
Oracle Index Clustering Factor
This article will discuss the relationship between the B-Tree leaf blocks and the table data blocks. This relationship is called “Clustering Factor.” The more blocks an index leaf block points to, the lower the clustering factor, and the better performance you will receive using indexes on range scans. I have permission from Oracle expert Jonathan Lewis (www.jlcomp.demon.co.uk) to use his Table1 and Table2 examples to illustrate index clustering factor.
There are several reasons Oracle cost-based optimizer (CBO) might not be picking the right index: Have you checked the indexes clustering factor? Are your statistics up to date? (These statistics are stored in DBA_INDEXES.) If your index clustering factor is high, Oracle CBO will also not use an index, even though it might be an obvious choice to you.
Clustering factor is the relationship between the index leaf blocks and the data blocks they point to. If the key value of the index is the rough order of the underlying table, then the clustering factor will be low (close to the same number of data blocks in the underlying table), since the key values in the leaf blocks will point to one or a couple of data blocks. If the clustering factor is high (close to the same number of rows in the underlying table), as in the index value in the table is in a completely different order than the index key value ... then a single index leaf block could point to hundreds of different data blocks.
This really matters if your application is looking for indexes to range scan or your SQL code has a GROUP BY or ORDER BY clause.
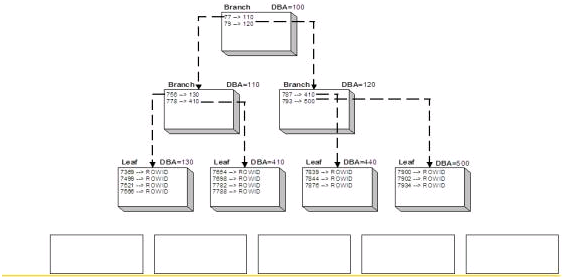
Example 1: B-Tree index illustration.
Example 1 shows a small B-Tree index structure with a row of table data blocks beneath it. Let’s review how this might work for the EMP table. Let’s say that it is loaded primarily by EMPNO. The index on EMPNO would have a very low clustering factor since the table and the index are in the same order; the index leaf blocks would point to just a single data block. In the previous example, think of each leaf block pointing to a single data block. Range-scanning, or accessing multiple rows via the index, would result in very few I/O operations on the underlying table. If we had this same EMP table in EMPNO order and you added an index on HIREDATE, each leaf pointer in the index could potentially point to a different data block, giving a very high clustering factor. In this example, it would be easier for Oracle to simply read the table using a full-table scan operation rather than performing the multiple I/O operations to read and re-read data blocks.
Oracle CBO looks at clustering factor to see if it is just plain easier to return all the rows via full table scan. Indexes with high clustering factor are not generally used for range scans. If you are doing single row lookups, the clustering factor simply doesn’t matter.
When you run statistics on an index, Oracle collects many things and it collects clustering factor. It watches the rowids as it scans the index and increments clustering factor each time the block number of the rowid changes. So, if the table is in the same sequence as the index key values, when it looks at this block number in rowid, the block number will only occasionally change. If the table is in a different sequence than the index key value, the block number of the rowid will change with practically every key.
Think of it this way: using an index on a range scan, just how many underlying data blocks will Oracle have to retrieve using an index versus a full table scan? This is what the CBO gets from the clustering factor statistic.
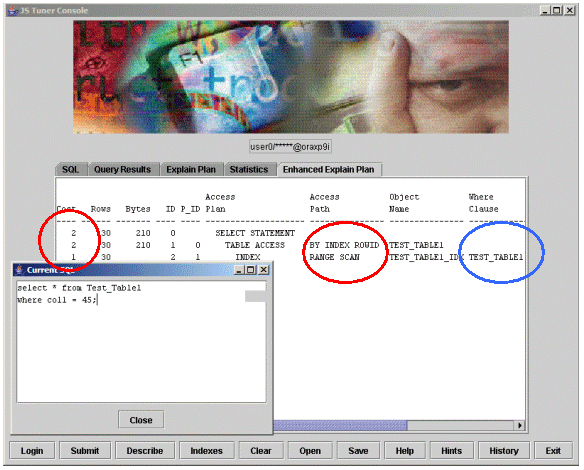
Example 2: Table1 access by index.
Let’s look at an example. Table1 and Table2 have the same characteristics, same column names, same data types, and same number of rows. Each table has 30 rows of each key value. Each table has 6000 rows.
Notice in Example 2 that we are selecting key value 45 from Table 1, and it indeed returned 30 rows and used an index (see red circles). It had a cost-factor of 2 (In Oracle8i, this means that Oracle thinks it would take roughly two I/O operations to satisfy this query): an I/O operation on the index and an I/O operation on the table.
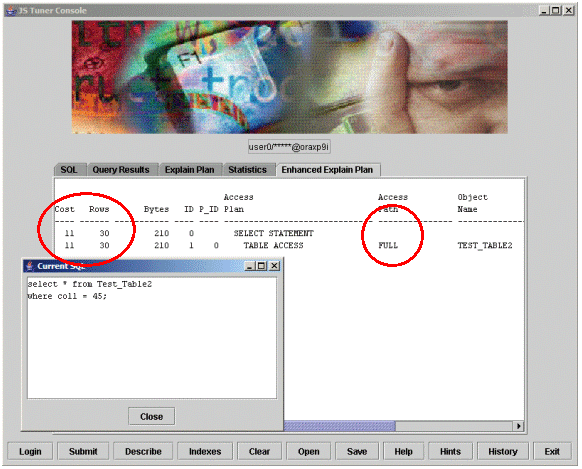
Example 3: Table2 full-table scan access.
Example 3 illustrates what happens when we request the same information from Table2. Notice in the red circles this time that Oracle chose to do a full table scan on Table2, even though it had the same index available as in Table1. Notice that the cost-factor is 11, or Oracle thinks it will have to do 11 I/O operations to select this data from Table2.
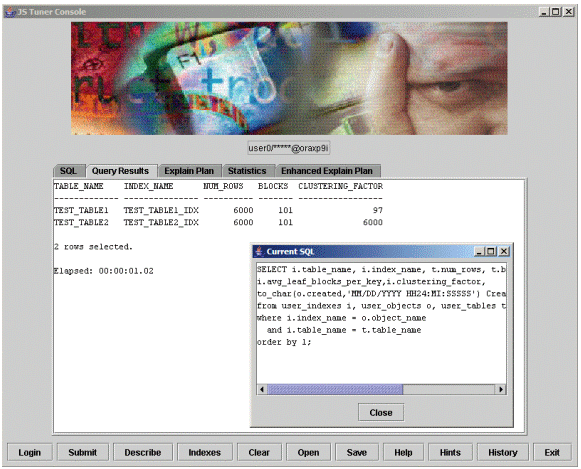
Example 4: Index_Info.SQL.
I have a script I call Index_Info.SQL. Again it comes with permission from Jonathan Lewis; I did modify the script to add additional information. This script is available from the download section of my website.
Notice the output of the script in Example 4. We can see that both tables have 6000 rows and both tables have 101 blocks. Notice the clustering factor though … 97 for Table1 and 6000 for Table2! Table2’s clustering factor could not be worse!
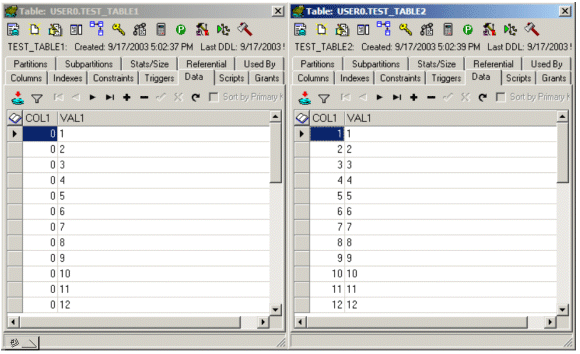
Example 5: Table1 (left) and Table2 (right) data using TOAD.
Table1 and Table2 have the same data. Both tables have the column “col1,” which contains values of 0 through 199, 30 rows per value. Table1 is in order these values, all the 0’s are together, all the ones are together, and so on. This is why we have such a low clustering factor. All 30 rows fit in a single data block. Table2, the table was created with the same col1 values: 0 through 199 but it was loaded 0 through 199: 30 times. So the blocks have 0, 1, 2, 3 … 199, 0, 1, 2, 3…: 30 sets of the data loaded like this. The data could not be more skewed, and this is what caused our high clustering factor. Each index block points to 30 different data blocks, completely useless to Oracle on a range scan. Example 5 illustrates how the data appears in the tables.
Let's prove this theory.
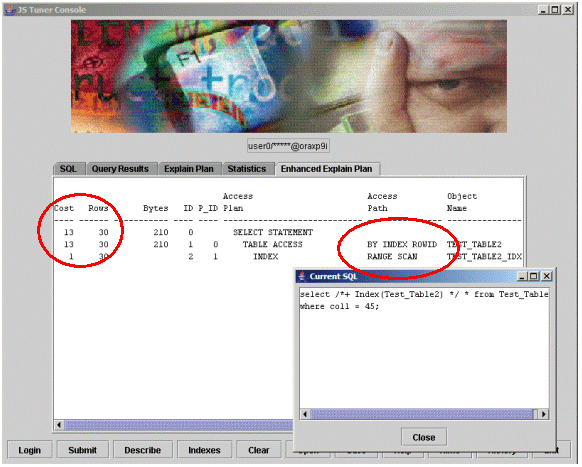
Example 6: Table2 with an index hint.
Let’s add a hint to Table2 to request that it use the index anyway. Notice in Example 6 that Oracle did indeed use the index (see the red circle on the right), but at a higher cost.
Data design plays an important factor in application performance. Data design also plays an important part in whether Oracle will use indexes or not. Indexes with poor clustering factors will never be used by Oracle. Design your applications with the most important function in mind. Make sure that the data in the table is inserted in that order, and that there is an index on that same column. This will return the best performance using range scans, Order By, and Group By functions.
--
Dan Hotka is a Training Specialist who has over 27 years in the computer industry and over 22 years of experience with Oracle products. He is an internationally recognized Oracle expert with Oracle experience dating back to the Oracle V4.0 days. Dan's latest book is the Oracle10g on Linux by Oracle Press. He is also the author of Oracle9i Development By Example and Oracle8i from Scratch by Que and has co-authored 6 other popular books. He is frequently published in Oracle trade journals, and regularly speaks at Oracle conferences and user groups around the world. Visit his website at www.DanHotka.com. Dan can be reached at dhotka@earthlink.net.
Contributors : Dan Hotka, Jonathan Lewis
Last modified 2005-09-16 10:45 AM