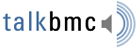Oracle Database 10g OLAP Performance Tips & Techniques - Part 2
Part 1 | Part 2
Related Podcast: Mark Rittman - Oracle Openworld in Retrospect
Introduction
The OLAP Option to Oracle 10g gives you the ability to store multidimensional cubes of data in your Oracle database, and perform OLAP queries on them using OLAP DML, regular SQL or query tools such as Oracle Discoverer Plus OLAP.
In part 1 of this article, you learned tips and best practices for designing Oracle OLAP cubes. Part 2 covers loading, aggregating, and querying Oracle OLAP cubes and takes a look at some of the new features coming with 10g Release 2.
Loading and Aggregating Data
Once you have defined your Analytic Workspace, allocated storage and set initialisation parameters appropriately, you will want to load data from your source tables and (optionally) pre-aggregate your cubes.
Using Analytic Workspace Manager 10g, you can easily define how data in database tables and columns maps to measures and dimensions within your analytic workspace (Figure 2). Users of Oracle Warehouse Builder will recognise the approach that Analytic Workspace Manager takes to mapping source data to targets, although it should be noted that you can only load data directly from source to target using this feature, and any data cleansing or transformation will need to take place prior to using Analytic Workspace Manager.
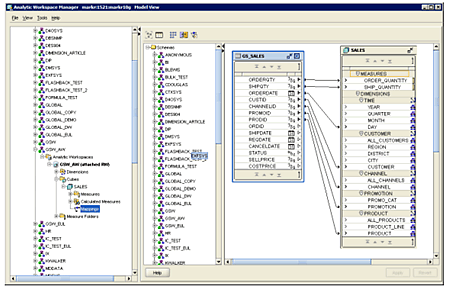
Figure 2: Mapping source data to analytic workspace objects using AWM10g.
When you load data into your cube and then pre-aggregate it, there are several aspects that you need to consider:
- The degree to which you pre-aggregate your cube.
- Use of calculations and formulas to create “dynamic” measures and dimension members.
- Loading new or changed data into an existing cube.
Pre-aggregating cubes
When you load data into the measures in your cube, you generally load in values at the lowest level of aggregation for the measure. If a user then queries the measure at a higher level of aggregation, by default Oracle OLAP will calculate the summarised data “on the fly,” just as regular SQL statements calculate SUMs and AVGs in response to a SELECT statement. But, in the same way that with regular relational data you can pre-aggregate queries using materialized views and query rewrite, you can pre-aggregate data in your cube to improve query response times. Indeed, because pre-summarisation and summary awareness is built-in to the OLAP engine, it works more reliably and with less initial setup that relational summaries created using materialized views, and the tools required to create cube summaries are built right in to Analytic Workspace Manager 10g.
From a performance perspective though, the question that you need to ask yourself is to what extent you should pre-aggregate your data? Should you always presummarise the entire cube, across all levels in all hierarchies, or should you selectively summarise your cube (referred to as “skip-level aggregation”) to balance out preparation time with improvements to query performance? Or is it better to let the OLAP engine generate summaries on the fly?
In general, it is recommended that you pre-aggregate data when there are ten or more child dimension members for a parent dimension member, and you should also select pre-summarisation for all of the bottom levels in a dimension hieararchy. So, to take the Time dimension for the Global Widgets cube, it would make sense to presummarise the day and month levels as 2926 days roll up to 96 months, but there would be little benefit in presummarising levels above those as there would be little benefit in calculating summaries in advance compared to generating them on the fly. With the other dimensions, none of them have a 10:1 children to parent ratio, and therefore you could decide to pre-aggregate just the bottom level in each hierarchy and leave it at that.
If you are using compression to reduce the size of your cube, you should experiment with leaving the topmost level in some dimension hierarchies as unsummarised, as this can decrease the time required to maintain the cube at the cost of slightly slower queries, due to the way that the compression algorithm works.
Of course, the cost of pre-aggregating data is the additional time, and space, that this part of the load process will take up, and therefore a test was carried out using the Global Widgets sample data to see how much additional time and space pre-summarisation took up.
For the purposes of this test, the three versions of the Global Widgets cube (dense, sparse and compressed) were loaded first using skip-level aggregation, and then using full pre-aggregation. The results of the test were as follows:
| Cube Description | Initial Cube Size (bytes) | Aggregation Strategy | Final Cube Size | Maintainance Time |
| Dense | 20.289 Mb | Skip-level | 149.1 Mb | 3 mins 27 secs |
| Full | 1.385 Gb | 46 mins 11 secs | ||
| Sparse | 22.029 Mb | Skip-level | 132.1 Mb | 1 min 55 secs |
| Full | 1.074 Gb | 16 mins 55 secs | ||
| Compressed | 21.021 Mb | Skip-level | 214.1 Mb | 2 mins 36 secs |
| Full | 422.1 Mb | 2 mins 48 secs |
From these results, the following observations were made:
- The slowest way to load and maintain a cube is to define all dimensions as dense, and fully aggregate the cube.
- The fastest way to load and maintain a cube is to define all dimensions except Time as sparse, and partially (skip-level) pre-aggregate the cube.
- The biggest impact on maintenance time for dense or sparse cubes is whether or not you partially or fully aggregate the cube, with full pre-aggregation increasing maintenance time by a factor of 15.
- If you move from a dense cube to a sparse cube, this reduces maintenance time by a factor of three.
- For dense and sparse cube, pre-aggregating the cube increases the size of the cube by a factor of five.
- If you can make use of the compression feature, you can fully pre-aggregate a cube is only slightly more time than it takes to partially pre-aggregate a sparse or dense cube.
Note that these measurements are specific to the Global Widgets cube, and other cubes with differing or additional dimensions, measures, hierarchies and levels will produce different timings and differentials.
Calculations and formulas
One way of speeding up data loads and pre-aggregation is to not load the data in the first place. In the same way that with relational data, you can use functions and views to derive results from table columns, you can create calculations and formulas to dynamically generate measures or dimension members based on data you have loaded into your cube.
Calculations are something that you should already be familiar with, and are defined using the Calculated Measures feature using Analytic Workspace Manager 10g (Figure 3).
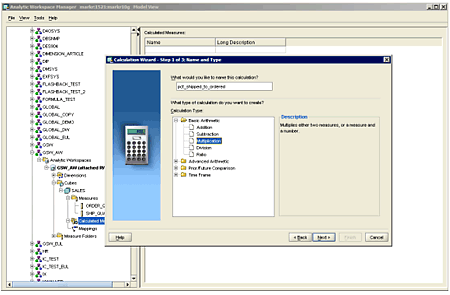
Figure 3: Creating a calculated measure using Analytic Workspace Manager 10g.
When you define a calculated measure, the value for this measure is calculated “on the fly” whenever the measure is requested, for all combinations of the measure’s dimensions. The advantage of defining a measure as a calculated measure is that it does not take up any storage space (except for the metadata associated with the calculation) and it does not require loading or pre-aggregating. The downside, of course, is that a calculated measure will usually be (slightly) slower to query than a measure that has been fully loaded and aggregated.
Previous users of Oracle Express Server will recognise calculated measures as a type of Express construct known as a formula. Formulas are very flexible objects and are also fully supported in Oracle OLAP, but they are only exposed in a very limited way with Analytic Workspace Manager 10g. If you are prepared to leave the user-friendliness of Analytic Workspace Manager 10g and use the command line and AW/XML, the XML API for directly defining analytic workspace objects, you can create formulas that insert additional members into dimensions, create new measures based on more than two other measures, and create new dynamic cubes based on measures and dimensions from other cubes, and then make them fully available for use using tools such as Analytic Workspace Manager, Discoverer for OLAP and BI Beans. For more details on creating formulas using AW/XML, see the previous OraFAQ article that looks into this technique.
Loading new and changed data
The first load of data will usually take all current and historic data and load it into your Analytic Workspace. After that, you will usually want to load just new data, and data that has changed, into your Analytic Workspace rather than delete the cube and rebuild it from scratch. To use this approach, you will need to carry out the following steps.
- Map your initial source data tables to the measures and dimensions in your analytic workspace.
- Maintain your cube, using the “Aggregate the full cube” setting in Analytic Workspace Manager 10g.
- Change your dimension and measure mappings to point to tables containing new and changed data.
- Maintain your cube using the “Aggregate the cube for only the incoming data values” option (Figure 4).
Figure 4: Selecting the cube processing option using Analytic Workspace Manager 10g.
As an alternative to remapping your dimension and cube loads to point to tables that only contain new and changed data, another technique that has been used successfully in the past is to do the following:
- Add an additional column to the source tables that contains a “Data Loaded YN” flag.
- Create a view over this table that only returns those rows where the “Data Loaded YN” flag is set to “N.”
- Use this view, rather than the underlying table, as the data source for the analytic workspace mapping.
- After the load has completed, update the underlying table setting the “Data Loaded YN” flag to “Y.”
In addition to setting the cube processing options, you will also want to check the “Delete all attribute values of the selected dimensions” and the “Delete all members of the selected dimension” checkboxes if you need to delete dimensions and attribute values in the analytic workspace that no longer exist in the source data.
Using the Global Widgets dataset, timings were taken using the sparse version of the cube, using the following scenarios:
- Initial load of 8884 rows from the GS_SALES table, followed by a subsequent load of 2545 rows, with “Aggregate the full cube” as the selected cube processing option.
- Initial load of 8884 rows with “Aggregate the full cube” selected, then a further load of 11429 rows (2545 of which were new) with “Aggregate the cube for only the incoming values” option selected.
- Initial load of 8884 rows with “Aggregate the full cube” selected, then a further load of 2545 rows with “Aggregate the cube for only the incoming values” option selected.
The results of the test were as follows:
| Scenario # | Load Type | Rows | Cube Processing Option | Time to maintain | Size of cube |
| 1 | Initial | 8884 | Agg. Full cube | 13 mins 34 secs | 936 Mb |
| Subsequent | 2545 | Agg. Full cube | 20 mins 12 secs | 1.87 Gb | |
| 2 | Initial | 8884 | Agg. Full cube | 11 mins 50 secs | 936 Mb |
| Subsequent | 11429 | Agg. New vals | 21 mins 00 secs | 1.87 Gb | |
| 3 | Initial | 8884 | Agg. Full cube | 12 mins 50 secs | 936 Mb |
| Subsequent | 2545 | Agg. New vals | 19 mins 35 secs | 1.82 Gb |
The obvious conclusion from these tests was surprising and shows that, regardless of whether you load just the new and changed data into the cube or load all data, or whether you choose to aggregate just the new values or all values, with Oracle Database 10g Release 1 there is no difference in the time taken to perform cube maintenance. It is, however, my understanding that this issue is, in fact, being addressed in Oracle Database 10g Release 2, and incremental loads will be significantly faster with this release.
Monitoring and tracing the load process
Most DBAs working with Oracle OLAP will use Analytic Workspace Manager 10g to create their cube maintenance plans, and then either run it then or schedule it to run later. It is however possible to output these maintenance plans to an SQL text file, then use SQL*Plus to run the plan, take timings, and otherwise trace and monitor the load.
To illustrate how this works, the template for the sparse version of the cube was loaded into Analytic Workspace Manager 10g, and the option to maintain the cube was selected. To generate the SQL text file, check the “Save Maintenance task to script” checkbox (Figure 5).
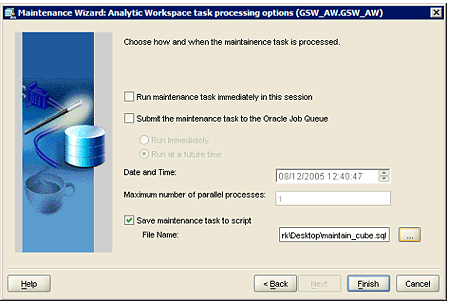
Figure 5: Saving a maintenance task to script using Analytic Workspace Manager 10g.
As this is nothing more than an SQL script containing an anonymous PL/SQL block, you can cut and paste it into SQL*Plus after having SET TIMING ON, and by this method obtain precise timings on how long a maintenance task took to run. Ensure that you have detached your cube using Analytic Workspace Manager 10g before you run this maintenance task, as the script will, first of all, try to attach the cube in read/write mode and will fail if AWM10g is similarly attached.
SQL> set timing on
SQL> declare
2 xml_clob clob;
3 xml_str varchar2(4000);
4 isAW number;
5 begin
6 DBMS_AW.EXECUTE('AW ATTACH GSW_AW RW');
7 DBMS_LOB.CREATETEMPORARY(xml_clob,TRUE);
8 dbms_lob.open(xml_clob, DBMS_LOB.LOB_READWRITE);
9 dbms_lob.writeappend(xml_clob, 185, ' <BuildDatabase
Id="Action2" AWName="GSW_AW.GSW_AW" Buil
dType="EXECUTE" RunSolve="true" CleanMeasures="false"
CleanAttrs="false" CleanDim="false" TrackStatu
s="false" MaxJobQueues="0">');
10 dbms_lob.writeappend(xml_clob, 46, ' <BuildList
XMLIDref="CHANNEL.DIMENSION" />');
11 dbms_lob.writeappend(xml_clob, 46, ' <BuildList
XMLIDref="PRODUCT.DIMENSION" />');
12 dbms_lob.writeappend(xml_clob, 43, ' <BuildList
XMLIDref="TIME.DIMENSION" />');
13 dbms_lob.writeappend(xml_clob, 47, ' <BuildList
XMLIDref="CUSTOMER.DIMENSION" />');
14 dbms_lob.writeappend(xml_clob, 48, ' <BuildList
XMLIDref="PROMOTION.DIMENSION" />');
15 dbms_lob.writeappend(xml_clob, 57, ' <BuildList
XMLIDref="SALES.ORDER_QUANTITY.MEASURE" />')
;
16 dbms_lob.writeappend(xml_clob, 56, ' <BuildList
XMLIDref="SALES.SHIP_QUANTITY.MEASURE" />');
17 dbms_lob.writeappend(xml_clob, 18, ' </BuildDatabase>');
18 dbms_lob.close(xml_clob);
19 xml_str := sys.interactionExecute(xml_clob);
20 dbms_output.put_line(xml_str);
21 end;
22 /
PL/SQL procedure successfully completed.
Elapsed: 00:14:20.39
SQL>
Whilst the script is running, you can open another SQL*Plus session and query the OLAPSYS.xml_load_log table to check the progress of the load. This is the log that Analytic Workspace Manager displays after a load has completed, but by querying this table, you can check the progress of the load whilst it is running.
SQL> set pagesize 400
SQL> set linesize 400
SQL> column xml_message format a120
SQL> select xml_loadid, xml_recordid, xml_date, xml_message
2 from OLAPSYS.xml_load_log
3 where xml_loadid = (select max(xml_loadid) from
4 OLAPSYS.xml_load_log where xml_aw='GSW_AW.GSW_AW');
XML_LOADID XML_RECORDID XML_DATE XML_MESSAGE
---------- ------------ --------- -------------------------------
-----------------------------------
372 1 12-AUG-05 14:08:42 Started Build(Refresh)
of GSW_AW.GSW_AW Analytic Workspace.
372 2 12-AUG-05 14:08:42 Attached AW
GSW_AW.GSW_AW in RW Mode.
372 3 12-AUG-05 14:08:42 Started Loading
Dimensions.
372 4 12-AUG-05 14:08:43 Started Loading
Dimension Members.
372 5 12-AUG-05 14:08:43 Started Loading
Dimension Members for CHANNEL.DIMENSION (1 ou
372 6 12-AUG-05 14:08:43 Finished Loading
Members for CHANNEL.DIMENSION. Added: 0. No
372 7 12-AUG-05 14:08:43 Started Loading
Dimension Members for CUSTOMER.DIMENSION (2 o
372 8 12-AUG-05 14:08:44 Finished Loading
Members for CUSTOMER.DIMENSION. Added: 0. No
372 9 12-AUG-05 14:08:44 Started Loading
Dimension Members for PRODUCT.DIMENSION (3 ou
372 10 12-AUG-05 14:08:45 Finished Loading
Members for PRODUCT.DIMENSION. Added: 0. No
372 11 12-AUG-05 14:08:45 Started Loading
Dimension Members for PROMOTION.DIMENSION (4
372 12 12-AUG-05 14:08:45 Finished Loading
Members for PROMOTION.DIMENSION. Added: 0. N
372 13 12-AUG-05 14:08:45 Started Loading
Dimension Members for TIME.DIMENSION (5 out o
372 14 12-AUG-05 14:08:46 Finished Loading
Members for TIME.DIMENSION. Added: 0. No Lon
372 15 12-AUG-05 14:08:46 Finished Loading
Dimension Members.
372 16 12-AUG-05 14:08:46 Started Loading
Hierarchies.
372 17 12-AUG-05 14:08:46 Started Loading
Hierarchies for CHANNEL.DIMENSION (1 out of 5)
17 rows selected.
SQL>
You can also determine the disk space taken up by a cube by using the DBMS_LOB.GETLENGTH() built-in function, like this:
SQL> SELECT sum(DBMS_LOB.GETLENGTH(AWLOB)) AW_SIZE
2 FROM AW$GSW_AW;
AW_SIZE
----------
1039424108
As an alternative to embedding the AWXML definitions within calls to DBMS_LOB, you can also save the XML to a file and load it in to the database as a CLOB. Oracle Database 10gR2 comes with a new procedure, DBMS_AW_XML.EXECUTEFILE, that can be used to load and process AWXML templates, and another, DBMS_AW_XML.EXECUTE that should be used instead of SYS.INTERACTIONEXECUTE.
Other cube maintenance tips
Other tips for improving the performance of cube loads and aggregations include:
- Order the data in your source tables to match the order in which dimensions are listed in your cube (mentioned earlier).
- Use the External Table feature to load data directly from flat files. External tables can also take advantage of parallelism to break large files into smaller ones and distribute them over multiple processors.
- When writing OLAP DML routines to load data into an analytic workspace, use the SQL IMPORT DIRECT command in preference to SQL FETCH, as this can be up to 53 times faster.
Additional tips provided by Anthony Waite of Oracle on the OTN OLAP Forum (with amendments from Oracle development) include:
- Turn off LOGGING (REDO) during builds to improve data insertion performance.
- Turn Logging off prior to commencing build.
- Turn Logging on after build completes.
- Increase REDO Log size and log_buffer parameter to reduce log switch waits and improve overall time.
- Move TEMP, UNDO and REDO Logs to fastest disks to improve overall build performance.
- Use AW TRUNCATE instead of AW DELETE if you wish to keep the analytic workspace name. Performs better with less overhead [and preserves grants on the analytic workspace].
Disable Logging during build to improve overall load performance. Once load is complete turn it on.
If you choose to set NOLOGGING for the LOB segment (of the AW$ table containing your Analytic Workspace) check out MetaLink 1058851.6 for information pertaining to event 10359 which can reduce I/O for frequently updated NOLOGGING LOBs. http://metalink.oracle.com/metalink/plsql/ml2_documents.showDocument?p_database_id=NOT&p_id=1058851.6
ALTER TABLE GLOBAL.AW$GLOBAL MODIFY LOB (awlob) NOLOGGING;
ALTER TABLE GLOBAL.AW$GLOBAL MODIFY LOB (awlob) LOGGING;
Ask the DBA to increase this to somewhere between 100M and 500M from the default of 10M. Use ADDM to determine the ideal size. This could be crucial for poorly performing disk subsystems.
Ask the DBA to place TEMP, UNDO and REDO Logs on fastest disks. No RAID5. Use RAW whenever possible and consider RAID10 or 0+1. RAID 5 can severely affect performance on highly updated databases.
EXEC DBMS_AW.EXECUTE('AW TRUNCATE SCOTT.EMPAW');
Optimising Query Performance
Once you have loaded and aggregated your cube, the next area that you will want to optimise is the performance of your queries. What this means in practice is that you will need to look at the following two areas:
- The performance of the query tool, and
- The performance of the OLAP cube.
Query tool performance
Query tools such as OracleBI Discoverer Plus OLAP, Oracle Business Intelligence Beans and the OracleBI Spreadsheet Add-in are built using Java and the Java OLAP API. The tools generate calls to the OLAP API, which then generates SQL statements that use the OLAP_TABLE function to return data from the analytic workspace. Because the OLAP API accesses the analytic workspace through this intermediate SQL and OLAP_TABLE layer, this introduces (at least with Oracle 9i and Oracle 10g Release 1) a query lag that would not exist if you were directly querying the analytic workspace using OLAP DML.
In practice, this means that with current (10g Release 1) versions of Oracle OLAP, tools such as Discoverer for OLAP will be slower to produce query results than you would have expected, given the fact that you have pre-summarised data and you are working with an OLAP-aware query tool. There is not much you can do about this at the moment, although Release 2 of Oracle Database 10g promises optimisations to this interface layer.
Users of OracleBI Spreadsheet Add-in 10.1.2 will also sometimes suffer additional performance problems due to the Spreadsheet Add-in’s need to retrieve all of the OLAP query results when the query first runs, as opposed to Discoverer Plus OLAP and BI Beans which can retrieve the first part of a query and display it, and fetch the rest of the results afterwards.
If you want to look closer at what SQL is being generated by OLAP API tools, you can enable SQL trace and set the _olap_continuous_trace_file database parameter to include SQL generated by the OLAP API:
To set SQL and OLAP API tracing across the database, you can issue the following commands from the SQL*Plus prompt:
SQL> alter system set sql_trace = true scope = spfile;
System altered.
Elapsed: 00:00:00.13
SQL> alter system set "_olap_continuous_trace_file" = true scope
= spfile;
System altered.
Elapsed: 00:00:00.11
SQL> shutdown immediate;
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> startup
ORACLE instance started.
Total System Global Area 1073741824 bytes
Fixed Size 792660 bytes
Variable Size 279963564 bytes
Database Buffers 792723456 bytes
Redo Buffers 262144 bytes
Database mounted.
Database opened.
An OLAP API application - the OracleBI Spreadsheet Add-in, in this instance - can then be run, and the SQL emitted by the application, and the OLAP API, will then be captured in a trace file in the UDUMP directory.
The trace file will contain all of the SQL generated by the application, and will typically contain a large number of SQL statements, some of which will be the SQL issued by the OLAP API to retrieve data from the analytic workspace in response to an OLAP query, such as the following:
=====================
PARSING IN CURSOR #42 len=2389 dep=1 uid=118 oct=3 lid=118
tim=1305539325657 hv=4029820088 ad='4a73e080'
SELECT /*+ bypass_recursive_check INDEX_COMBINE(V43) */
ALIAS_211 ALIAS_R93,
ALIAS_200 D29_T2_ET_COL_21,
ALIAS_201 D29_ALIAS_R94,
ALIAS_202 D29_T2_GID_COL_23,
CAST (NULL AS VARCHAR2(100) ) D29_T2_LEVEL_37,
CAST (NULL AS VARCHAR2(100) ) D29_T2_LEVEL_36,
CAST (NULL AS VARCHAR2(100) ) D29_T2_LEVEL_35,
CAST (NULL AS VARCHAR2(100) ) D29_T2_LEVEL_34,
ALIAS_203 D31_T1_ET_COL_39,
ALIAS_201 D31_ALIAS_R100,
ALIAS_204 D31_T1_GID_COL_41,
CAST (NULL AS VARCHAR2(100) ) D31_T1_LEVEL_53,
CAST (NULL AS VARCHAR2(100) ) D31_T1_LEVEL_52,
CAST (NULL AS VARCHAR2(100) ) D31_T1_LEVEL_51,
CAST (NULL AS VARCHAR2(100) ) D31_T1_LEVEL_50,
CAST (NULL AS VARCHAR2(100) ) D31_T1_LEVEL_49
FROM
(
SELECT
ALIAS_198 ALIAS_200,
0 ALIAS_201,
ALIAS_189 ALIAS_202,
ALIAS_190 ALIAS_203,
ALIAS_191 ALIAS_204,
ALIAS_192 ALIAS_205,
ALIAS_193 ALIAS_206,
ALIAS_194 ALIAS_207,
ALIAS_195 ALIAS_208,
ALIAS_196 ALIAS_209,
ALIAS_197 ALIAS_210,
ALIAS_187 ALIAS_211
FROM
(
SELECT
T42.MEASURE_63 ALIAS_187,
T42.ET_COL_21 ALIAS_198,
T42.GID_COL_23 ALIAS_189,
T42.ET_COL_39 ALIAS_190,
T42.GID_COL_41 ALIAS_191,
T42.ET_COL_1 ALIAS_192,
T42.GID_COL_3 ALIAS_193,
T42.ET_COL_54 ALIAS_194,
T42.GID_COL_56 ALIAS_195,
T42.ET_COL_9 ALIAS_196,
T42.GID_COL_11 ALIAS_197
FROM
(SELECT * FROM TABLE(OLAP_TABLE('GSW_AW.GSW_AW duration session',
'', '', '&(lmgen(''GSW_AW.GSW_AW'',
''C::GSW_AW.SALES:TIME;FINANCIAL_YEAR:CUSTOMER;CUSTOMER_HIERARCHY:CHANN
EL;CHANNEL_HIERARCHY:PROMOTION;PROMO_H:PRODUCT;PRODUCT_HIERARCHY'',
''T42_8''))')) SQL MODEL DIMENSION BY(ET_COL_21, GID_COL_23, ET_COL_39,
GID_COL_41, ET_COL_1, GID_COL_3, ET_COL_54, GID_COL_56, ET_COL_9,
GID_COL_11) MEASURES(MEASURE_63, R2C) UNIQUE SINGLE REFERENCE RULES
UPDATE SEQUENTIAL ORDER ()) T42 )
V43
WHERE
((ALIAS_189 = 7)
AND (ALIAS_191 = 15) ) )
V39
WHERE
((ALIAS_205 = 'ALL_CHANNELS_ALL CHANNELS')
AND (ALIAS_207 = 'PROMO_CAT_1')
AND (ALIAS_209 = 'ALL_PRODUCTS_ALL PRODUCTS')
AND ((ALIAS_203) IN (('ALL_CUSTOMERS_ALL CUSTOMERS') ) )
AND ((ALIAS_200) IN (('YEAR_FY1998') , ('YEAR_FY1999') ,
('YEAR_FY2000') , ('YEAR_FY2001') , ('YEAR_FY2002') , ('YEAR_FY2003') ,
('YEAR_FY2004') , ('YEAR_FY2005') ) ) )
END OF STMT
PARSE #42:c=180259,e=289997,p=2,cr=668,cu=423,mis=1,r=0,dep=1,og=1,tim=130553
9325652
EXEC #42:c=0,e=95,p=0,cr=0,cu=0,mis=0,r=0,dep=1,og=1,tim=1305539334787
EXEC #20:c=0,e=84,p=0,cr=0,cu=0,mis=0,r=0,dep=3,og=4,tim=1305539337802
FETCH #20:c=0,e=81,p=0,cr=4,cu=0,mis=0,r=1,dep=3,og=4,tim=1305539338353
=====================
Note, in particular, the
FROM
(SELECT * FROM TABLE(OLAP_TABLE('GSW_AW.GSW_AW duration
session', '', '', '&(lmgen(''GSW_AW.GSW_AW'',
''C::GSW_AW.SALES:TIME;FINANCIAL_YEAR:CUSTOMER;CUSTOMER_HIERARCHY
:CHANNEL;CHANNEL_HIERARCHY:PROMOTION;PROMO_H:PRODUCT;PRODUCT_HIER
ARCHY'', ''T42_8''))')) SQL MODEL DIMENSION BY(ET_COL_21,
GID_COL_23, ET_COL_39, GID_COL_41, ET_COL_1, GID_COL_3,
ET_COL_54, GID_COL_56, ET_COL_9, GID_COL_11) MEASURES(MEASURE_63,
R2C) UNIQUE SINGLE REFERENCE RULES UPDATE SEQUENTIAL ORDER ())
T42 )
V43
in the above trace file, which uses a combination of OLAP_TABLE and the SQL Model clause to retrieve and manipulate data from the analytic workspace. We will look in more detail at the use of the Model clause to boost performance later on in this section.
Once you have a trace file, containing the SQL generated by the OLAP API, you can format it using TKPROF to review the individual SQL statements, the explain plans, details of wait events, and profile the SQL in terms of total contribution to response time.
You can also generate a log file of the OLAP DML commands executed during an OLAP session by using the OLAP DML “debugoutfile” command. For example, in SQL*Plus, you could use the commands:
SQL> exec dbms_aw.execute('aw attach my_aw ro');
SQL> exec dbms_aw.execute('debugoutfile
my_diralias/my_filename.txt');
SQL> select . . . from view_using_olap_table where . .
SQL> exec dbms_aw.execute('dotf eof');
If you are using the OLAP Worksheet to directly enter OLAP DML, you could use the commands:
>aw attach my_aw ro
>debugoutfile my_diralias/my_filename.txt
>call 'dml program'
>dotf eof
OLAP cube performance
The two biggest contributors to the performance of your OLAP cube are the design of your cube (the order of dimensions, how you handle sparsity, to what extent you pre-aggregate data) and the resources you make available to the OLAP engine.
The section on cube design earlier on in this article went through the optimal design of a cube, and how you may find a conflict between optimising for loading and aggregation, and optimising for querying. From a querying perspective, your first named dimension should be the fastest varying, and if you are doing lots of time-series analysis your first dimension should probably be your time dimension. Make sure, also, that you have not declared dimensions as being sparse when they are in fact dense, as the “unravelling” of the resulting composite can add to the time needed to retrieve data.
One aspect of cube design that can significantly improve performance is partitioning. With Oracle Database 10g, cubes are created by default with eight logical partitions, although you may wish to increase this with large datasets or where you have lots of concurrent access, by selecting the “partition cube” option on the Implementation Details tab of the Create Cube dialog in Analytic Workspace Manager which will allow you to partition your cube based on the members in a level in a selected dimension hierarchy.
In addition to these logical partitions, if you have licensed and installed the Partioning Option, you may wish to add physical partitions to your analytic workspaces which can help UPDATE performance by reducing LOB contention. By default, if the Partitioning Option is enabled, Analytic Workspaces in Oracle Database 10g have eight physical partitions, but you can increase this number at the time you first create the analytic workspace:
SQL> exec dbms_aw.execute('aw create gsw_aw.orders_aw partitions
60');
If you are planning to have lots of users concurrently accessing your cube, you should plan for this in the same way as for any Oracle application; if you want to support high amounts of concurrent users, you should either use a server with multiple CPUs or use Real Application Clusters to spread the load over multiple “commodity” servers, and you should always ensure that you have lots of available RAM as Oracle OLAP will attempt to cache popular queries to improve query response time.
Oracle DBAs who are familiar with database performance tuning will no doubt be aware of the fixed V$ views that expose some of the internal performance counters and instrumentation within the database. A number of V$ views are available for use with the OLAP engine and these can be used to gain an insight into how optimally your cubes are performing.
V$AW_CALC reports on the effectiveness of the caches used by Oracle OLAP. Caches are there to provide fast response to regularly requested data, and (with the usual provisos about not requesting data that isn’t, in fact, necessary) an ineffective cache usually points to the fact that data isn’t being stored optimally for the way it is being queried, and you should look to reorder the list of dimensions for the cube.
The V$AW_CALC view has the following structure:
SQL> desc v$aw_calc;
Name Null? Type
------------------------------------- -------- -----------------
SESSION_ID NUMBER
AGGREGATE_CACHE_HITS NUMBER
AGGREGATE_CACHE_MISSES NUMBER
SESSION_CACHE_HITS NUMBER
SESSION_CACHE_MISSES NUMBER
POOL_HITS NUMBER
POOL_MISSES NUMBER
POOL_NEW_PAGES NUMBER
POOL_RECLAIMED_PAGES NUMBER
CACHE_WRITES NUMBER
POOL_SIZE NUMBER
CURR_DML_COMMAND VARCHAR2(64)
PREV_DML_COMMAND VARCHAR2(64)
AGGR_FUNC_LOGICAL_NA NUMBER
AGGR_FUNC_PRECOMPUTE NUMBER
AGGR_FUNC_CALCS NUMBER
and the columns that you will normally need to monitor are POOL_HITS and POOL_MISSES, which represents the number of times data is found in the OLAP pool (sized using the OLAP_PAGE_POOL_SIZE parameter, which if set to 0 is managed using ASMM or if set to a positive value, is sized manually) and the number of times data is not found in the OLAP pool; a high ratio of misses to hits could indicate that your data is not grouped close enough together (your fastest varying dimension is not at the top of the dimension list) and additional pages of data then have to be retrieved into the cache.
Other V$ views that you might want to monitor include:
- V$AW_LONGOPS, which provides dynamic information (status, rows processed, start time) on cursors opened in OLAP DML.
- V$AW_SESSION_INFO, which provides dynamic statistics on the current OLAP sessions that are connected (current and previous OLAP DML statement, total transactions executed, average time for transaction and so on).
- V$AW_OLAP, which provides a record of active sessions and their use of analytic workspaces - the number of LOB reads, use of temporary segments, degree to which OLAP pool pages have been modified.
Finally, you will have noticed in one of the earlier SQL trace file outputs that the OLAP API sometimes uses the SQL Model clause to boost query performance. The SQL Model clause was introduced with Oracle Database 10g and is normally used to generate spreadsheet-like models from the output of SELECT statements, and works by generating in-memory hash tables to hold and process the model; the mechanism that builds, populates and then outputs data from these hash tables is however “OLAP-aware”, and when dealing with data sourced from an analytic workspace (using the OLAP_TABLE function) bypasses the normal object layer and returns results directly to the calling application. Small queries may show no improvement but if you are pumping tens of thousands of rows through OLAP_TABLE, SQL MODEL can provide a significant performance boost.
This performance optimisation is particularly welcome as the 10.1.0.4 and 10.1.0.5 releases of Oracle OLAP contain a bug that forces the OLAP_TABLE row buffer to be non-paged; this bug has been fixed in the 10.2 release of Oracle OLAP but these earlier releases try to retrieve all of the data from the OLAP_TABLE query before processing it, slowing down queries significantly and using up all of the available memory.
When used in a SELECT statement that uses OLAP_TABLE to query an Analytic Workspace, the MODEL clause has the following arguments (taken from the 10.1.0.4 OLAP Application Developers’ Guide):
- DIMENSION BY
- MEASURES
- RULES UPDATE SEQUENTIAL ORDER
This should specify the names of the embedded total dimension columns, as defined in the limit map. Any other columns in the DIMENSION BY list disables this optimization. A properly constructed SELECT statement still executes, but more slowly.
The measures, attributes and any other columns excluded from the DIMENSION BY list.
The RULES clause is required, but it should not include complex or inter-row calculations since they will slow the query. Any calculations specified in the RULES clause are performed by SQL.
UPDATE indicates that you are not adding any custom members in the DIMENSION BY clause. Be sure to include this keyword, because otherwise the SQL WHERE clauses for measures are discarded, which can significantly degrade performance.
SEQUENTIAL ORDER prevents Oracle from evaluating the rules to ascertain their dependencies.
Note that while the MODEL clause is used in relational queries for inter-row calculations, you should not use it for this purpose with OLAP_TABLE. For OLAP_TABLE, the MODEL clause is used only to optimize the query.
Conclusions
Oracle OLAP, though based on Express Server technology, is new as an option to the Oracle RDBMS and as time progresses techniques and approaches are being developed to optimise data loads, aggregation and user queries. Part 1 and 2 of this article set out some tips and best practices for designing your cube, loading and aggregating data, and optimising queries and the interface layer between your OLAP data and your chosen query tools. As adoption of Oracle OLAP continues, more techniques and best practices will be documented and I would be more than interested in hearing any feedback or approaches that readers have used.
--
Mark Rittman is a Certified Oracle Professional DBA and works for SolstonePlus as a consultant on Oracle BI and Data Warehousing projects. Mark also chairs the UK Oracle User Group BI & Reporting Tools SIG and is an Oracle ACE.
Mark would also like to thank Heiko Becker, Chris Chiappa, Jameson White and Anthony Waite for their contributions to and technical review of this article.
Contributors : Mark Rittman
Last modified 2005-10-25 04:37 PM