
SmartDBA Tips
DBAzine Oracle Tip #16: Identifying High Disk Sorts Over Time
If Oracle is doing too many disk sorts, performance can be dramatically affected. The sort_area_size init.ora parameter (or pga_aggregate_target in Oracle9i) controls the amount of RAM available for sorting purposes. When RAM space is exceeded, Oracle must continue the sorting task in the temporary tablespace, which can be up to 15,000 times slower than in-memory sorts.
This script detects the overall sort activity for an Oracle database since it was started:
set pages 9999;
column value format 999,999,999
select
name,
value
from
v$sysstat
where
name like 'sort%';
This does not give us log-term trend information so, using the STATSPACK utility, we can use the following script to determine the times when the database has more than 100 disk sorts per hour.
column sorts_memory format 999,999,999
column sorts_disk format 999,999,999
column ratio format .9999999999999select
to_char(snap_time,'yyyy-mm-dd HH24'),
newmem.value-oldmem.value sorts_memory,
newdsk.value-olddsk.value sorts_disk,
(newdsk.value-olddsk.value)/(newmem.value-oldmem.value) ratio
from
perfstat.stats$sysstat oldmem,
perfstat.stats$sysstat newmem,
perfstat.stats$sysstat newdsk,
perfstat.stats$sysstat olddsk,
perfstat.stats$snapshot sn
where
where
-- Where there are more than 100 disk sorts per hour
newdsk.value-olddsk.value > 100
and
snap_time > sysdate-&1
and
newdsk.snap_id = sn.snap_id
and
olddsk.snap_id = sn.snap_id-1
and
newmem.snap_id = sn.snap_id
and
oldmem.snap_id = sn.snap_id-1
and
oldmem.name = 'sorts (memory)'
and
newmem.name = 'sorts (memory)'
and
olddsk.name = 'sorts (disk)'
and
newdsk.name = 'sorts (disk)'
and
newmem.value-oldmem.value > 0
;
Here is a sample of the output from this script.
TO_CHAR(SNAP_ SORTS_MEMORY SORTS_DISK RATIO
------------- ------------ ------------ ---------------
2001-02-04 08 6,425 141 .0219455252918
2001-02-04 09 6,539 145 .0221746444410
2001-02-04 10 6,413 149 .0232340558241
2001-02-04 11 6,407 141 .0220071796473
2001-02-05 12 6,473 149 .0230186930326
2001-02-05 10 6,475 147 .0227027027027
2001-02-05 11 6,572 145 .0220632988436
2001-02-06 10 90,385 130 .0014382917519
2001-02-06 11 6,648 147 .0221119133574
Here is how to use STATSPACK to compute the average number of disk sorts by the day of the week.
set pages 9999;
column sorts_memory format 999,999,999
column sorts_disk format 999,999,999
column ratio format .99999
select
to_char(snap_time,'day') DAY,
avg(newmem.value-oldmem.value) sorts_memory,
avg(newdsk.value-olddsk.value) sorts_disk
from
perfstat.stats$sysstat oldmem,
perfstat.stats$sysstat newmem,
perfstat.stats$sysstat newdsk,
perfstat.stats$sysstat olddsk,
perfstat.stats$snapshot sn
where
newdsk.snap_id = sn.snap_id
and
olddsk.snap_id = sn.snap_id-1
and
newmem.snap_id = sn.snap_id
and
oldmem.snap_id = sn.snap_id-1
and
oldmem.name = 'sorts (memory)'
and
newmem.name = 'sorts (memory)'
and
olddsk.name = 'sorts (disk)'
and
newdsk.name = 'sorts (disk)'
and
newmem.value-oldmem.value > 0
group by
to_char(snap_time,'day')
;
Here is the result set, plotting Oracle disk sorts by day.
DAY SORTS_MEMORY SORTS_DISK
--------- ------------ ------------
friday 12,545 54
monday 14,352 29
saturday 12,430 2
sunday 13,807 4
thursday 17,042 47
tuesday 15,172 78
wednesday 14,650 43
DBAzine Oracle Tip #15: Checking for Oracle File Wait Conditions
submitted by Donald K. Burleson
Oracle records statistics that track the wait_count for all data files. The basic information for determining files that are experiencing I/O-based contention can be found in the V$WAITSTAT view. However, STATSPACK users can query the stats$filestatxs table and create reports that display waiting files. The following script can be run to detect files that have more than 800 wait events per hour.
break on snapdate skip 2column snapdate format a16
column filename format a40select
to_char(snap_time,'yyyy-mm-dd HH24') snapdate,
old.filename,
new.wait_count-old.wait_count waits
from
perfstat.stats$filestatxs old,
perfstat.stats$filestatxs new,
perfstat.stats$snapshot sn
where
snap_time > sysdate-&1
and
new.wait_count-old.wait_count > 800
and
new.snap_id = sn.snap_id
and
old.filename = new.filename
and
old.snap_id = sn.snap_id-1
and
new.wait_count-old.wait_count > 0
;
Here is a sample listing from this script. Knowing when a database is experiencing excessive wait conditions can be very valuable.
***********************************************************
When there is high I/O waits, disk bottlenecks may exist
Run iostats to find the hot disk and shuffle files to
remove the contention
***********************************************************SNAPDATE FILENAME WAITS
---------------- ---------------------------------------- ----------
2001-01-28 23 /u03/oradata/PROD/applsysd01.dbf 2169
/u04/oradata/PROD/applsysx01.dbf 1722
/u03/oradata/PROD/rbs01.dbf 2016
2001-01-30 16 /u03/oradata/PROD/mrpd01.dbf 1402
2001-01-31 23 /u03/oradata/PROD/applsysd01.dbf 4319
/u04/oradata/PROD/applsysx01.dbf 3402
DBAzine Oracle Tip #14: Finding the Number of CPUs on Your Oracle Server
submitted by Donald K. Burleson
To efficiently use Oracle Parallel Query (OPQ) as well as parallel DML, an Oracle professional must know how many CPUs are on the database server. While Oracle knows the number of CPUs at install time, knowing the cpu_count is useful to set the degree of parallelism. Here is a handy list of commands that are used to obtain this information from several different types of Oracle database servers.
Windows NT — If you are using MS-Windows NT you can find the number of CPUs by entering the control panel and choosing the system icon.
Linux — To see the number of CPUs on a Linux server, you can cat the /proc/cpuinfo file. In the example below we see that our Linux server has 4 CPUs.
>cat /proc/cpuinfo|grep processor|wc -l
4
Solaris — In Sun Solaris the prsinfo command can be used to count the number of CPUs on the processor.
>psrinfo -v|grep "Status of processor"|wc -l
24
IBM-AIX — The following example is taken from an AIX server, and shows that the server has four CPUs:
>lsdev -C|grep Process|wc –l36
HP/UX — In HP Unix, you can use the “glance” or “top” utilities to display the number of CPUs, or you can issue this UNIX command.
> ioscan -C processor | grep processor | wc -l
36
DBAzine Oracle Tip #13: How to Count the Number of Blocks in Each Freelist Group for a Table
submitted by Donald K. Burleson
It is possible to define multiple freelists for highly active tables. This allows multiple transactions to access free blocks from the segment header to insert rows into tables without causing buffer busy waits or segment header contention.
There are times when freelists become unbalanced since freelists cannot share free blocks. For instance, multiple tasks are inserting rows into the table, but a single task deletes a row. This is called, “sparse table phenomenon.” The table continues to extend, even though the dba_segments view shows a lot of free blocks in the table.
To find out how much free space is left in a table or index, it is possible ANALYZE the object to get relevant information. However, the following script will walk the freelists chains on the tables and provide you the relative number of free blocks on each freelist chain without the overhead of ANALYZE. If the result of this script shows a serious imbalance, you should reorganize the table to coalesce the freelists.
set serveroutput on;
DECLARE
x number;
cursor c1 is
select
substr(table_name,1,13) table_name,
substr(a.owner,1,13) owner
from
dba_tables a, dba_segments b
where
a.table_name = b.segment_name
and
b.extents > 1
and
a.freelist_groups > 1
and
b.extents > a.min_extents
and
empty_blocks > 3*(a.next_extent/4096)
and
a.owner not in ('SYS','SYSTEM');
BEGIN
FOR c1rec in c1
LOOP
dbms_space.free_blocks(c1rec.owner, c1rec.table_name, 'TABLE', 01, x );
dbms_output.put('Number of free list group 1 entries for table ');
dbms_output.put(c1rec.owner);
dbms_output.put('.');
dbms_output.put(c1rec.table_name);
dbms_output.put(' is ');
dbms_output.put_line(x);
dbms_space.free_blocks(c1rec.owner, c1rec.table_name, 'TABLE', 02, x );
dbms_output.put('Number of free list group 2 entries for table ');
dbms_output.put(c1rec.owner);
dbms_output.put('.');
dbms_output.put(c1rec.table_name);
dbms_output.put(' is ');
dbms_output.put_line(x);
dbms_output.put_line('.');
END LOOP;
END;
/
DBAzine Oracle Tip #12: Approximating Average Updates per Second in Oracle
submitted by Donald K. Burleson
Oracle issues a new SCN every time data file contents are changed which approximates a database update. You can track the number of System Change Numbers (SCNs) over time with the Oracle v$log_history view. This script is based on counting the number of SCNs, which approximates the number of DML statements performed by the database.
set pages 60
set lines 132
spool trans.lst
col dml00 heading "00" format 999
col dml01 heading "01" format 999
col dml02 heading "02" format 999
col dml03 heading "03" format 999
col dml04 heading "04" format 999
col dml05 heading "05" format 999
col dml06 heading "06" format 999
col dml07 heading "07" format 999
col dml08 heading "08" format 999
col dml09 heading "09" format 999
col dml10 heading "10" format 999
col dml11 heading "11" format 999
col dml12 heading "12" format 999
col dml13 heading "13" format 999
col dml14 heading "14" format 999
col dml15 heading "15" format 999
col dml16 heading "16" format 999
col dml17 heading "17" format 999
col dml18 heading "18" format 999
col dml19 heading "19" format 999
col dml20 heading "20" format 999
col dml21 heading "21" format 999
col dml22 heading "22" format 999
col dml23 heading "23" format 999
select
*
from
(
select
substr(first_date,1,8) timestamp_np,
substr(first_date,5,2) Mon, substr(first_date,7,2) Day,
sum(decode(substr(first_date,9,2),'00',1,0) * tps) dml00,
sum(decode(substr(first_date,9,2),'01',1,0) * tps) dml01,
sum(decode(substr(first_date,9,3),'02',1,0) * tps) dml02,
sum(decode(substr(first_date,9,2),'03',1,0) * tps) dml03,
sum(decode(substr(first_date,9,2),'04',1,0) * tps) dml04,
sum(decode(substr(first_date,9,3),'05',1,0) * tps) dml05,
sum(decode(substr(first_date,9,2),'06',1,0) * tps) dml06,
sum(decode(substr(first_date,9,2),'07',1,0) * tps) dml07,
sum(decode(substr(first_date,9,3),'08',1,0) * tps) dml08,
sum(decode(substr(first_date,9,2),'09',1,0) * tps) dml09,
sum(decode(substr(first_date,9,2),'11',1,0) * tps) dml10,
sum(decode(substr(first_date,9,3),'11',1,0) * tps) dml11,
sum(decode(substr(first_date,9,3),'12',1,0) * tps) dml12,
sum(decode(substr(first_date,9,2),'13',1,0) * tps) dml13,
sum(decode(substr(first_date,9,2),'14',1,0) * tps) dml14,
sum(decode(substr(first_date,9,3),'15',1,0) * tps) dml15,
sum(decode(substr(first_date,9,2),'16',1,0) * tps) dml16,
sum(decode(substr(first_date,9,2),'17',1,0) * tps) dml17,
sum(decode(substr(first_date,9,3),'18',1,0) * tps) dml18,
sum(decode(substr(first_date,9,2),'19',1,0) * tps) dml19,
sum(decode(substr(first_date,9,2),'20',1,0) * tps) dml20,
sum(decode(substr(first_date,9,3),'21',1,0) * tps) dml21,
sum(decode(substr(first_date,9,3),'22',1,0) * tps) dml22,
sum(decode(substr(first_date,9,2),'23',1,0) * tps) dml23
from
(select
to_char(first_time,'YYYYMMDDHH24') first_date,
(max(next_change#) - min(first_change#))/(60 * 60) tps
from
v$log_history
group by
to_char(first_time,'YYYYMMDDHH24')
)
group by
substr(first_date,1,8),
substr(first_date,5,2),
substr(first_date,7,2)
)
order by
timestamp_np
;
spool off;
host notepad trans.lst
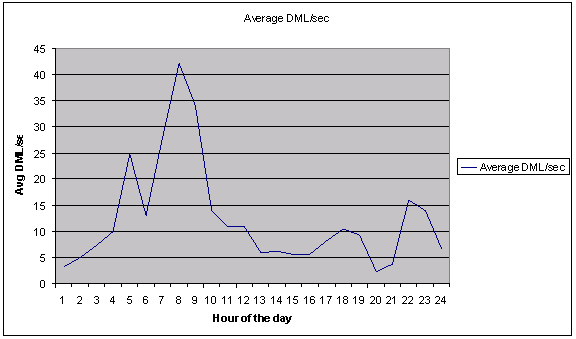
Once you get the output, you can quickly plot it using the chart wizard of a spreadsheet.
DBAzine Oracle Tip #11: Fast and Easy SQL Execution Plan in Oracle
submitted by Donald K. Burleson
Prior to Oracle8i, if you wanted to view the execution plan and trace information for an SQL statement, you had to create a plan table and execute special syntax. And for detailed statistics, you had to run the TKPROF utility.
Using SQL*Plus commands in Oracle 9i, we can get the execution plan and trace information for any SQL statement very quickly and easily.
Set autotrace on explain - Running this SQL*Plus directive will execute your SQL query and also provide the execution plan for the SQL statement. An Explain Plan is a diagram generated by ORACLE to show the links used in the execution of a SQL Script. It shows which tables were accessed, how they were accessed, for what purpose, and which (if any) indexes were used. Execution plans for Oracle SQL can be very complex, but the Oracle Press book “Oracle High-performance SQL tuning” provides complete instruction on how to interpret and tune SQL statement execution plans.
Set autotrace on - The “set autotrace on” command will provide detailed statistics for the Oracle SQL and show the amount of time spent parsing, executing and fetching rows. The parse phase is the time spent by the query determining the optimal execution plan, and this phase can be quite high for queries with more than 5 tables unless the ORDERED or RULE HINTS are used. The execution phase is the time spent executing the query, and the fetch phase is the time spent returning the rows to the query.
Here is an example in SQL*Plus:
set autotrace traceonly explain;select
pub_name,
book_title
from
publisher,
book
where
publisher.pub_key = book.pub_key
order by
pub_name
;Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=7 Card=20 Bytes=1440
)
1 0 SORT (ORDER BY) (Cost=7 Card=20 Bytes=1440)
2 1 HASH JOIN (Cost=3 Card=20 Bytes=1440)
3 2 TABLE ACCESS (FULL) OF 'PUBLISHER' (Cost=1 Card=10 Bytes=260)
4 2 TABLE ACCESS (FULL) OF 'BOOK' (Cost=1 Card=20 Bytes=920)
These new SQL*Plus directives can make it very easy for the Oracle professional to ensure that their SQL statements are properly tuned. Remember that the hallmark of a good developer is someone who can not only make SQL statements, but also make SQL that executes very quickly.
DBAzine Oracle Tip #10: Advanced Job Scheduling with dbms_job
submitted by Donald K. Burleson
With the advanced scheduling features within Oracle a common question is: “How do I submit a dbms_job to execute an hourly statspack.snap from 6 AM - 11 PM, Monday through Friday? Is this beyond the capabilities of the DBMS_JOB package?”
Review:
The dbms_job.submit procedure accepts three parameters:
- The name of the job to submit
- The start time for the job
- The interval to execute the job
For example:
dbms_job.submit(
what=>'statspack_alert.sql;',
next_date=>sysdate+1/24, -- start next hour
interval=>'sysdate+1/24'); -- Run every hour
This job specifies the initial start time and re-execution interval, but does not have a mechanism for running the job during predetermined hours during the day. To get time intervals, two other jobs are needed, one to “break” the job at 5:00 PM and another to un-break the job the following morning at 8:00 AM.
Here are several examples of jobs for advanced scheduling:
--
-- Schedule a snapshot to be run on this instance every hour
variable jobno number;
variable instno number;
begin
select instance_number into :instno from v$instance;
-- ------------------------------------------------------------
-- Submit job to begin at 0600 and run every hour
-- ------------------------------------------------------------
dbms_job.submit(
:jobno, 'statspack.snap;',
trunc(sysdate)+6/24,
'trunc(SYSDATE+1/24,''HH'')'
TRUE,
:instno);
-- ------------------------------------------------------------
-- Submit job to begin at 0900 and run 12 hours later
-- ------------------------------------------------------------
dbms_job.submit(
:jobno,
'statspack.snap;',
trunc(sysdate+1)+9/24,
'trunc(SYSDATE+12/24,''HH'')',
TRUE,
:instno);
-- ------------------------------------------------------------
-- Submit job to begin at 0600 and run every 10 minutes
-- ------------------------------------------------------------
dbms_job.submit(
:jobno,
'statspack.snap;',
trunc(sysdate+1/144,'MI'),
'trunc(sysdate+1/144,''MI'')',
TRUE,
:instno);
-- ----------------------------------------------------------------
-- Submit job to begin at 0600 and run every hour, Monday - Friday
-- ----------------------------------------------------------------
dbms_job.submit(
:jobno,
'statspack.snap;',
trunc(sysdate+1)+6/24,
'trunc(
least(
next_day(SYSDATE,''MONDAY''),
next_day(SYSDATE,''TUESDAY''),
next_day(SYSDATE,''WEDNESDAY''),
next_day(SYSDATE,''THURSDAY''),
next_day(SYSDATE,''FRIDAY'')
)
+1/24,''HH'')',
TRUE,
:instno);
commit;
end;
/
DBAzine Oracle Tip #9: Pinning the Oracle Packages with Start-up Triggers
submitted by Donald K. Burleson
The introduction of system-level triggers in Oracle8i provides us with an easy tool to ensure that frequently executed PL/SQL remains cached in the shared pool. Similar to the KEEP pool with data buffer caches, the pinning of packages ensures the specified package always remains in the Most-Recently-Used end of the data buffer. This prevents the PL/SQL from being paged-out and re-parsed upon reload. Control the size of this RAM region by setting the shared_pool_size parameter to a value large enough to hold all of the PL/SQL.
Two areas are involved in pinning packages:
-
Pinning frequently executed packages – Pinning frequently executed packages in the SGA can greatly enhance performance.
-
Pinning the standard Oracle packages – These should always be pinned to prevent re-parsing by the Oracle SGA. See the code listing below.
You can interrogate the v$db_object_cache view to see the most frequently used packages, and automatically pin them at database start-up time (with an ON DATABASE STARTUP trigger) using dbms_shared_pool.keep.
Use the v$db_object_cache view and dbms_shared_pool.keep to see the most frequently used packages. Automatically pin them at database start-up time with an ON DATABASE STARTUP trigger.
create or replace trigger
pin_packs
after startup on database
begin
execute dbms_shared_pool.keep('DBMS_ALERT');
execute dbms_shared_pool.keep('DBMS_DDL');
execute dbms_shared_pool.keep('DBMS_DESCRIBE');
execute dbms_shared_pool.keep('DBMS_LOCK');
execute dbms_shared_pool.keep('DBMS_OUTPUT');
execute dbms_shared_pool.keep('DBMS_PIPE');
execute dbms_shared_pool.keep('DBMS_SESSION');
execute dbms_shared_pool.keep('DBMS_SHARED_POOL');
execute dbms_shared_pool.keep('DBMS_STANDARD');
execute dbms_shared_pool.keep('DBMS_UTILITY');
execute dbms_shared_pool.keep('STANDARD');
end;
DBAzine Oracle Tip #8: Adding Custom Messages to the Oracle Alert Log
submitted by Donald K. Burleson
Oracle databases append all errors and warnings to an ASCII file called the Oracle Alert file. To simplify database administration, you can consolidate all Oracle messages (both system messages and application messages) into one central file. In order to create this single message repository, you must develop a method for writing application messages into the Alert file.
As a DBA, you can create a global PL/SQL stored procedure to handle this interaction with the Alert file. The global package can be called, passing the appropriate message to the procedure. The following example shows this type of call.
when others then
dbms_custom.write_alert(:p_sysdate||‘ Error’||:var1||’ encountered’);
Use Oracle’s utl_file package to easily accomplish writing to the alert log. With the utl_file package you can read and write directly from flat files on the server with Oracle SQL and PL/SQL.
Here are the steps to write custom messages to the Oracle alert log:
- Locate the background dump directory (the location of the alert log).
- Set the utl_file_dir initialization parameter.
- Execute utl_file.fopen to open the file for write access.
- Use dbms_output.put_line to write the custom message to the alert log.
- Execute utl_file.fclose to close the file
Here is a code sample that illustrates the process:
-- ******************************************************
-- Gather the location of the alert log directory
-- ******************************************************
select
name into :alert_loc
from
v$parameter
where
name = ‘background_dump_destination’;
-- ******************************************************
-- Set the utl_file_dir
-- (prior to Oracle9i, you must bounce the database)
-- ******************************************************
alter system set utl_file_dir = ‘:alert_log’);
-- ******************************************************
-- Open the alert log file for write access
-- ******************************************************
utl_file.fopen(':alert_loc',’alertprod.log’,'W');
-- ******************************************************
-- Write the custom message to the alert log file
-- ******************************************************
dbms_output.put_line('invalid_application_error');
-- ******************************************************
-- Close the alert log file
-- ******************************************************
utl_file.fclose(':alert_loc');
DBAzine Oracle Tip #7: Auditing Oracle DDL with the Data Dictionary
submitted by Donald K. Burleson
One of the things an Oracle DBA needs to know while monitoring activity within a database is when a table or index was created. Within the DBA_OBJECTS view, there is a new column called CREATED that can be used to display the date an object was created.
The following script produces a report showing all tables and indexes that were created within the past 14 days. This can be a critical report in a production environment when an audit of DDL must be kept.
alter session set nls_date_format='YY-MON-DD HH24';
set pages 999column c1 heading 'Date/time|created'
column c2 heading 'Object|Type' format a20
column c3 heading 'Object|Name' format a40select
created c1,
object_type c2,
object_name c3
from
dba_objects
where
created > sysdate-14
order by
created desc;
Here is a sample of the report that shows complete statistics for all recent create DDL statements.
Date/time Object Object
Created Type Name
------------ -------------------- -------------------------------------
02-FEB-27 07 TABLE ORACHECK_FS_TEMP
02-FEB-26 10 TABLE GL_TRANSLATION_INTERIM
02-FEB-26 10 INDEX GL_TRANSLATION_INTERIM_N1
02-FEB-26 10 SYNONYM GL_TRANSLATION_INTERIM
02-FEB-26 10 INDEX GL_POSTING_INTERIM_N1
02-FEB-26 10 SYNONYM GL_POSTING_INTERIM
02-FEB-26 10 INDEX GL_POSTING_INTERIM_N2
02-FEB-26 10 TABLE GL_POSTING_INTERIM
02-FEB-25 08 PROCEDURE MC_LOAD_RESOURCE
02-FEB-20 15 VIEW MC_MPS_BREAKUP
02-FEB-15 13 DATABASE LINK TEST2.WORLD
02-FEB-15 12 DATABASE LINK TEST.WORLD
DBAzine Oracle Tip #6: Viewing RAM Memory Usage for specific SQL Statements in Oracle9i
submitted by Donald K. Burleson
Oracle9i has the ability to display RAM memory usage along with execution plan information. To get this information, we query the v$sql view to gather the address of the desired SQL statement. In the following example, use this query to obtain the address of a query that operates against the NEW_CUSTOMER table.
select
address
from
v$sql
where
sql_text like ‘%NEW_CUSTOMER’;88BB460C
1 row selected.
We can now plug the address into the following script to get the execution plan details and the PGA memory usage for the SQL statement.
select
operation,
options,
object_name name,
trunc(bytes/1024/1024) "input(MB)",
trunc(last_memory_used/1024) last_mem,
trunc(estimated_optimal_size/1024) opt_mem,
trunc(estimated_onepass_size/1024) onepass_mem,
decode(optimal_executions, null, null,
optimal_executions||'/index.html'||onepass_executions||'/index.html'||
multipasses_exections) "O/1/M"
from
v$sql_plan p,
v$sql_workarea w
where
p.address=w.address(+)
and
p.hash_value=w.hash_value(+)
and
p.id=w.operation_id(+)
and
p.address='88BB460C';
Here is the output from this script showing details about the execution plan along with specific memory usage details.
OPERATION OPTIONS NAME input(MB) LAST_MEM OPT_MEM ONEPASS_MEM O/1/M
------------ -------- ---- --------- -------- ------- ---------- ----
SELECT STATE
SORT GROUP BY 4582 8 16 16 26/0/0
HASH JOIN SEMI 4582 5976 5194 2187 16/0/0
TABLE ACCESS FULL ORDERS 51
TABLE ACCESS FULL LINEITEM 1000
This is a very exciting new advance in Oracle9i. It gives the DBA the ability to see a very high level of detail about the internal execution of any SQL statement.
DBAzine Oracle Tip #5: Using the New Oracle9i v$pgastat View
submitted by Donald K. Burleson
The v$pgastat view shows the total amount of RAM memory utilization for every RAM memory region within the database. This information can tell you the high water mark of RAM utilization, and allow you to size RAM memory demands according to the relative stress on the system. Here is a simple query against v$pgastat:
column name format a30
column value format 999,999,999select
name,
value
from
v$pgastat
;
The output of this query might look like the following:
NAME VALUE
------------------------------------------------------ ----------
aggregate PGA auto target 736,052,224
global memory bound 21,200
total expected memory 141,144
total PGA inuse 22,234,736
total PGA allocated 55,327,872
maximum PGA allocated 23,970,624
total PGA used for auto workareas 262,144
maximum PGA used for auto workareas 7,333,032
total PGA used for manual workareas 0
maximum PGA used for manual workareas 0
estimated PGA memory for optimal 141,395
maximum PGA memory for optimal 500,123,520
estimated PGA memory for one-pass 534,144
maximum PGA memory for one-pass 52,123,520
In the above display from v$pgastat we see the following statistics.
- Aggregate PGA auto target – This statistic provides the total amount of available memory for Oracle9i connections. This value is derived from the value on the init.ora parameter pga_aggregate_target.
- Global memory bound – This statistic measures the max size of a work area, and Oracle recommends that the value of the pga_aggregate_target parameter be increased whenever this statistics drops below one megabyte.
- Total PGA allocated – This statistic shows the high-water mark of all PGA memory usage on the database. As usage increases, you should see this value approach the value of pga_aggregate_target.
- Total PGA used for auto workareas – This statistic monitors RAM consumption or all connections that are running in automatic memory mode. All internal processes may not use the automatic memory feature. For example, Java and PL/SQL will allocate RAM memory, but this will not be counted in this statistic. Hence, we can subtract value to the total PGA allocated to see the amount of memory used by connections and the RAM memory consumed by Java and PL/SQL.
- Estimated PGA memory for optimal/one-pass – This statistic estimates how much memory is required to execute all task connections RAM demands in optimal mode. Remember that when Oracle9i experiences a memory shortage, it will invoke the multi-pass operation. This statistics is crucial for monitoring RAM consumption in Oracle9i, and most Oracle DBA’s will increase pga_aggregate_target to this value.
DBAzine Oracle Tip #4: Finding Chained Rows in Oracle Tables
submitted by Donald K. Burleson
Detecting and repairing chained rows is an important part of Oracle Administrator’s job. The more chaining you have the more performance problems for application software you may find since excessive row chaining causes a dramatic increase in the disk I/O required to fetch a block of data.
Note: Setting the PCTFREE storage parameter high enough to keep space on each data block for row expansion can reduce row chaining. However, the tradeoff is in space usage. If PCTUSED is set to a high value, such as 80, a block will more quickly become available to accept new rows, however it will not have room for a lot of rows before it is logically full again.
Row chaining may be unavoidable where the data columns contain RAW and LONG RAW columns because the average row length may exceed the data block size. Consequently the query below filters out tables with RAW data types.
This code generates a report showing tables with excessively chained rows. It uses Oracles ANALYZE command to populate the chain_cnt and num_rows columns of the DBA_TABLES data dictionary view.
Use the Create Table As Select (CTAS) or Oracle export-import utilities to reorganize affected tables.
spool chain.lst;
set pages 9999;column c1 heading "Owner" format a9;
column c2 heading "Table" format a12;
column c3 heading "PCTFREE" format 99;
column c4 heading "PCTUSED" format 99;
column c5 heading "avg row" format 99,999;
column c6 heading "Rows" format 999,999,999;
column c7 heading "Chains" format 999,999,999;
column c8 heading "Pct" format .99;set heading off;
select 'Tables with chained rows and no RAW columns.' from dual;
set heading on;select
owner c1,
table_name c2,
pct_free c3,
pct_used c4,
avg_row_len c5,
num_rows c6,
chain_cnt c7,
chain_cnt/num_rows c8
from
dba_tables
where
owner not in ('SYS','SYSTEM')
and
table_name not in
(select table_name from dba_tab_columns
where
data_type in ('RAW','LONG RAW')
)
and
chain_cnt > 0
order by
chain_cnt desc
;
Here is the report showing the tables you will want to reorganize:
Owner Table PCTFREE PCTUSED avg row Rows Chains Pct
--------- ------------ ------- ------- ------- ------------ ------------ ----
SAPR3 ZG_TAB 10 40 80 5,003 1,487 .30
SAPR3 ZMM 10 40 422 18,309 509 .03
SAPR3 Z_Z_TBLS 10 40 43 458 53 .12
SAPR3 USR03 10 40 101 327 46 .14
SAPR3 Z_BURL 10 40 116 1,802 25 .01
SAPR3 ZGO_CITY 10 40 56 1,133 10 .016 rows selected.
DBAzine Oracle Tip #3: Display Oracle Sessions that are Waiting for Block Access
submitted by Donald K. Burleson
Each segment (table, index) within Oracle has one segment header block. When a row is inserted into a table or index, Oracle goes to the first block in the table to grab a freelist to get the address of a free block on the table. The freelist indicates where there is a free data block in which to place the row. Multiple inserts on a table with insufficient transaction freelists can result in "buffer busy waits." A wait situation in a buffer occurs when an Oracle process attempts to access a block that is still in an inconsistent status.
Although buffer busy waits are very transient, they can add-up to a real performance problem. If you suspect a table does not have enough freelists, try running this script every 5 minutes.
prompt
prompt
prompt **********************************************************
prompt Session summary by tablespace Section
prompt **********************************************************
prompt This is a summary of activity by tablespace
prompt high buffer busy waits may indicate the need for more freelists
column c0 heading 'tablespace' format a14;
column c1 heading 'event' format a25;
column c2 heading 'tot waits' format 999,999;
column c3 heading 'tot timeouts' format 999,999;
column c4 heading 'avg waits' format 999,999;break on c0 skip 1;
select distinct
b.tablespace_name c0,
a.event c1,
sum(a.total_waits) c2,
sum(a.total_timeouts) c3,
sum(a.average_wait) c4
from
v$session_event a,
dba_data_files b,
v$session c
where
a.sid = c.sid
and
b.file_id = c.ROW_WAIT_FILE#
and
(
average_wait > 0
or
total_timeouts > 10
)
and
total_waits > 1000
group by
tablespace_name,
event
order by
b.tablespace_name,
sum(total_waits) desc
;
Note: In Oracle9i, Automatic segment space management (ASSM) can be used to relieve this form of segment header contention.
DBAzine Oracle Tip #2: Finding the Cause of "Hung" End-user Sessions within Oracle
submitted by Donald K. Burleson
It is not uncommon for an end-user session to "hang" when a user is trying to access a shared data resource held by another end-user. When a session is waiting on a resource, information can be found in the v$session view in the row_wait_file# and row_wait_block# which will help identify the source of the contention.
The file number and block number can then be cross-referenced into the dba_extents view to see the name of the table where the session is waiting on a block.
Here is the script. Note how the v$session column row_wait_file# is joined into the dba_extents view.
column host format a6
column username format a10
column os_user format a8
column program format a30
column tsname format a12select
b.machine host,
b.username username,
b.server,
b.osuser os_user,
b.program program,
a.tablespace_name ts_name,
row_wait_file# file_nbr,
row_wait_block# block_nbr,
c.owner,
c.segment_name,
c.segment_type
from
dba_data_files a,
v$session b,
dba_extents c
where
b.row_wait_file# = a.file_id
and
c.file_id = row_wait_file#
and
row_wait_block# between c.block_id and c.block_id + c.blocks - 1
and
row_wait_file# <> 0
and
type='USER'
;
Here is the output from this SQL*Plus script:
BOX USERNAME SERVER OS_USER PROGRAM
------ ---------- --------- -------- ------------------------------
TS_NAME FILE_NBR BLOCK_NBR OWNER
------------ ---------- ---------- ------------------------------
SEGMENT_NAME
---------------------------------------------------------------------------
SEGMENT_TYPE
-----------------
avmak1 JONES DEDICATED server ? @avmak1 (TNS interface)
IRMS_D 9 70945 SYSADM
CUSTOMER_VIEWS40
TABLE
The result shows that a session owned by user "JONES" is waiting for a resource in the IRMS_D tablespace at data block number 70945. The CUSTOMER_VIEWS40 table is at data block 70945.
Now that the source of the contention has been identified, you can locate other users who may be holding locks on this table.
Note: This type of wait can commonly be issued when a large update task is holding locks on the table, or when an individual task has placed an exclusive lock on specific rows in the table.
DBAzine Oracle Tip #1: Index Usage Monitoring Script
submitted by Donald K. Burleson
The performance of loads on critical Oracle tables can be crippled if too many indexes exist on the tables. Starting with Oracle9i, there is an easy way to identify those indexes that are not being used by SQL queries. This tip describes a method that allows the DBA to locate and delete indexes that are not being utilized.
The over-indexing of table columns is one of the most serious causes of poor SQL INSERT performance. SQL inserts, updates and deletes will run slower if they are required have to update large numbers of indexes each time a change is made to a table row. Since each column may have several indexes, this problem is aggravated with the use of function-based indexes.
Within an alter index command, you can monitor index usage. You can then query and find those indexes that are unused and drop them from the database.
Note: This feature is only a bit-flag set to "yes" or "no," depending on the usage of the index. We hope that Oracle10i might enhance this to count the number of times that the index was referenced.
The following script will turn monitoring of usage for all indexes in a set of schemas (specified in the WHERE clause):
set pages 999;
set heading off;spool run_monitor.sql
select
'alter index '||owner||'.'||index_name||' monitoring usage;'
from
dba_indexes
where
owner in ('SCOTT','MYOWNER')
;spool off;
@run_monitor
After turning on monitoring, allow a significant number of SQL statements to execute on the database, and then query the new v$object_usage view to see the usage flag:
select
index_name,
table_name,
mon,
used
from
v$object_usage;
The v$object_usage view shows which indexes have been used by setting the value in the USED column to YES or NO. As stated before, this will not tell you how many times the index has been used, but this can be a useful tool for investigating unused indexes and performance issues.
INDEX_NAME TABLE_NAME MON USED
--------------- --------------- --- ----
CUSTOMER_LAST_NAME_IDX CUSTOMER YES NO
For more details on this technique, see the book Oracle High-performance SQL Tuning by Oracle Press.
Contributors : Donald K. Burleson
Last modified 2005-02-28 10:35 AM