
Recipes For Use With Thin Clients
Paper presented by Dave Ensor at the European Oracle User Group, Copenhagen, June 1999. Oracle is currently promoting a trend away from distributed computing to the concentration of server processing in major centers, using web-based architectures. The paper reviews the design issues that determine the success or failure of 3-tier operation.
Summary
Oracle is currently promoting a trend away from distributed computing to the concentration of server processing in major centers, and is also telling its customers that client/server is dead. Listening to Oracle's presentations on these issues it would be easy to conclude that these trends, if indeed they are occurring, are an inevitable consequence of the World Wide Web.
However, the briefest review of the capabilities of the Web would bring many observers to the conclusion that the Web in general, and HTML in particular, are technologies that can make distributed computing work well. It is also clear that many of the problems that have afflicted client/server will also affect web-based computing unless real effort is made to ensure that the thin client is kept down to its target size.
Whatever Happened To Client/Server?
Client/Server was one of those things that marketing people love so much, a dream that intuitively appeals to customers so much that they spend money on it. And then spend even more when it fails to deliver first time out. Right from the start even the most trivial analysis of the technical proposition showed that Client/Server was doomed to failure as a vehicle for the implementation of high performance OLTP systems. This is not taking any benefit of hindsight; it is over ten years since the author first published his views on this topic and they have hardly changed in the intervening decade. However despite the architectural flaws some of the more determined sites have made Client/Server work reasonably well, aided by some clever product engineering from Oracle.
Today the official message is that Client/Server falls down because it fails to solve the problem of software distribution, and in particular the problem of software updates. While it is inevitably true that there can be severe problems in this area, there are products designed to address them with varying degrees of success. It is not so easy to get around the flaws in the basic premises of Client/Server operation.
Sadly, having intelligent clients to run the application logic does not relieve the central database server of any significant proportion of its load, and may even increase that load due to the path length of the protocol stacks. It comes as a great surprise and a crushing disappointment to both application users and application developers to learn that the application logic itself uses only a trivial percentage of the resource required to deliver the entire service. The reality is that the application logic is just the glue between activity at the user interface and activity in the data store.
There are two parts of an Oracle-based application service that use significant amounts of CPU. One is the operation of the data server itself, and we know intuitively that this must be performed on the server. The second is the direct management of the user presentation surface or GUI, and we know equally well that this must be performed on the client. Even using a protocol such as X-Windows that claims to export the GUI management to another host, significant processing power is still required at the X-Station itself.
So the application logic is the only “thin” layer in terms of processing power required or path length encountered during its operation, whereas it is the client that we are being told to place on a diet. The processing requirements are sketched below:
| User Interface Management |
| Application Logic |
| Data Management |
Now this is already starting to look like a three-tier architecture, but it is still misleading because at each client the requirement for CPU activity will come in short bursts, whereas in the data server it will be expected to be more or less continuous. The question in a two-tier world like client/server is where the application logic should go, and the easiest way to determine this is to recognize that the network is a critical resource. Thus the distribution of function must reduce both the amount and frequency of network data transmission. Above all else, for operation over a Wide Area Network (WAN) it is essential to reduce the number of network round trips.
Invariably both more messages and more data need to pass between Data Manager and Application Logic than need to pass between Application Logic and User Interface Manager, and so the application logic migrates to the server side of the network. This leaves the code at the user interface side with the role of just collecting keystrokes, making execution requests of the application logic, and displaying the data returned. If we can achieve this without having to first install any part of the application on the client machine then we will have entered the world of the “thin client.” This client is called thin even though it will normally be running an operating system that takes several hundred Mb of disk space to install.
Current Best Practice
As soon as Oracle7 was released we had a workable interim solution to the dilemma. By writing our application logic in server-resident PL/SQL packages we can construct a 3-tier software architecture which runs over a 2-tier hardware architecture.
With good programming discipline at the client, the traffic between the client and server hardware can be kept to a minimum and different client interface programs can guarantee to share the same application logic. Also the application logic rules can be changed without reference to the clients, and so (to a limited extent) can the package definitions themselves provided that the previously used procedures and functions are preserved. Overloading can be particularly useful to allow this.
This approach has been widely used and could best be described as reasonably successful. It certainly wins hands down over the original Client/Server approach of putting the whole of the application logic out at the client device, requiring the transmission of large amounts of access request and application data over the network, and incurring high numbers of network round trips.
But it is an interim solution. Part of the application still needs to be installed at each client, and this component is often both large and complex.
“The Web Changes Everything”
Web-based computing has an absolute minimum of 3-tiers. There is the user interface (the browser), the application logic (the web server or perhaps Oracle Application Server) and the data manager. At a simple web site the application logic may be minimal, and the data manager may just be the local file store, used to provide static data files for transmission. In more demanding applications, the web server may use the common gateway interface (CGI) to pass application logic requests to other servers.
Run Anywhere
The most radical change is that the client needs only two standard software components in order to be able to interact with the web server; it must have a web browser and a protocol stack. Whether we are discussing intranet, extranet, or full internet access is not relevant. World Wide Web (WWW) technology allows a client to use a service without any prior knowledge of it subject only to authentication requirements. This is dynamite. Get your web application up and running on the web server, fronted by your WAN connection, and any browser that is on, or can be routed to, that WAN can run the application. Your software distribution problems are solved, and you are independent of client hardware and operating system versions.
All they need is a compatible browser, a network connection and (optionally) some acceptable form of authentication. Setting up a web application can be so easy that proper privilege management disciplines are often ignored at the outset.
The good news is that “run anywhere” provably works. The bad news is that the application designers and developers who caused all the performance problems in the Client/Server world by putting excessive logic out there on the client are still alive and well, and they have fixed ideas about how a client interface should operate. In essence, they feel, the more it looks like a traditional client screen the better it is. So they want to land code on the client to manage the interface. As we shall see below, this works but can cause severe performance problems.
Is 300% java Necessary Or Desirable?
The phrase “300% Java” was coined by Oracle to describe a 3-tier environment in which Java could be used at every tier. Oracle8i supports Java as a database programming language, Oracle Application Server supports Java as an application programming language, and of course the later releases of the popular web browsers support Java in the client. Once all the software is production we can write code in Java in any of the tiers, but do we want to? Java has grown fast, it is everywhere, but it is still a new technology and the language itself is still stabilizing.
Data Manager Code
Clearly we need to write some database code, triggers and the like, but we've got pretty much used to PL/SQL for doing that, and most of the time it does the job reasonably well. It is also far and away the easiest procedural language in which to embed SQL statements, and that is what most database programming is about. Once JSQL is more mature and the pioneers have got the arrows out of their chests, then we might do well to take a look at it to see whether or not we prefer it to PL/SQL. As part of that decision we will also need some experience with Enterprise Java Beans (EJB), the class libraries that should give us access to server features such as schedulers, printing and file systems. Until then PL/SQL should do just fine - Oracle are unlikely to abandon it any time soon because they have used it to write an estimated 20 million lines of code that they need to keep running.
Application Logic
In the middle tier, where we previously used PL/SQL because it was the only choice, Java may well soon make sense. It has a number of solid object features and the colleges will soon start delivering graduates who already know it. One of the major advantages of Java is its portability, but just how portable does application logic really have to be if it is brought back into the center and housed on an application server? Portability is clearly a nice to have, but it is unlikely to be the highest priority. Besides, the disciplines required to write portable server-side code in C or C++ are widely known, though EJB may prove a better facility for calling out to platform services than any of the libraries currently available from C. Development based on Java Servlets is completely feasible today and because of the short path lengths typical of application logic the overhead of the virtual machine need not be a problem.
User Interface Management
The great problem here is to determine whether a programming language is needed at all. There is no doubt that Java, with Java Beans to provide the classes for manipulating the GUI, is an entirely satisfactory language for programming user interaction sequences but for many applications it is difficult to make a persuasive case as to why this needs to be done.
One thing we know for sure: if we continue to implement our basic data entry and enquiry screens in procedural code then that code gets large. Sadly large lumps of code have two significant penalties under Java. Firstly they take time to transmit on demand to the client, especially over a WAN, and secondly they pose memory management problems that are not well addressed by the current generation of Java Virtual Machines (JVMs). The latter we must expect will be overcome, as Java applets inevitably become larger and larger and the pioneering users complain ever and ever louder about response times. Transmission times will be more difficult to address and within widely distributed enterprises, the locations with slower speed network links will become even more disadvantaged than they are at present. This effect will be magnified if the Java code starts to issue SQL, and we will see all the performance problems that have dogged client server re-emerging in browser-based applications with the additional overhead of dynamically downloading the application.
On the other hand there is HTML. The name is an acronym for HyperText Markup Language but most users are less than comfortable with the term hypertext so the language is now known solely by its acronym. Experience shows that HTML is entirely capable of meeting the needs of a straightforward online system. It is reasonably attractive on the screen, though it does place real limits on layout complexity and these upset professional graphic designers. HTML can be highly efficient in terms of both network round trips and transmission length, but the more effort a designer has put into getting exactly the effect they want, the more stress the page will put on the network. The guiding principle in page design is KISS (Keep It Simple, Stupid).
User keyboarding errors can be minimized using check boxes, radio groups and pop lists. However HTML is weak on optional entry fields, having no way of declaring (for example) that either the Delivery Address must be left completely empty or all three lines must be filled in. Many project teams working with web-based applications have seen this as a sufficient reason to move to Java Applets. On the other hand a number of prominent Internet sites have continued to keep faith with HTML in order to maximize their market potential. Pure HTML gives much better performance over slow network links, and works with older versions of browsers. Whenever you connect to a web site where you are required to have the latest release of a specific browser, then you are no longer part of the run anywhere community. Requiring specific plug-ins is even worse.
Just to make life a little more complex, there are two other technologies that we should consider.
Dynamic HTML (DHTML) allows client-side scripting to be embedded in an HTML page, and this presents a tactical option for overcoming some of HTML's limitations on data validation. If you are still hankering after just a little client-side Java then running JavaScript in DHTML may be the answer, but it does not (yet) constitute a run anywhere solution. It could be a “run everywhere we really need to” solution.
XML (eXtended Markup Language) evolved from HTML in the light of the restrictions that were found using HTML for industrial strength applications. The next generation of web browsers promise support for XML, and it looks likely to replace HTML in the medium term. With its subsidiary languages XSL and XLL (structure and linkage langauges), it looks capable of providing a complete syntax for specifying the layout and interactive behavior of all but the most esoteric pages. At the time of writing it is, like Java running in the database kernel, a future in terms of mass deployment.
To answer the question
With the various technologies in the states that they are in at the time of writing, 300% Java does not look like a sound current proposition. 95% Java (JavaScript in small quantities on the client, quite a lot of Java in the application logic and little or no Java in the data server) looks to be both highly functional and technically safe if your browsers support DHTML with embedded JavaScript.
Data Distribution
One of the main design objectives of HTML was to allow a document (or page or frame) held on one machine to contain a navigable pointer to a reference in another document anywhere within the network, and to allow this to be done without having to store physical addresses. The URL (Uniform Resource Locator, and pronounced “earl”) was devised to allow these references to span the entire Internet. Given that we have a display language that allows us to put a link to anywhere on the user's display, there seems on the face of it little reason to concentrate all of our data in one place.
The middle tier, the application logic, also makes data distribution more rather than less feasible. The user or client is no longer connected to a database instance as such, but is connected to application logic within a middle tier, and that logic can direct data management requests to the appropriate data server. If the Transaction Manager component of the Application Server and the Data Servers are all XA compliant then transactions can safely span multiple data servers, though there will always be some performance penalty. There need be no performance penalty in a transaction against one data server making a query against another, and indeed this can be a highly effective performance tuning technique if used to remove queries against static data from a heavily loaded dynamic database.
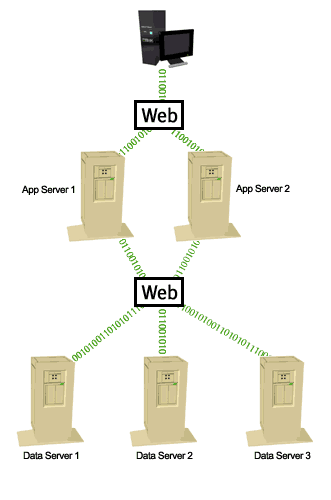
The more we look at it, the more web-based computing seems to favor data distribution rather than to mitigate against it.
Server Configuration
As was discussed earlier in this paper, application logic does not impose a major CPU load but does require constant communication with the data server(s). Because the CPU requirement is not massive, a few servers are sufficient and normally these should be physically close to the data servers that they are most likely to use. Application servers may be clustered for availability, but are unlikely to benefit in performance.
The use of normal web links on application menus means that traffic can be directed to the application server best sited for the data server used with the function being requested, and that this redirection need never be visible to the user. Where data servers are clustered for availability, it should also be possible to use application logic to enforce application segmentation across the parallel server instances and this would overcome the performance problems frequently seen when running Oracle Parallel Server. This type of application logic is, however, a relatively new area and one which requires experimentation.
Conclusion
Industry visionaries are telling us that Client/Server is dead and the future is web-based computing with 300% Java, based on large central servers.
Web-based computing, by embracing run anywhere, solves at least one of the problems of Client/Server, that of software distribution. With good design and minimal use of client-side programming it can also be highly network efficient. 300% Java is not currently attractive, and it is difficult to see how large Java applets running at the client can be compatible with performance in any large networked environment. Certainly when the link to a server is via a WAN (wide area network) the transmission time can become prohibitive.
The preferred architecture is a web-based 3-tier structure with strict controls over the client interface design to allow it to be achieved without the use of applets. The argument for concentrating processing centrally is not compelling, but neither is the argument for distributing data that is logically part of a single set unless the processing load will be too high.
---
Dave Ensor is a Product Developer with BMC Software where his mission is to produce software solutions that automate Oracle performance tuning. He has been tuning Oracle for 13 years, and in total he has more than 30 years' active programming and design experience.
As an Oracle design and tuning specialist Dave built a global reputation both for finding cost-effective solutions to Oracle performance problems and for his ability to explain performance issues to technical audiences. He is co-author of the O'Reilly & Associates books Oracle Design and Oracle8 Design Tips.
Contributors : Dave Ensor
Last modified 2005-02-23 10:48 PM