
Implementing an Archiving Strategy for Data Warehousing in SQL Server - Part 2
Part 1 | Part 2
As discussed in part one of this two-part series on implementing a robust and flexible archiving strategy for a data warehouse environment, warehouse administrators require a comprehensive and flexible system to ensure that archiving allows them to manage data storage to the appropriate and available physical resources, as well as meet the business needs of having historical and current data available with adequate querying response times.
Part one of this article reviewed a common data warehouse environment containing fact and dimension tables in a staging database, as depicted in the following:
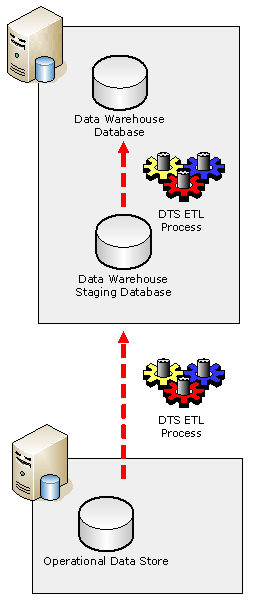
Figure 1.1: Data warehouse sample environment.
As discussed previously, a combination of stored procedures that draw their configuration and task information from the staging database table ArchiveJobs will execute and automatically archive data associated with the specified table. The following sections describe in detail the purpose of the stored procedures as well as their technical composition.
Stored Procedures
The following table contains a description of the stored procedures associated with the archiving process.
| Procedure Name | Purpose |
| LoadArchiveTables | Wrapper procedure that consumes active, successful jobs from the ArchiveJobs table in the staging database and passes information to the AddFactArchive stored procedure for each job to create archive entities and to migrate the data from the source entity to its historical mirror. |
| AddFactArchive | Procedure called from the LoadArchiveTables stored procedure that will create the mirror historical table and populate it with data using settings passed from the ArchiveJob table. |
| ChgFactArchiveDPV | Procedure called from the LoadArchiveTables procedure that refactors the distributed, partitioned view to ensure that all new historical entities and the current entity are contained within the distributed partitioned view. |
Table 1.1: Stored procedures and functionality.
LoadArchiveTables
The LoadArchiveTables procedure makes a call to the AddFactArchive stored procedure for each row in the ArchiveJobs table in the staging database that is marked as active and successful. The information that is passed to the AddFactArchive stored procedure includes primary key values, which are used to extract the data from the primary fact table and store it in the new historical table.
The portion of the procedure that obtains the key values uses the archive date setting from the ArchiveJobs table and uses the data warehouse’s Time Dimension to obtain the minimum and maximum primary fact table keys for the data that must be archived. Additionally, the logic to conduct the join between the Time Dimension and the fact table to archive are part of specific implementation logic that must be added to the procedure for the archive process to be successful.
The procedure has logic to determine if the entity that is being archived has implementation logic or not. If it detects that there is no way to obtain the keys, it will exit. These keys are passed to the AddFactArchive stored procedure along with other contextual information that will tell the AddFactArchive procedure to which table the keys should apply and which table to archive.
After the AddFactArchive stored procedure is executed, the LoadArchiveTables procedure then calls the ChgFactArchiveDPV to refactor the view associated with the table being archived to include any new historical mirrors of the table.
AddFactArchive
The AddFactArchive stored procedure requires the archive source table to have a primary key constraint. Using this, it will analyze the structure of the source table to archive based on data passed to it from the LoadArchiveTables stored procedure from the ArchiveJobs table and replicate the structure into a valid SQL Server table. It will then craft queries based on the minimum and maximum key inputs supplied to it from the LoadArchiveTables stored procedure and insert that data into the new archive structure. The procedure then continues to delete these same records from the source archive fact table.
One critical function of the AddFactArchive procedure is to ensure that the table that is being created does not already exist. If the archive process is being run within a period that is covered by an existing archive table, the procedure will not create the entity and will then continue with its insert and delete logic to migrate the data to the existing entity.
Because this portion of the solution is a TSQL-only process, the archive table is scripted and created using SQL-DMO directly from the stored procedure using the sp_OACreate stored procedure. Using these COM automation procedures, a reference to DMO is instantiated, and methods that script a table mirror are called. The following code snippet is an example of how the stored procedure, interacting with SQL-DMO, creates a TSQL string to create a mirror table of the fact table.
PRINT 'The archive table ' + @ArchiveTableName + ' does not exist.
Creating archive table...' + CHAR(10) + CHAR(13)
PRINT 'Scripting Object [' + @TableNameToArchive + ']...' + CHAR(10) +
CHAR(13)
--Create a SQLDMO Object to Obtain the Script definition of the table
DECLARE @oServer int
DECLARE @method varchar(300)
DECLARE @TSQL varchar(4000)
DECLARE @ScriptType int
EXEC sp_OACreate 'SQLDMO.SQLServer', @oServer OUT
EXEC sp_OASetProperty @oServer, 'loginsecure', 'true'
EXEC sp_OAMethod @oServer, 'Connect', NULL, @SQLServerName
SET @ScriptType =4|32|262144|268435456|73736 --Do not script a drop
statement, do not script relationships, only script primary keys,
script all indexes
(http://msdn.microsoft.com/library/default.asp?url=/library/en-
us/sqldmo/dmoref_ob_3tlx.asp)
SET @method = 'Databases("' + @DatabaseName + '").' +
'Tables("' + @TableNameToArchive + '").Script' +
'(' + CAST (@ScriptType AS CHAR) + ')'
EXEC sp_OAMethod @oServer, @method, @TSQL OUTPUT
EXEC sp_OADestroy @oServer
--Modify the generated script to use the Archive Table Name instead of
the Real table name and get rid of batch separators
SET @TSQL = REPLACE(@TSQL, @TableNameToArchive, @ArchiveTableName)
--Get rid of the identity specification on the primary key since we'll
be inserting
SET @TSQL = REPLACE(@TSQL, 'IDENTITY (1, 1)', '')
--Get restore the original primary key column name
SET @TSQL = REPLACE(@TSQL, @ArchiveTableName + 'ID',
@TableNameToArchive + 'ID')
--Get rid of the batch separators
SET @TSQL = REPLACE(@TSQL, 'GO', '')
PRINT 'Obtained Object Definition' + '...' + CHAR(10) + CHAR(13)
BEGIN
--Print the Object Definition
PRINT '[' + @ArchiveTableName + '] Definition:' + CHAR(10) +
CHAR(13)
PRINT @TSQL
END
IF @TestMode = 0
BEGIN
--Execute the Object Creation
PRINT 'Creating object [' + @ArchiveTableName + ']...' +
CHAR(10) + CHAR(13)
EXEC(@TSQL)
PRINT 'Completed creation of object [' + @ArchiveTableName
+ ']...' + CHAR(10) + CHAR(13)
END
Table 1.2: Creating mirrored archive tables from TSQL.
The variable @ArchiveTableName and @TableNameToArchive are predefined by data passed to this procedure by the LoadArchiveTables stored procedure. Using this data, the previously cited code will create a mirror of the @TableNameToArchive table with the name specified in the @ArchiveTableName variable.
To be truly dynamic and capable of analyzing any table, the AddFactArchive procedure will next analyze the structure of the source table to archive and create insert and delete statements that will ensure that the data is moved from the source table to the new or existing archive table using the minimum and maximum keys passed to it from the LoadArchiveTables stored procedure. You can accomplish this by using the INFORMATION_SCHEMA views to analyze the columns, constraints, and relationships of the source table.
To assemble the SQL statements to migrate the data, you must first create a cursor based on the information schema views of the table to archive and to create a string of comma-delimited column names for use later when creating the insert and delete statements. The following table depicts the code that conducts this cursor.
--Create a SQL Statement that SELECTS from the Current Table and
Inserts into the Archive Table using the specified Min and Max Keys. Be
sure to exclude the Primary Key Column
PRINT 'Obtaining column listing for object [' + @TableNameToArchive +
']...' + CHAR(10) + CHAR(13)
DECLARE @TempPrimaryKeyColumn VARCHAR(50)
DECLARE Columns CURSOR FOR
SELECT C.COLUMN_NAME, TC.COLUMN_NAME
FROM INFORMATION_SCHEMA.COLUMNS C
LEFT JOIN
(
SELECT ITC.TABLE_NAME, ITC.CONSTRAINT_NAME, KU.COLUMN_NAME
FROM
INFORMATION_SCHEMA.TABLE_CONSTRAINTS ITC
INNER JOIN INFORMATION_SCHEMA.KEY_COLUMN_USAGE KU
ON KU.CONSTRAINT_NAME = ITC.CONSTRAINT_NAME
WHERE ITC.CONSTRAINT_TYPE = 'PRIMARY KEY'
) TC
ON C.TABLE_NAME = TC.TABLE_NAME
AND C.COLUMN_NAME = TC.COLUMN_NAME
WHERE C.TABLE_NAME = @TableNameToArchive
--AND TC.CONSTRAINT_NAME IS NULL
ORDER BY C.ORDINAL_POSITION
OPEN Columns
FETCH NEXT FROM Columns
INTO @ColumnList, @TempPrimaryKeyColumn
WHILE @@FETCH_STATUS = 0
BEGIN
--Use Information Schema to assemble the column list for the
archive table
IF @TempPrimaryKeyColumn IS NOT NULL
BEGIN
--Preserve the Primary Key Value
SELECT @PrimaryKeyColumn = @TempPrimaryKeyColumn
END
BEGIN
--The column is not a primary key, so include it in the
select list
SELECT @SQLColumnCommand = @SQLColumnCommand + ', ' +
@ColumnList
END
FETCH NEXT FROM Columns
INTO @ColumnList, @TempPrimaryKeyColumn
END
CLOSE Columns
DEALLOCATE Columns
Table 1.3: Assembling a column list from information schema.
Once this column list is assembled, it is then used as the basis for the insert and delete statements, in concert with the key values supplied to the stored procedure to obtain the correct slice of data to archive. The insert and delete statements are generated and executed within the context of a transaction so that if there are any issues with inserting or removing data, everything reverts to the state prior to execution with regard to the integrity of the data.
In addition to generating and executing the insert and delete statements, the AddFactArchive procedure also will execute the insert and delete transactions in a loop. While in a set-based processing mindset, this might seem counterintuitive, it assists in very large databases so that SQL Server does not expend its resources attempting to process millions of rows simultaneously. This also avoids typical issues with large transactions such as disk or I/O contention, extreme processor utilization, the expansion of tempdb, or issues with reaching a transaction log growth limit based on physical disk resources. You can realize increased archive throughput by dividing the transaction into digestible batches.
This stored procedure also ensures that the source table is modified so that it can still participate in the distributed partitioned view. It performs the same function for the historical entities as well. To participate in the distributed partitioned view, each table must be declared with a check constraint on the column that indicates what range of values it stores. Because the archiving process changes the range of data in the main fact table as well as inserts data into a new historical fact table, the stored procedure also modifies these check constraints through dynamic SQL. This modification ensures that the distributed partitioned view will be redefined with the understanding of the data each table contains. The following snippet of code from the stored procedure depicts how to do the check constraint generation:
--Alter the check constraint for the archive table
--Create the Partitioning Key Constraint
PRINT 'Generating Check Constraint Modification for the archive
table...' + CHAR(10) + CHAR(13)
SELECT @PartitionCheckConstraintSQL = 'if exists (select * from
dbo.sysobjects where id = object_id(N''CHK_' + @ArchiveTableName + ''')
and OBJECTPROPERTY(id, N''IsCheckCnst'') = 1)' + CHAR(10)
SELECT @PartitionCheckConstraintSQL = @PartitionCheckConstraintSQL +
'ALTER TABLE ' + @ArchiveTableName + ' DROP CONSTRAINT CHK_' +
@ArchiveTableName + CHAR(10) + CHAR(13)
PRINT @PartitionCheckConstraintSQL
IF @TestMode = 0
BEGIN
--Drop the constraint since it will be created
PRINT 'Droping the check constraint on the archive
table...' + CHAR(10) + CHAR(13)
EXEC(@PartitionCheckConstraintSQL)
END
SELECT @PartitionCheckConstraintSQL = 'ALTER TABLE ' +
@ArchiveTableName + ' ADD CONSTRAINT CHK_' + @ArchiveTableName + '
CHECK (' + @PrimaryKeyColumn + ' BETWEEN ' +
CONVERT(VARCHAR,@MinPartitionKeyID) + ' AND ' + CONVERT(VARCHAR,
@MaxPrimaryKeyID) + ')' + CHAR(10) + CHAR(13)
PRINT @PartitionCheckConstraintSQL
Table 1.4: Dynamic fact table check constraint redefinition.
The SQL in table 1.4 uses a variable called @PartitionCheckConstraintSQL to contain the command that will alter the check constraints on the existing source table housed in the variable @ArchiveTableName. The code first drops the existing, out-of-date constraint (since the date range of the value has changed), then, using the data passed from the LoadArchiveTables procedure, it uses the primary keys to re-create the constraint. This also happens on the historical table when it is created, and always happens, even if the historical table already exists.
ChgFactArchiveDPV
For each entity to be specifically archived in the ArchiveJobs table in the staging database, a distributed partitioned view will be created to match. This will ensure that any queries against the desired facts will be focused on the correct entities that house the desired history. If the query spans historical periods, both entities will be queried. This level of simplification and abstraction ensures that the overhead will be focused in the correct areas of the data warehouse current and historical data, and that data retrieval will be fast (e.g., the user will not have to spin through several months or years of data to get the most recent data or a historical section of time).
The ChgFactArchiveDPV stored procedure is called from the LoadArchiveTables stored procedure after the archive entity is created and the data facilitated by the AddFactArchive stored procedure is archived. This stored procedure uses information from the information schema views to drop the existing partitioned view if it exists for the specified table, and then recreates a view that unions together all tables that have text similar to the table to be archived. The following table reviews this process:
SET @SQLCommand =
'if exists (select * from dbo.sysobjects where id =
object_id(N''[dbo].[v' + @FactArchiveTable + 'Partition]'') and
OBJECTPROPERTY(id, N''IsView'') = 1)' + CHAR(13) +
'drop view [dbo].[v' + @FactArchiveTable + 'Partition]' +
CHAR(13)
PRINT @SQLCommand
IF @TestMode = 0
BEGIN
--Drop the view if it exists
EXEC sp_executesql @SQLCommand
END
SET @SQLCOmmand = 'CREATE VIEW v' + @FactArchiveTable +
'Partition AS' + CHAR(13)+ CHAR(13)
DECLARE DPV CURSOR FOR
SELECT TABLE_NAME FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME
LIKE @FactArchiveTable + '%'
OPEN DPV
FETCH NEXT FROM DPV INTO
@FactArchiveTable
WHILE @@FETCH_STATUS = 0
BEGIN
SET @SQLCommand = @SQLCommand + CHAR(13) + CHAR(13) +
'UNION ALL' + CHAR(13) + CHAR(13) + 'SELECT * FROM ' +
@FactArchiveTable + CHAR(13) + CHAR(13)
FETCH NEXT FROM DPV INTO
@FactArchiveTable
END
CLOSE DPV
DEALLOCATE DPV
SET @SQLCommand = REPLACE (@SQLCommand, 'AS' + CHAR(13) +
CHAR(13) + CHAR(13) + CHAR(13) + 'UNION ALL', 'AS')
PRINT 'Assembling SQL Command..'
PRINT @SQLCommand
IF @TestMode = 0
BEGIN
--Create the View
EXEC sp_executesql @SQLCommand
END
Table 1.5: Creating a partitioned view on fact tables and history fact tables.
As depicted in the previous code example, the cursor ensures that a valid UNION ALL statement is created for each table that is similar in name to the base fact table. This allows for the automated provisioning of any new historical tables, as well as any tables that have been physically removed.
Assembling the Solution
Once all of these components are in place, warehouse administrators will be required to enter in rows into the ArchiveJobs table in the staging database, which will direct the LoadArchiveTables stored procedure on the tables that need to be archived. The last step is to establish a SQL Agent job that will call the LoadArchiveTables stored procedure on a scheduled basis. Based on the current code, this should be on at least a monthly basis, but with modification to the stored procedure, it can be run multiple times in the same month.
This solution allows for warehouse administrators to have a robust, automated and flexible method of archiving data from fact tables into historical partitions that can incur the query overhead appropriately. By using this strategy, warehouse administrators can manage the performance and storage of the data warehouse more easily and efficiently. In a future article, we will review how to manage archiving data with Analysis Services via DSO.
--
Eric Charran is currently working as a Technical Architect and Web Developer, in Horsham, PA. Eric holds Microsoft Certifications in SQL Server and has significant experience in planning, designing, and modeling n-tier applications using SQL Server 2000, as well as architecting and implementing .NET framework based applications, solutions and Web services. Eric’s other professional skills encompass Database Administration, Data Warehousing and Application Architecture, Modeling and Design, as well as Data Warehouse Transformation and Population using DTS. Eric is also skilled in developing and implementing ASP.NET and Windows forms applications, using technologies such as COM+, the .NET framework, VB.NET and other .NET languages.
Contributors : Eric Charran
Last modified 2006-01-05 04:23 PM