
Deploying a TPM? Beware the Distributed Transaction Trap
Introduction
The use of transaction processing monitors (TPM) to control Oracle systems seems to be an increasingly popular option in large developments. A TPM effectively puts a layer of control between the end-user and the application code that you would normally write to access the database, leaving you with a single 'logical database service', rather than a collection of separate programs (and possibly separate databases) that make up your overall application.
There are several arguments in favour of using a TPM:
- It is possible to include Oracle and non-Oracle (legacy) systems in a secure transaction-based system using a two-phase commit (2PC) controlled by the TPM.
- It is possible to make the functionality modular-- if you break down your application into a number of services then the number of different programs that exist to act as application servers can be transparent to the application -- the TPM can hand the work out to the appropriate server.
- It is possible to scale your application by having multiple copies of the server that handles the most frequently used procedure. The end-user program need not know which specific application server process is working on its behalf, the TPM system can maintain a list of suitable server processes, and handle the load balancing.
- It is possible, to some degree, to re-use existing programs that address a number of small, independent tasks, and modify them at relatively low cost to participate in larger TPM-controlled transactions.
- The TPM will probably have a number of built-in features for monitoring critical performance metrics (such as transactions per second) that would otherwise have to be hand-coded into every application so that you could demonstrate conformance to service level agreements (SLAs).
How the TPM Works
Figure 1 is a simple diagram of the components that might appear as the 'logical database service' in such a system. The diagram shows two possible data resources (one of them an Oracle database) several different functional processes (the Application Services), and three copies of a Transaction Manager (TM) process.
Consider a system for handling door-to-door flight-bookings. We might have three completely independent programs that can handle this task between them if they are given the correct inputs:
| Application Service 1 (App Serv 1): | book airline tickets |
| Application Service 2 (App Serv 2): | book limousine |
| Application Service 3 (App Serv 3): | update customer 'airmiles' scheme |
Our end-user program therefore interacts with the TPM to: start a transaction under the control of a Transaction Manager (TM) process, run App Serv 1, run App Serv 2 twice, run App Serv 3, and then call the TM to commit the entire set of activities as a single transaction.
The figure deliberately avoids showing how an end-user process interacts with the system. There are many variations in the way that this interaction might be implemented. End-user processes may, for example, connect directly to a Transaction Manager (TM) process that then calls Application Services according to the client's requests. Another possibility is that an end-user process may connect through a dispatcher process that identifies which Application Services to forward them to -- in which case the Application Service will have to contact a Transaction Manager before accessing the data resources. There may, or may not, be a process which is identifiable as 'the' TPM process. Different processes may pass messages through shared-memory queues, they may pass messages through disk-based queues.
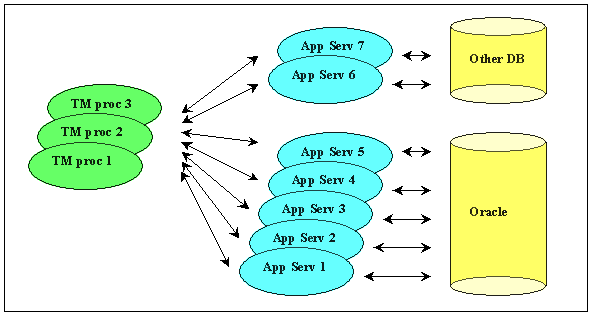
Figure 1: The 'logical database service'.
Whatever the case, there are two key implementation details:
- The Transaction Manager is used to put a boundary around the quantity of work that constitutes a single, atomic, transaction.
- The client does not need to know what data resources, and which Application Service processes, have been called to operate the transaction.
The Scalability Trap
In theory, there are numerous strategic advantages to using a TPM. So what could possibly go wrong? The problem arises through a combination of three characteristics -- a high degree of concurrency, tight clustering of current data (see side-bar), and distributed transactions. Unless you have considered the risk of this combination, and catered for it correctly in your design, your application will not scale.
|
Data Clustering The problem is exacerbated by indexes - in particular primary key indexes generated by meaningless sequential numbers. You might pack 10,000 order lines for Monday into 200 blocks of the database, but you might pack the primary key values for those order lines into just 20, very stressed, blocks. |
The most significant feature, in fact, is the distributed transaction. High concurrency and packed data invariably lead to problems of scalability, but putting distributed transactions on top of the other two is a sure-fire route to hitting a brick wall. Distributed transactions require a two-phase commit, and two-phase commits introduce a phenomenon that does not appear anywhere else in Oracle -- block-level locking.
Unfortunately, if you are using a TPM, it is very easy to introduce distributed transactions to your system without realising that you are doing so. Fortunately, if you are aware of the danger, it is (probably) possible to avoid the issue. Look at Figure 1 again. If your client program performs a business task that makes use of App Serv 1 and App Serv 7 to record some changes to the system -- perhaps by moving data from the Other DB to the Oracle DB -- then a distributed transaction, and an associated two-phase commit is unavoidable. On the other hand, if your client program performs a business task that makes use of App Serv 1 and App Serv 2 to record some changes to the system -- perhaps one is a customer update and the other is a ledger update -- all the activity is within a single database and you may be forgiven for thinking that your actions would not register as a distributed transaction.
This is where the trap lies -- if you have two application servers connected to an Oracle database, they will be running as two different Oracle sessions. Two different sessions almost invariably means two different local transactions from the database perspective -- even though those two local transactions may be coupled as a single global transaction at the level of the transaction monitors (TM). Oracle is quite clever about recognising that two sessions are involved in the same global transaction. Nevertheless there are various configurations of TPM systems which will allow you (the end-user/programmer) to do something which is clearly dedicated to a single Oracle database, but which will result in the database thinking it is participating in a proper distributed transaction. If this occurs, then the two-phase commit appears, and your scaling problems begin.
The Two-phase Commit
So what is a two-phase commit, and why does it have such a terrible impact? Let's start with a real-world example of what goes wrong without the two-phase commit.
Imagine you are an oil-trader, and you have two other companies on two different phone lines -- one of them is prepared to sell you a cargo (500,000 barrels) of Brent Crude at $19.50 per barrel, the other is prepared to buy at $19.60 per barrel. So you say to the seller 'Done', and as you do, the line to the buyer does dead. You phone them back and when you get through to them a couple of minutes later they say "Sorry, I got a better offer while I was waiting". You are holding $10M of crude oil, an empty bank account, and no buyer in sight. An equally painful, though financially different, problem arises if you say "Done" to the buyer first, you end up committed to supply a boatload of oil with no stock in sight.
So let's introduce the two-phase commit to our oil-trading. You say to the seller "Will you hold at $19.50 for 10 minutes?", if the seller agrees, you go to the buyer and say "If I get back to you inside 10 minutes will you buy at $19.60?". If the buyer agrees you go back the seller and say "Done", then go back to the buyer and say "Done". The worst case scenario is that you say "Done" to the seller, and the phone dies -- you still have 10 minutes to reconnect with the buyer before everything could go wrong.
This is almost exactly the same as the two-phase commit. The transaction manager (TM) is the oil trader in the middle, the databases correspond to the seller and buyer. The first phase of negotiations is called the prepare phase, the second is the commit phase. In principle there is only a very tiny gap between the two phases to minimise the window of opportunity for errors. However, there are two points we haven't yet considered.
One simple, but very important, point is that in the database environment the negotiations in the prepare phase do not include a deadline -- the transaction manager simply travels round each database in turn saying 'can you promise that you will be able to commit when I next get back to you?'; the database sets itself up for the deal, sends back an affirmative, and then waits -- indefinitely -- for the call back.
The second point can best be explained by going back to our oil-traders. Review the situation from the point of the seller -- they can't do anything with their cargo for 10 minutes, it has to be locked up, waiting for you to decide whether or not you are going to buy it. Stranger still, if someone said to them -- "how many cargoes have you sold today?" any answer they gave would be a little ambiguous; for a brief period of time you (the TM, or trader in the middle) know that you have bought it, but they (the seller) do not know that they have sold it.
If we translate this second point into Oracle database terms, it means that not only is the relevant row locked against updates, it is also locked against selects -- the record cannot be read. In fact (for technical reasons relating to the way in which Oracle handles read consistency at the block level) for the period of time between the prepare and the commit, the entire block holding the updated row is locked against both writers and readers. The impact can be devastating.
Design and Test
We said earlier on that one of the features of two-phase commit was that "in principle there is only a very tiny gap between the two phases." In practice, this may be true; but when you have 20 processes busy doing updates, and 50 processes executing queries around a few blocks which are involved in two-phase commits, the "tiny gaps" can add up to a huge amount of lost time.
Look again at Figure 1, and think about the minimum number of steps needed to commit a transaction involving just two application services. A typical sequence of events might be:
| Time | TM sends | App serv 1 sends | App Serv 2 sends |
| T1 | App Serv 1 prepare | ||
| T2 | Prepared | ||
| T3 | App Serv 2 prepare | ||
| T4 | Prepared | ||
| T5 | App Serv 1 commit | ||
| T6 | Committed | ||
| T7 | App Serv 2 commit | ||
| T8 | Committed |
In a busy system, the necessary task-switching that takes place could easily leave a window of several milliseconds between each pair of steps. It sounds small, but it doesn't take a very high degree of concurrency focused on a relatively small number of blocks before the system starts to suffer dramatic time losses. On one recent site visit, I found that there were periods during the day when the overall time loss in this 'tiny window' actually exceeded the time lost waiting for physical I/O. In particular, queries that should have resulted in sub-second response times were occasionally taking as much as ten seconds to complete.
The problem, unfortunately, is terribly pernicious. Even with fairly thorough testing you may fail to notice the problem because it requires concurrency, and the correct data distribution. If your test machine has four CPUs running 150 processes, and your production machine has 16 CPUs running 600 processes, your standard test suite may not generate enough collisions to indicate the potential scale of the problem. You need to know what can go wrong, design a simple harness for your general approach, and then devise a test aimed at stressing the system at the point most likely to cause the problem. For example, you could write two very simple Application Services, each one updating its own one-block table, then prepare an end-user task that repeatedly calls both updates. See what effect multiple copies of this have whilst simultaneously querying the two tables. For the pure technician, the most important symptom to watch out for is the occurrence of TX locks requested in mode 4 -- and you may have to run with a full 10046 trace running as they are likely to come and go very quickly.
The real question, of course, is how you can avoid the problem. The answer depends on the TPM software you are using, and the way in which you have decided to use it.
Any form of persistent queueing (in other words using intermediate files of a format designated by the TPM software to queue information from one system to another) is inevitably going result in two-phase commits -- so try to avoid using persistent queues.
If you have to use persistent queues, consider "over-using" them -- create a clone of the TPM persistent queue inside the Oracle database and use it when transferring from the TPM persistent queue to the Oracle database. Do not transfer data from TPM persistent queue directly into the critical, high activity, areas of the database. This still gives you the potential to suffer from the problem of two-phase commits, but at least it may not be blocking more frequent, and urgent, activities.
Apart from this, the options are very much TPM-dependent. Tuxedo, for example, has a feature that lets you split application services into groups. If a client program calls only services within a single group, then the transaction is recognised by Oracle as a single transaction, and two-phase commit is not required. If a client program calls services from more than one group, then the transaction is considered to be a distributed transaction, and the two-phase commit is invoked.
Conclusion
There are many arguments in favour of accessing your Oracle database through a transaction processing monitor (TPM), but it is possible to introduce distributed transaction processing mechanisms into a system that is not really a distributed system. If this results in a high volume of two-phase commits then the resulting block-level contention could stop the system from scaling to any great degree. It is absolutely critical that you create a proper harness as the first stage of development so that you can build sample test cases quickly and easily to check the side effects of your design strategy.
--
Jonathan Lewis is a freelance consultant with more than 17 years' experience in Oracle. He specialises in physical database design and the strategic use of the Oracle database engine, is author of Practical Oracle 8i - Building Efficient Databases published by Addison-Wesley, and is one of the best-known speakers on the UK Oracle circuit. Further details of his published papers, tutorials, and seminars can be found at www.jlcomp.demon.co.uk, which also hosts The Co-operative Oracle Users' FAQ for the Oracle-related Usenet newsgroups.
Jonathan Lewis
Last modified 2005-04-14 08:44 AM