
How High Can You Go?
Introduction
Someone on the Oracle-L mailing list recently asked, “Does Oracle impose any limit on the height of a b-tree index?” A member of the list, who had been on one of the official advanced internals courses, said that his notes quoted a limit of 24. But that’s not an obvious limit, so how do you find out whether it’s right or not?
If you’ve got about 50GB of free disk space, Oracle 9.2 or better, and around 10 hours of run time, then this article will tell you how. (It’s just for fun, but you may pick up a couple of useful ideas on the way.)
The code in this article was tested on Oracle 9.2.0.4.
How Big is Big?
In an earlier article on Oracle’s implementation of B-trees' indexes, I pointed out that B-trees are always balanced — every leaf is the same distance from the root. So how big will an index have to be to get to a height of 24 (or blevel = 23)?
If we push Oracle into the worst possible case, we could build an index that degenerated into a binary tree. In other words, every branch block holds pointers to just two other index blocks; and at the bottom of the index, every leaf block points to just one row in a table.
The arithmetic is easy — we just keep multiplying by two:
| The root block at blevel = 23 points to 2 branch blocks below |
| Two branch blocks at blevel = 22 point to 4 branch blocks below |
| Four branch blocks at blevel = 21 point to 8 branch blocks below |
| 2^3 branch blocks at blevel = 20 point to 2^4 branch blocks below |
| … |
| 2^22 branch blocks at blevel = 1 point to 2^23 leaf blocks below |
Assume we use the smallest block size available (in my case 2K, I don’t think the modern versions of Oracle allow for anything less), 2^24 blocks is 32GB. Add to that the size of the table that you need to index, and then the volume of undo you would generate, not forgetting the temporary space you might need to build the index; and the experiment seems a little over the top.
Because It’s There
It may be difficult, but that doesn’t mean you shouldn’t (or can’t) do it. Anyway, you might learn something useful along the way; and you can always ration the amount of time you’re prepared to spend on the exercise.
So, did I manage to build the test case in a realistic time frame? I have to admit that I didn’t finish the job that I’ve just described. After completing the proof of concept and testing the code, I put it to one side, waiting for a machine with plenty of disk space. But this was my strategy:
- I couldn’t build a table, then index it — building the index would probably take too long — so I would create an empty table and insert rows into it. (If necessary I would use a pl/sql loop and commit every few minutes to keep the size of my undo tablespace down.)
- I didn’t need to build a huge table; I could build a table with just one small column, and use a function-based index to create the big index. A table with the target 2^23 (8 million) rows need only be a hundred megabytes or so by the time the index reached 32 GB.
- I wouldn’t use the validate index (or analyze index validate structure) command to check the index height — it would probably take ages, doing lots of disk reads and other nasty stuff like delayed block cleanout — I would just dump the index root block (the one immediately after the segment header block) and check the value of the blevel field (kdxcolev) in the trace file.
- Since I wasn’t going to use create.. nologging, I would disable archivelog mode for the duration — I’d even set the _disable_logging parameter to true and create much bigger log files if that helped.
But the problem remained: How was I to rig the system to make sure that my B-tree index turned into a minimalist binary tree (two entries per block)? Oracle 9i gave me the answer to that one. In earlier versions of Oracle, a single index entry had a size limit that was around 40 percent of the block size — for example 3,128 bytes for a database using 8K blocks. But the limit in Oracle 9 had increased to about 75 percent; it’s 6,398 bytes for an 8K block, and 1,478 bytes for a 2K block.
All I had to do was create the following objects:
drop table t1;
create table t1 (
n1 number
);
create index t1_i1 on t1 (1pad('0', 1469, '0'))
tablespace test_2k
;
You’ll notice that my index takes the numeric column from the table and turns it into a character value by left-padding it with zeros to a length of 1,469 bytes; this is slightly smaller than the notional limit because of overheads such as the rowid, column length bytes, lock byte and flags. In fact, I could make the code a little more efficient (less undo and redo) by reducing the padding to about 1,000 bytes.
You may also notice that I’ve taken advantage of the Oracle 9 option of using different block sizes in different tablespaces. This rarely serves any useful purpose beyond handling transportable tablespaces, but in this case, it was critical to minimising the space requirements, and undo generation. The index is in a tablespace that uses 2K blocks.
If there is only room for a single entry in each leaf block, you may wonder how Oracle can manage to produce a binary tree at all — surely a binary tree needs two pointers in each branch, and the blocks are too small to hold two keys. But a branch block uses several tricks to maximise efficiency; and one of these tricks is that the first pointer in the block (known as the “leftmost child pointer” — field kdxbrlmc in the block dump) doesn’t have a key value associated with it; its key value is implicitly “something less than the key of the next pointer”.
So, having created the table and index, I then wrote a little insert statement (using syntax specific to 9.2 and above) to get data into the table:
insert into t1
with temp_data as (
select /*+ materialize */
rownum
from all_objects
where rownum <= 3000
)
select
/*+ ordered use_nl (t2 */
rownum
from
temp_data t1,
temp_data t2
where
where
rownum <= power (2, 23)
;
Remember that I needed only 8 million rows to fill my height 24 index. So I’ve generated a temporary set (with the materialize hint there to guarantee that Oracle does generate a temporary table) of 3,000 rows, and produced the Cartesian join to give me a possible 9 million rows. But I’ve restricted the number of rows returned, and hinted an ordered nested loop to make sure that the code runs as efficiently as possible for my purposes. And, of course, my first tests involved figures like power(2,5) as the number of rows.
The theory is this: Every time I insert the next row, it will go into the right-hand leaf block, which will split, giving two leaf blocks with one row each. The split will either cause the parent branch block to become full (at two pointers) or, if it is already full, to split. Splits will propagate up the tree as more data goes into the table.
For small numbers of rows, I then ran the following:
validate index t1_i1;
select
height, If_blks, br_blks
from index_stats
;
In the following table, the theory can be summed up by a few samples of the results that I wanted to see:
| Rows | Height (blevel+1) | Leaf Blocks | Branch Blocks |
| Power(2,5) = 32 | 6 | 32 | 31 |
| Power(2,6) = 64 | 7 | 64 | 63 |
| Power(2,7) = 128 | 8 | 128 | 127 |
Theory and practice coincided. The index behaved exactly as predicted. Not only did these figures drop out after the validate; the requirement that the index was “full” and one extra row would push the height up by one was also true. For example, taking the test case with rows = 32 and inserting row number 33, the figures changed to:
HEIGHT LF_BLKS BR_BLKS
---------- ---------- ----------
7 33 37
You might ask why adding one row has resulted in six extra branch blocks. Well, the targeted leaf block had to split, adding one leaf block; and the (level 1) branch block above it then had to split as well, adding one branch block. But the (level 2) branch block above it was full and also had to split, adding one more branch block. And so on up the tree, through all five of the existing blevels including the root, adding a total of five branch blocks. Then, since the root had been split, a new root had to be created to point to the two level 5 branches, and that new root block is the sixth new branch block.
Major Testing
Having proved that the theory was correct, I increased my tablespace to a little over 1GB, and ran the program with power(2,18) + 1 as the row count to get an index of height 20 (power(2,18) gives me an index with blevel = 18, one more row pushes the blevel to 19, which makes for a height of 20). In this case, I just dumped the index root block to check its blevel — which was 19 as expected.
The results were satisfactory — the index was about 1GB, the undo segment had grown to about 500MB, and the time taken was about 18 minutes on a fairly ordinary laptop. Most of the time lost was spent waiting on log file effects, and this was before I had done anything like switching off archivelog mode, resizing the redo logs, or the redo log buffer). The results were similar on Oracle 9i and Oracle 10g (which I also tested to power(2,18)).
So, by doubling up five more times, I think I can say with some confidence: If you have about 32GB of space for the index, 16GB of free space in your undo tablespace, and about 10 hours of free time, then running the code for power(2,23) rows should build a full index of height 24, and inserting one more row in the table should crash your session.
The code needs a change for Oracle 8. You can’t get a binary tree for Oracle 8, as the largest index entry is limited to 40% of a block. However you can still get a three-way split in every block (Is that a ternary tree ?) — so the test code has to be changed to use power(3,N) as the number of rows and a different length in the lpad() call. Of course, if you want to keep the size down, you will also have to create a database with a 2K block size, since you can’t simply create a tablespace and db_cache with a 2K block size, and as a side effect you will use more rollback space.
Addendum
After building and completing this test, I suddenly thought, “Why am I filling a height 24 index? Would it be possible to force Oracle into producing a very sparse b-tree index at much lower cost?” The idea I had was that if I could get Oracle to keep splitting the left hand block of an index, and if this split propagated up the tree in the same way, I could end up with a tree like the one in the diagram:
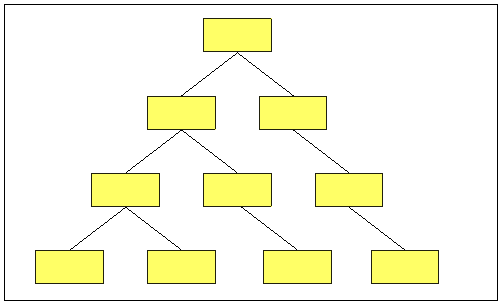
If I could do this, then I should be able to create an index with just 24 rows to get to a height of 24. (Note that only the blocks on the left-hand edge of the tree have two children, and the index of height 4 has a total of only 4 leaf blocks.).
This is the code that built an index of height 24 in less than a second on Oracle 9.2:
drop table t1;
create table t1 (
v1 varchar2(1469)
);
create index t1_i1 on t1(v1)
tablespace test_2k
;
begin
for i in reverse 1..24 loop
dbms_output.put_line(i);
insert into t1 values (lpad(i,1469,'0'));
end loop;
end;
/
Run this, but change the loop to insert 25 rows and within three seconds (the extra time comes from error logging, trace dumps, and rollback) you get:
ERROR at line 1: ORA-00600: internal error code, arguments: [6051], [], [], [], ...
It seems that Oracle can indeed only support indexes up to a height of 24. Moreover, a quick search on Metalink produced a reference to bug 1748260 in the 9.2.0.1 readme.txt explaining that certain operations on indexes with entries larger than half a block may receive this ORA-00600 error. I have a theory that this could happen for index entries less than half a block long; but, the volume of data needed is so much greater, that the probability of the problem appearing is extremely low.
The test case does not produce the same effect in Oracle 10g, which suggests that Oracle Corp. has changed the code that deals with index leaf splits (and not just to handle the 90/10 bug that was introduced in Oracle 9i).
Conclusion
I don’t think there is any real conclusion for this article. But, I guess, I could point out that playing around for a few hours to answer a theoretical and apparently pointless question has:
- produced a couple of useful little details about how indexes work
- uncovered a potential trap with “large-key” indexes (think IOTs and bitmaps)
- indicated that Oracle has changed their block-splitting algorithm in Oracle 10, which may (and this is just a speculative comment because there are always special cases) occasionally have a noticeable side effect when you migrate from 9i to 10g
--
Jonathan Lewis is a freelance consultant with more than 18 years' experience of Oracle. He specialises in physical database design and the strategic use of the Oracle database engine, is author of Practical Oracle 8I: Designing Efficient Databases published by Addison-Wesley, and is one of the best-known speakers on the UK Oracle circuit. Further details of his published papers, presentations, tutorials and seminars can be found at http://www.jlcomp.demon.co.uk/, which also hosts The Co-operative Oracle Users’ FAQ for the Oracle-related Usenet newsgroups.
Jonathan Lewis
Last modified 2005-04-15 09:45 PM