapter 10.
Extents
Segments themselves consist of one or more extent. An extent is a logically contiguous allocation of space in a file (files themselves, in general, are not contiguous on disk; otherwise, we would never need a disk defragmentation tool!). Also, with disk technologies such as Redundant Array of Independent Disks (RAID), you might find a single file is not only not contiguous on a single disk, but also spans many physical disks. Every segment starts with at least one extent, and some objects may require at least two (rollback segments are an example of a segment that require at least two extents). For an object to grow beyond its initial extent, it will request another extent be allocated to it. This second extent will not necessarily be located right next to the first extent on disk — it may very well not even be allocated in the same file as the first extent. The second extent may be located very far away from the first extent, but the space within an extent is always logically contiguous in a file. Extents vary in size from one Oracle data block to 2GB.
Blocks
Extents, in turn, consist of blocks. A block is the smallest unit of space allocation in Oracle. Blocks are where your rows of data, or index entries, or temporary sort results will be stored. A block is what Oracle generally reads from and writes to disk. Blocks in Oracle are generally one of four common sizes: 2KB, 4KB, 8KB, or 16KB (although 32KB is also permissible in some cases; there are restrictions in place as to the maximum size by operating system).
Note: Here’s a little-known fact: the default block size for a database does not have to be a power of two. Powers of two are just a convention commonly used. You can, in fact, create a database with a 5KB, 7KB, or nKB block size, where n is between 2KB and 32KB. I do not advise making use of this fact in real life, though — stick with 2KB, 4KB, 8KB, or 16KB as your block size.
The relationship between segments, extents, and blocks is shown in Figure 3-1.
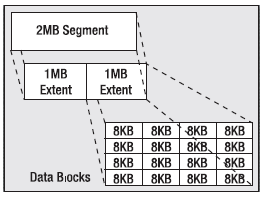
Figure 3-1. Segments, extents, and blocks
A segment is made up of one or more extents, and an extent is a contiguous allocation of blocks. Starting with Oracle9i Release 1, a database may have up to six different block sizes in it.
Note: This feature of multiple block sizes was introduced for the purpose of making transportable tablespaces usable in more cases. The ability to transport a tablespace allows a DBA to move or copy the already formatted data files from one database and attach them to another — for example, to immediately copy all of the tables and indexes from an Online Transaction Processing (OLTP) database to a Data Warehouse (DW). However, in many cases, the OLTP database might be using a small block size, such as 2KB or 4KB, whereas the DW would be using a much larger one (8KB or 16KB). Without support for multiple block sizes in a single database, you would not be able to transport this information. Tablespaces with multiple block sizes should be used to facilitate transporting tablespaces and are not generally used for anything else.
There will be the database default block size, which is the size that was specified in the initialization file during the CREATE DATABASE command. The SYSTEM tablespace will have this default block size always, but you can then create other tablespaces with nondefault block sizes of 2KB, 4KB, 8KB, 16KB and, depending on the operating system, 32KB. The total number of block sizes is six if and only if you specified a nonstandard block size (not a power of two) during database creation. Hence, for all practical purposes, a database will have at most five block sizes: the default size and then four other nondefault sizes.
Any given tablespace will have a consistent block size, meaning that every block in that tablespace will be the same size. A multisegment object, such as a table with a LOB column, may have each segment in a tablespace with a different block size, but any given segment (which is contained in a tablespace) will consist of blocks of exactly the same size. All blocks, regardless of their size, have the same general format, which looks something like Figure 3-2.
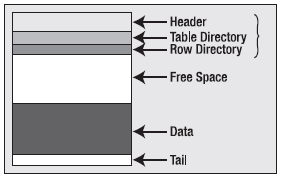
Figure 3-2. The structure of a block
The block header contains information about the type of block (table block, index block, and so on), transaction information when relevant (only blocks that are transaction managed have this information — a temporary sort block would not, for example) regarding active and past transactions on the block, and the address (location) of the block on the disk. The next two block components, table directory and row directiry, are found on the most common types of database blocks, those of HEAP organized tables. We’ll cover database table types in much more detail in Chapter 10, but suffice it to say that most tables are of this type. The table directory, if present, contains information about the tables that store rows in this block (data from more than one table may be stored on the same block). The row directory contains information describing the rows that are to be found on the block. This is an array of pointers to where the rows are to be found in the data portion of the block. These three pieces of the block are collectively known as the block overhead, which is space used on the block that is not available for your data, but rather is used by Oracle to manage the block itself. The remaining two pieces of the block are straightforward: there will possibly be free space on a block, and then there will generally be used space that is currently storing data.
Now that you have a cursory understanding of segments, which consist of extents, which consist of blocks, let’s take a closer look at tablespaces and then at exactly how files fit into the big picture.
Tablespaces
As noted earlier, a tablespace is a container — it holds segments. Each and every segment belongs to exactly one tablespace. A tablespace may have many segments within it. All of the extents for a given segment will be found in the tablespace associated with that segment. Segments never cross tablespace boundaries. A tablespace itself has one or more data files associated with it. An extent for any given segment in a tablespace will be contained entirely within one data file. However, a segment may have extents from many different data files. Graphically, a tablespace might look like Figure 3-3.
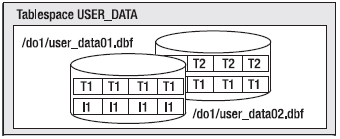
Figure 3-3. A tablespace containing two data files, three segments, and four extents
Figure 3-3 shows a tablespace named USER_DATA. It consists of two data files, user_data01 and user_data02. It has three segments allocated it: T1, T2, and I1 (probably two tables and an index). The tablespace has four extents allocated in it, and each extent is depicted as a logically contiguous set of database blocks. Segment T1 consists of two extents, one extent in each file. Segments T2 and I1 each have one extent depicted. If we need more space in this tablespace, we could either resize the data files already allocated to the tablespace or we could add a third data file to it.
Tablespaces are a logical storage container in Oracle. As developers, we will create segments in tablespaces. We will never get down to the raw “file level” — we do not specify that we want our extents to be allocated in a specific file (we can, but we do not in general). Rather, we create objects in tablespaces, and Oracle takes care of the rest. If at some point in the future, the DBA decides to move our data files around on disk to more evenly distribute I/O, that is OK with us. It will not affect our processing at all.
Storage Hierarchy Summary
In summary, the hierarchy of storage in Oracle is as follows:
- A database is made up of one or more tablespaces.
- A tablespace is made up of one or more data files. These files might be cooked files in a file system, raw partitions, ASM managed database files, or a file on a clustered file system. A tablespace contains segments.
- A segment (TABLE, INDEX, and so on) is made up of one or more extents. A segment exists in a tablespace, but may have data in many data files within that tablespace.
- An extent is a logically contiguous set of blocks on disk. An extent is in a single tablespace and, furthermore, is always in a single file within that tablespace.
- A block is the smallest unit of allocation in the database. A block is the smallest unit of I/O used by a database.
Dictionary-Managed and Locally-Managed Tablespaces
Before we move on, we will look at one more topic related to tablespaces: how extents are managed in a tablespace. Prior to Oracle 8.1.5, there was only one method to manage the allocation of extents within a tablespace: a dictionary-managed tablespace. That is, the space within a tablespace was managed in data dictionary tables, in much the same way you would manage accounting data, perhaps with a DEBIT and CREDIT table. On the debit side, we have all of the extents allocated to objects. On the credit side, we have all of the free extents available for use. When an object needed another extent, it would ask the system to get one. Oracle would then go to its data dictionary tables, run some queries, find the space (or not), and then update a row in one table (or remove it all together) and insert a row into another. Oracle managed space in very much the same way you will write your applications: by modifying data and moving it around.
This SQL, executed on your behalf in the background to get the additional space, is referred to as recursive SQL. Your SQL INSERT statement caused other recursive SQL to be executed to get more space. This recursive SQL can be quite expensive if it is done frequently. Such updates to the data dictionary must be serialized; they cannot be done simultaneously. They are something to be avoided.
In earlier releases of Oracle, we would see this space management issue — this recursive SQL overhead — most often occurring in temporary tablespaces (this was before the introduction of “real” temporary tablespaces created via the CREATE TEMPORARY TABLESPACE command). Space would frequently be allocated (we would have to delete from one dictionary table and insert into another) and de-allocated (we would put the rows we just moved back where they were initially). These operations would tend to serialize, dramatically decreasing concurrency and increasing wait times. In version 7.3, Oracle introduced the concept of a true temporary tablespace, a new tablespace type dedicated to just storing temporary data, to help alleviate this issue. Prior to this special tablespace type, temporary data was managed in the same tablespaces as persistent data and treated in much the same way as permanent data was.
A temporary tablespace was one in which you could create no permanent objects of your own. This was fundamentally the only difference; the space was still managed in the data dictionary tables. However, once an extent was allocated in a temporary tablespace, the system would hold on to it (i.e., it would not give the space back). The next time someone requested space in the temporary tablespace for any purpose, Oracle would look for an already allocated extent in its internal list of allocated extents. If it found one there, it would simply reuse it, or else it would allocate one the old-fashioned way. In this manner, once the database had been up and running for a while, the temporary segment would appear full but would actually just be “allocated.” The free extents were all there; they were just being managed differently. When someone needed temporary space, Oracle would look for that space in an in-memory data structure, instead of executing expensive, recursive SQL.
In Oracle 8.1.5 and later, Oracle goes a step further in reducing this space management overhead. It introduced the concept of a locally-managed tablespace as opposed to a dictionary-managed one. Local management of space effectively did for all tablespaces what Oracle 7.3 did for temporary tablespaces: it removed the need to use the data dictionary to manage space in a tablespace. With a locally-managed tablespace, a bitmap stored in each data file is used to manage the extents. Now to get an extent, all the system needs to do is set a bit to 1 in the bitmap. To free space, the system sets a bit back to 0. Compared to using dictionarymanaged tablespaces, this is incredibly fast. We no longer serialize for a long-running operation at the database level for space requests across all tablespaces. Rather, we serialize at the tablespace level for a very fast operation. Locally-managed tablespaces have other nice attributes as well, such as the enforcement of a uniform extent size, but that is starting to get heavily into the role of the DBA.
Going forward, the only storage management method you should be using is a locallymanaged tablespace. In fact, in Oracle9i and above, if you create a database using the database configuration assistant (DBCA), it will create SYSTEM as a locally-managed tablespace, and if SYSTEM is locally managed, all other tablespaces in that database will be locally managed as well, and the legacy dictionary-managed method will not work. It is not that dictionarymanaged tablespaces are not supported in a database where SYSTEM is locally managed, it is that they simply cannot be created:
ops$tkyte@ORA10G> create tablespace dmt
2 datafile '/tmp/dmt.dbf' size 2m
3 extent management dictionary;
create tablespace dmt
*
ERROR at line 1:
ORA-12913: Cannot create dictionary managed tablespace
ops$tkyte@ORA10G> !oerr ora 12913
12913, 00000, "Cannot create dictionary managed tablespace"
// *Cause: Attempt to create dictionary managed tablespace in database
// which has system tablespace as locally managed
// *Action: Create a locally managed tablespace.
This is a positive side effect, as it prohibits you from using the legacy storage mechanism, which was less efficient and dangerously prone to fragmentation. Locally-managed tablespaces, in addition to being more efficient in space allocation and de-allocation, also prevent tablespace fragmentation from occurring. This is a side effect of the way space is allocated and managed in locally-managed tablespaces. We’ll take an in-depth look at this in Chapter 10.
--
Thomas Kyte is the Vice President of the Core Technologies Group at Oracle Corporation and has been with them since version 7.0.9 was released in 1993. Kyte, however, has been working with Oracle since version 5.1.5c. At Oracle Corp., Kyte works with the Oracle database, and more specifically, he helps clients who are using the Oracle database and works directly with them specifying and building their systems or rebuilding and tuning them. Prior to working at Oracle, Kyte was a systems integrator who built large scale, heterogeneous databases and applications for military and government clients. Tom Kyte is the same “Ask Tom” whose column appears in Oracle Magazine, where he answers questions about the Oracle database and tools that developers and DBAs struggle with every day.
Contributors : Tom Kyte
Last modified 2006-01-20 01:03 PM