Introduction
I would describe myself as a fairly good tuner. Not because tuning ever
came easy to me, I have just spent a lot of time working with the optimizer.
I still have troubles rewriting complex SQL statements from time to time but
I will admit that 20 years of experience makes it easier on me than it used
to be.
One of the areas I am strong at is using the proper indexes to influence SQL statement access paths. We know that an index can influence the optimizer to change an access path from a tablescan to a table lookup using an index ROWID. But indexes can also influence the type of join used as well as the order of the tables being joined.
Let's take a look at the benefits virtual indexes have and we'll finish this blog by reviewing how indexes can affect simple access paths, join methods and join orders.
Virtual Indexes
I use virtual indexes in both 9i and 10G. I like them because I can quickly
do "what if" scenarios. I can create the index and present it to the
optimizer without waiting for the index to become populated and stored on disk.
This feature allows me to reduce the amount of time I spend tuning, which is
always a good thing.
I also use virtual indexes when I am training myself and others. Most production environments do have test counterparts, but there are times when I need to teach many different indexing concepts and waiting for indexes to build often becomes a detriment to the learning process.
9I OEM Virtual
Index Wizard
The Virtual Index Wizard feature is provided in the Tuning Pack option of 9I
OEM. Although there are a couple of ways to activate the wizard, let's take
a look at the one that I most often use. Since we are going to be naviating
through the SQL Analyze tool, we might as well review some of the other features
it provides.
SQL Analyze
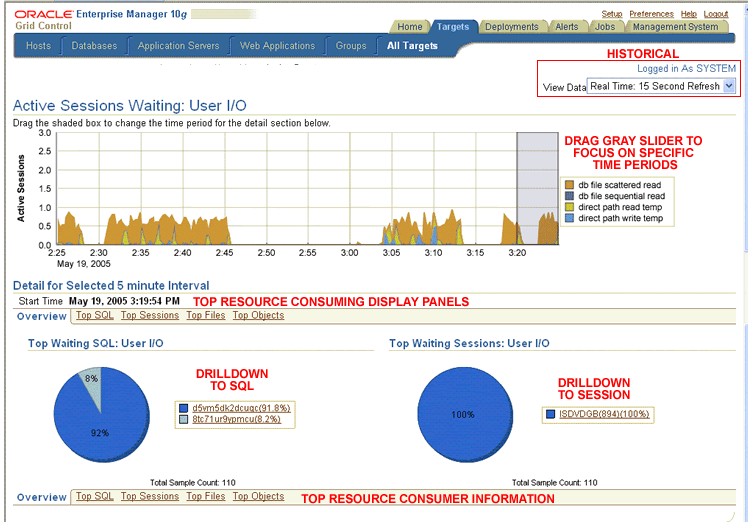
9I OEM provides the SQL Analyze tool to view access path information. SQL Analyze
is only available if you have purchased the tuning pack option for 9I OEM. This
screenshot
shows me navigating through 9I OEM's menus to activate SQL Analyze.
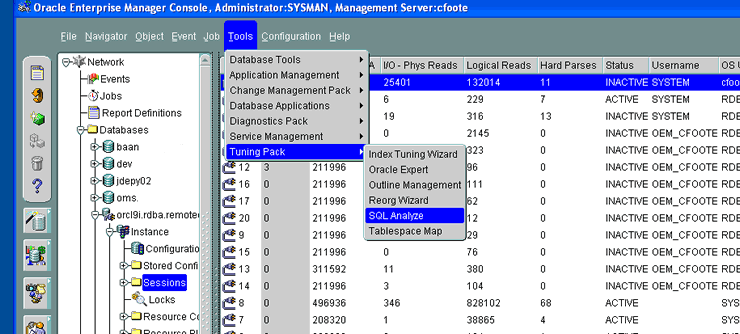{kind=link}
When you activate SQL Analyze, the first step the utility performs is to display a listing of all of the top resource consuming SQL statements that are contained in the library cache. If the statement has been flushed from cache, you won't find it in this display.
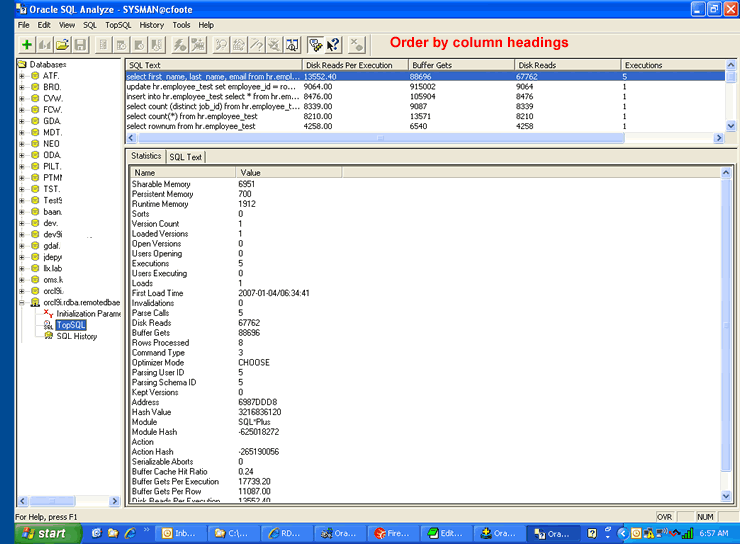{kind=link}
The tool lists all of the databases on the left side of the panel that you worked with in the past. As you can see, I am a pretty active user of SQL Analyze. I can double-click on any statement in the top SQL listing to view its access path information. I can also use the menu system at the top of the screen to create a blank worksheet for new queries that I can enter manually. I found the statement I wanted from the listing and double-clicked on it to activate the SQL tuning panel.
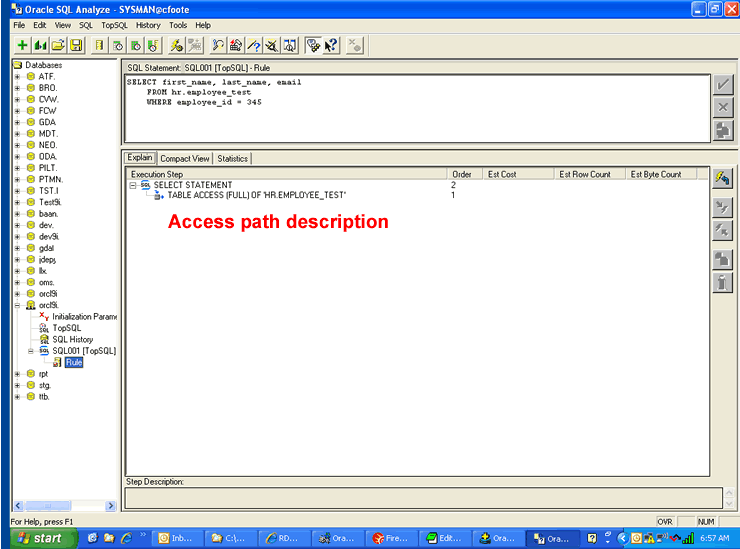{kind=link}
The panel displays the SQL statement, and like our other utilities, allows us to step through the access path the query is taking. I can click on the SQL drop down menu at the top of the screen to ask Oracle to explain the statement using the various optimizer modes that are available.
SQL Analyze
Tuning Tools
SQL Analyze provide us with tools that facilitate the SQL tuning process. The
tools
menu at the top of the screen allows me to choose from three different wizards.
We'll review the Virtual Index Wizard in just a moment.
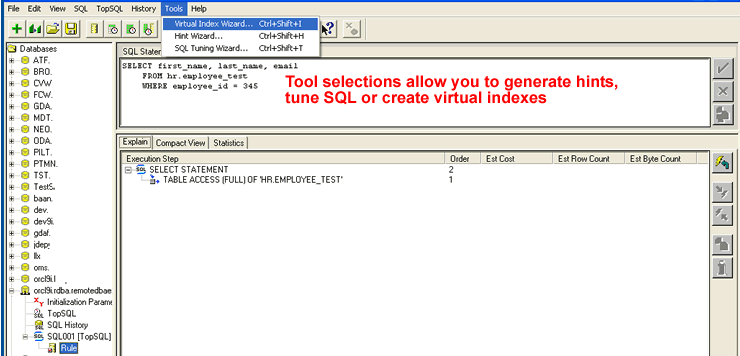{kind=link}
The Hint Wizard allows us to choose hints from a drop-down menu system, while the SQL Tuning Wizard activates an intelligent advisor that provides us with SQL tuning recommendations. Once you have run the SQL Tuning Wizard a few times, it's pretty easy to see that it was the precursor to some of the more advanced utilities that are now available in Oracle 10G.
Virtual Index
Wizard
The Virtual Index Wizard allows me to create virtual indexes on tables that
my query is accessing. The key word in that last sentence is "virtual".
Oracle does not permanently create the index. The intent of the wizard is to
allow users to determine the potential performance impact a new index would
have on the statement being analyzed. It is then up to the user to permanently
create the index.
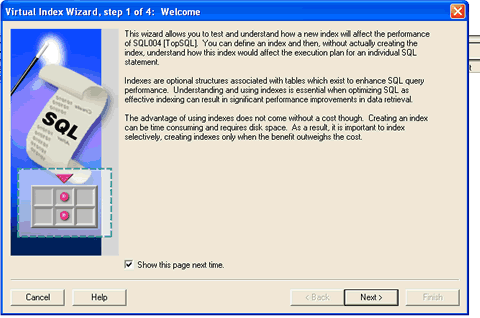
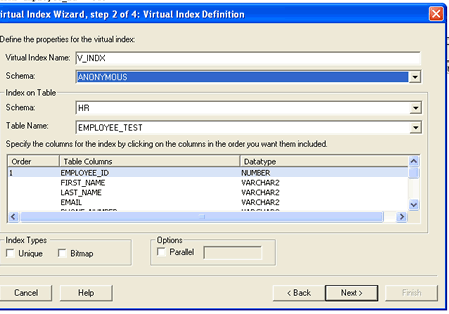
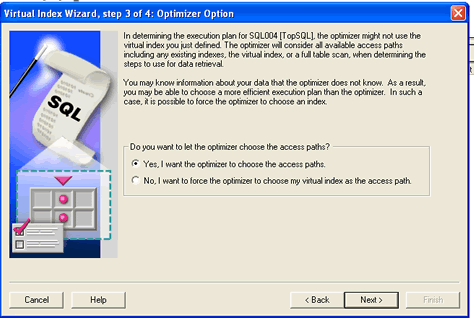
If I click on the Virtual Index Wizard menu selection, 9I OEM responds by displaying the Virtual Index Wizard introduction panel. When I click on next, the wizard displays a panel that allows me to select the columns for my virtual index. Clicking next again displays a panel that allows me to attempt to force Oracle to use the new index or allow it to choose the new index on its own. My personal preference is to allow Oracle to choose the index on its own without providing any additional prodding.
{kind=link}
{kind=link}
{kind=link}
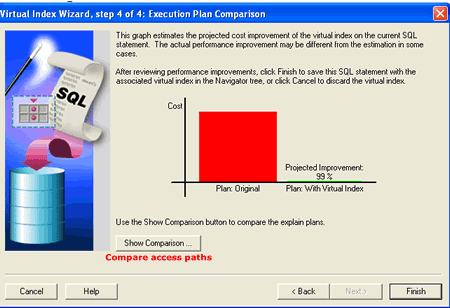
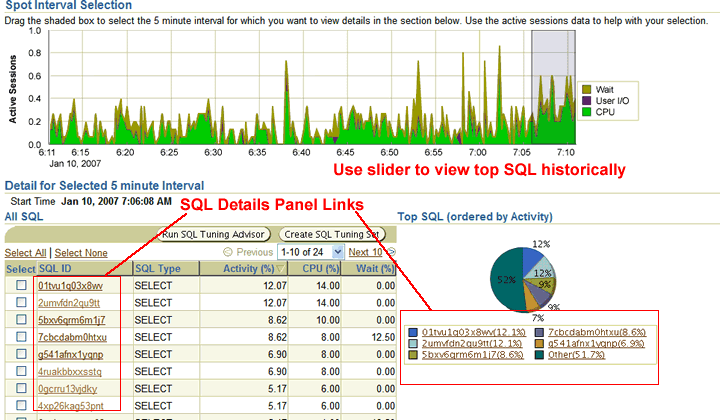
Clicking Next again displays the projected cost improvement the new index will have on the statement being analyzed. I used a full table scan on a rather large table as an example. Based on the display, we can be pretty sure that the new index will have a positive affect on our statement's performance. The last panel also displays a button that allows us to view the before and after access paths.
{kind=link}
The Virtual Index Wizard does a fairly good job of estimating the impact that new indexes will have on a SQL statement. It is an excellent tool to use when you are starting your tuning education as well as evaluating access paths in Oracle 9I databases.
I was surprised when I found that this feature was not contained in 10G Grid Control. I continue to firmly believe that using a tool to quickly build a virtual index, determine if the optimizer will use it and then display a prediction of the index's performance boost (or degradation) is very beneficial to the tuning process. I used the virtual index wizard dozens of times and will continue to use it when I tune 9I (and earlier) databases.
Virtual Indexes
in Oracle10G
Although Grid Control doesn't provide the same graphical interface to create
virtual indexes as it did in 9I OEM, all is not lost. We can revert to the tried-and-true
SQL*PLUS command line to build virtual indexes using the "NOSEGMENT"
option. The only feature it won't provide us is the forecast of the statement's
performance.
The format of this blog page doesn't provide me with enough space to show you the output from my SQL*PLUS demo. Not without a whole lot of editing anyway. So, I decided that the best option would be to create a separate HTML page for the 10G virtual index demo output.
The demo will show you:
- How to create virtual indexes in 10G
- How to configure your session to allow the optimizer to choose a virtual index as an access path
- The affect the "_use_nosegment_indexes" parameter has on access path selection
- The error messages returned if you attempt to manipulate virtual indexes
- Information stored in the data dictionary pertaining to virtual indexes
Here's a link to the 10G SQL*PLUS Virtual Index demo!
Now that we understand how to create virtual indexes, lets' take a look at how any index can influence simple access paths, join methods and join orders.
Index Affects
on Access Paths
Let's use a nested loop join as a quick and somewhat easy example. In a nested
loop join, one of the tables in the join is known as the outer table while the other table (the table being probed) is known as the inner table.
Oracle reads a row from the outer table and uses the columns in the join condition
to probe the inner table.
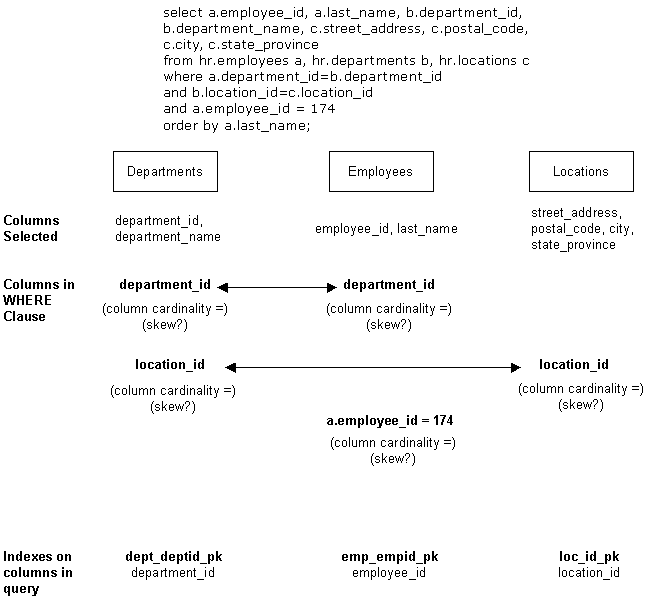
Take a look at the SQL statement and graphical access path display below:
select a.employee_id, a.last_name, b.department_id, b.department_name,
c.street_address, c.postal_code, c.city, c.state_province
from hr.employees a, hr.departments b, hr.locations c
where a.department_id=b.department_id
and b.location_id=c.location_id
and a.employee_id = 174
order by a.last_name;
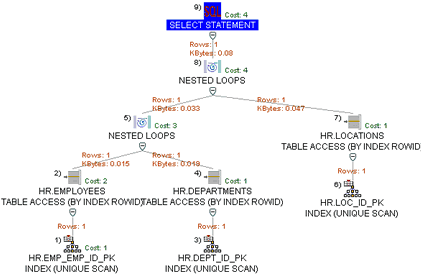
We are joining three tables together HR.EMPLOYEES, HR.DEPARTMENTS and HR.LOCATIONS. Notice that we have two different nested loop join operations. Oracle only joins two tables together at a time. It then creates an intermediate result set and uses that result set to join to the next table. It can use any type of join method available for any of the join operations.
The indexes we have available to us are:
- EMP_EMP_ID_PK - index on the EMPLOYEE_ID column of the HR.EMPLOYEES table
- DEPT_ID_PK - index on the DEPARTMENT_ID column of the HR.DEPARTMENTS table
- LOC_ID_PK - index on the LOCATION_ID of the HR. LOCATIONS table
The optimizer has chosen to join the HR.EMPLOYEES AND HR.DEPARTMENTS tables first using the nested loop join method. It is on this join condition - A.DEPARTMENT_ID = B.DEPARTMENT_ID. HR.EMPLOYEES is known as the outer table and HR.DEPARTMENTS is classified as the inner table of the join.
The optimizer looked at the local predicate "A.EMPLOYEE_ID=174" and checked to see if there was an index that it could use to improve data access performance. It found the EMP_EMP_ID_PK index that is defined on the EMPLOYEE_ID column. It will access the index first and retrieve the ROWID for the row that has an EMPLOYEE_ID of 174. It will use the ROWID to probe the HR.EMPLOYEES table.
As stated previously, the optimizer has chosen the nested loop join operation. It will access the HR.EMPLOYEES table using the EMP_EMPID_PK index, retrieve the value for DEPARTMENT_ID and use it to probe the HR.DEPARTMENTS table looking for a match (A.DEPARTMENT_ID = B.DEPARTMENT_ID). If it finds a DEPARTMENT_ID value in the HR.DEPARTMENTS table that matches, Oracle will use that row in future operations. If it does not match, Oracle will discard it.
Notice that the optimizer has chosen to use the DEPT_ID_PK index that is built on the HR.DEPARTMENTS' DEPARTMENT_ID column. Since we are probing this table using the values we found for DEPARTMENT_ID from the HR.EMPLOYEES table, Oracle will use the index on the HR.DEPARTMENTS' DEPARTMENT_ID column.
The B.LOCATION_ID = C.LOCATION_ID is the join condition that is used in the second join operation. The intermediate result set is used as the outer table and the HR.LOCATIONS table is used as the inner table. The same type of probe occurs. Since we are looking for matches using the LOCATION_ID contained in the intermediate result set, the optimizer will choose the LOC_ID_PK index.
Here's how indexes can influence the type of join used and the order of the tables being joined:
- If we didn't have indexes on either of the first two tables being joined, the optimizer would most likely have used a hash operation instead of a nested loop join to join the tables together. The optimizer knows that the hash join operation is best used for joins that return larger result sets. It could also have influenced the join order of the tables. In the example, the optimizer could have chosen to join the HR.DEPARTMENTS table to the HR.LOCATIONS table first. It would have then used the intermediate result set created to probe the HR.EMPLOYEES table.
- The more indexed columns we have on a table, the greater the chance that the optimizer will use it as the outer table of the nested loop join. It can filter out more rows before it sends it to the join operation. The earlier it can filter rows out, the better.
- If we have an index on both join columns (i.e. indexes on the DEPARTMENT_ID columns for both the HR.DEPARTMENTS and HR.EMPLOYEES tables), Oracle will use the DEPARTMENT_ID index on the inner table but not the outer. Why is that? Oracle doesn't know if it has a DEPARTMENT_ID VALUE in the inner table that matches a DEPARTMENT_ID value in the outer table unless it reads each and every row of the outer table to do the match. Think about it. It knows that since it has to read every row from the outer table to perform the match, the only indexes it can use are the indexes built on local predicates (i.e. "A.EMPLOYEE_ID=174").
- If we have an index on the join column for one table and not the other, the optimizer will often favor the table that has the index on the join column as the inner table of the join. It knows it can't use an index on the join column if it is the outer table but it can use the index if it is the inner.
This is just one
quick example to show you the impact that indexes have on access path selection.
The key to success is to continuously experiment with the optimizer. One of
the features that can speed up your experimentation is to use virtual indexes.
Remember, this feature uses an "undocumented" parameter in 10G.
I would like to thank super-DBA Mark Shore for re-igniting my interest in both
9I and 10G virtual indexes. Marks has a natural talent for this profession which I often wish I had.
Thanks for Reading,
Chris Foot
Director of Operations
Remote DBA Experts
Oracle Ace 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}