
Costs and Benefits for High Availability Oracle9i
Today's Web development managers are more challenged than ever to find the appropriate tools and technologies for their mission-critical Oracle databases. With the explosive interest in e-commerce, end users have high expectations. They demand systems on the Web that can support thousands of concurrent transactions per second while at the same time providing sub-second response time and continuous availability.
Many of the world's top e-commerce systems use Oracle databases. Behemoths such as Amazon and eBay use Oracle databases and support mind-boggling transaction rates. And they make it look easy. But the reality is that a tremendous amount of manual effort goes into creating a Web architecture that provides a continuously available solution for Oracle databases on the Web.
The Evolution of High-availability Systems
Over the past five years, the demands upon Oracle e-commerce systems have been radically changing. Consumers on the Web are no longer content with systems that are down periodically and systems that don't provide sub-second response time.
Hence, it is the challenge of the Oracle professional to create a database architecture that is continually available, while at the same time providing blistering response times, even when transaction rates exceed thousands of transactions per second.
Because of eCommerce customer intolerance, continuous availability is a major goal of any Oracle database that is deployed over the Internet. But how to we go about getting continuous availability?
By studying successful companies we can get an idea of some of the methods they use in order to make sure that their systems are always available. Successful companies employed replicated databases, such that the failure of any component of a single database, including disk, RAM, CPU, or network, will not have a catastrophic failure on the entire system. In addition to replication, mechanisms are created to allow in-flight transactions to be automatically reconnected to another fully replicated database management system, which is most often located at a different geographical location in the primary database server.
This approach of having replicated Oracle systems geographically distributed across the globe also insures that connectivity over the Internet is always done in a uniform fashion regardless of where in the world the connection is started.
The challenge in this type of architecture is to ensure that all of the replicated systems remain synchronized. Prior to the advent of Oracle9i, many e-commerce vendors used a shadowed standby database. In a standby database, redo log images were fed from the primary system into a standby database that was always in recovery mode. If there was a failure of the primary server, the last redo logs could be fed into the standby database, which could then be quickly started in takeover the processing load. Of course, this approach had the serious drawback of requiring at least 15 minutes downtime in case of primary hardware failover.
Oracle replication was also very little help, because snapshot refresh intervals were not instantaneous enough to keep all the systems exactly synchronized. To address this requirement for instantaneous system replication, third party products such as Quest shareplex were developed in order to take Oracle redo log images directly from Oracle's RAM wall buffer and generate SQL statements which were then fed to the replicated databases.
The Components of Continuous Availability
While replicating entire systems is a great solution for providing continuous availability we also have to remember that there are replicated components within each individual Oracle system. Let's take a look at each one of these components individually and hope to understand how this kind of replication reduces the probability of system failure.
Disk failure - Over the past decade, hardware devices have become increasingly more reliable. However, in addition to this reliability, we also see that many disk storage vendors are implementing sophisticated RAID technologies in order to ensure that they have redundant backups of any disk device. This replication takes the form of disk mirroring, which is also known as raid 0, and some companies will even triple mirror their disks. Should an individual disk fail, many disk storage or raise will telephone the vendor directly and the vendor will arrive at the machine room and replace and re-synchronize the broken disk device without any service interruption. For companies that are willing to investing triple mirrored disks, the meantime between failures is expressed in decades, and these companies can confidently assume that a failure of their disk I/O subsystem is not going to cause a service interruption for their mission-critical system.
Processor failure - Within any hardware architecture, automated failovers of CPU in RAM memory are becoming increasingly sophisticated. In an SMP configuration for UNIX, you may have 8, 16, 32, or even 64 individual CPUs configured as a symmetric multiprocessing configuration. Should anyone of these individual processors fail, the UNIX operating system is directed to bypass the bad CPU and continue processing on the remaining processors. Just like with disk devices, many hardware vendors have software that will automatically notify the vendor of the hardware, and replacements can be installed without any service interruption.
Inside High-availability for Oracle9i Applications
Within the IT industry there are two metrics that are commonly used to measure the time between failures and the time required to recover from these failures. The first is the meantime between failures which is commonly abbreviated MTBF. The MTBF value specifies a statistical estimate on how long the expected configuration will be able to run without unplanned data outage. The numbers for the MTBF can be gathered from hardware vendors, and mathematical techniques can be applied replicated systems to accurately predict the duration between unplanned data outages.
The second measure is the meantime to recovery which is commonly abbreviated MTTR. The MTTR was developed to measure the amount of downtime that will be incurred should there be a catastrophic failure of some component within the computer system. Of course, for continuously available systems the MTTR should be equal to zero, but many companies who are unable to invest many millions of dollars in continuous availability or often content to have systems with an MTTR which is measured in less than 30 minutes.
- MTBF - Mean time Between Failures
- Hardware vendors can provide MTBF for all hardware.
- You must measure your companies MTBF, noting causes of outages (human, hardware, software)
- MTTR - Mean Time To Recovery
- Sometimes MTTR depends of nature of failure
- Hardware vendors can guarantee MTTR, and this should be spelled-out in a binding contract.
What Is Your Cost of Downtime?
The costs are a huge issue when considering high-availability solutions, and many companies carefully quantify all costs associated with database downtime. These costs include:
- Revenue loss - Up to $100,000 per minute
- Productivity loss - Factory workers sitting about
- Reputation loss - Remember eBay?
However, 100 percent availability is very expensive, and most companies must choose a tradeoff between high-availability and cost. The figure below shows the average costs of database downtime for different industries (source: Giga group).
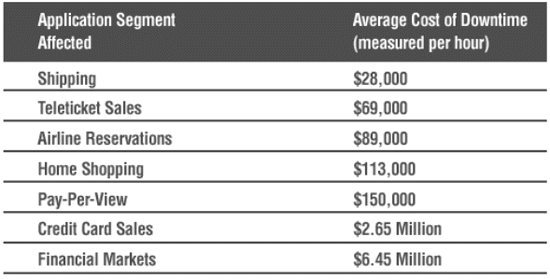
When we take a look at the costs associated with system downtime, many Oracle managers make a mistake of measuring only the actual tangible costs of having the system down. Of course, having a mission critical system down is going to result in lost revenue from sales, worker of productivity losses, but you always have to keep in mind the intangible costs associated with the system downtime. These intangible costs can include loss of customer goodwill which is often measured in millions of dollars. One has to look no farther than the eBay system to understand the dramatic impact an unplanned system outage can have, not only in lost revenue but on lost goodwill from the customer base.
We generally see the costs of unplanned downtime broken down by industry experts. Leading the pack are the financial markets for which unplanned downtime can run into many millions of dollars per hour. We also see high cost for other financial systems such as credit card companies, who have losses that can be expressed in many hundreds of thousands of dollars per minute. Manufacturing systems are also subject to very high cost, but these are direct costs in terms of lost sales, Rather, lost sales for manufacturing operations often have to do with interruption of the manufacturing process, and lost wages paid factory workers who were no longer able to do their jobs.
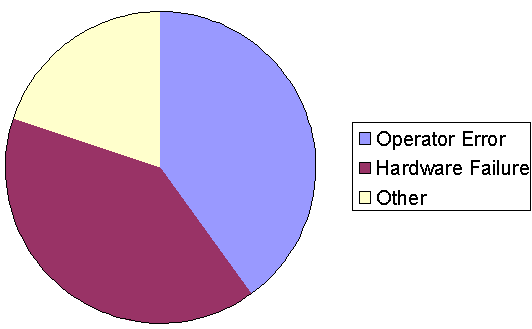
The Causes of Unplanned System Outages
When we take a close look at the causes of unplanned systems outages, we see that the majority of outages are equally divided between hardware failure and human error. Hardware failure accounts for approximately one-third of all total system outages, with a little more than one-third of system outages being attributable to some kind of human failure. This human failure can take many forms, from a software patch that was not thoroughly tested before moving it into production, or from an operator error in the machine room. It is very easy for people in the IT industry to add additional hardware layers in order to ensure continuous availability up hardware level, but active steps must be taken whenever possible to reduce the amount of human intervention.
In practice, many companies are actively working to create Oracle Web system architectures that minimize the amount of human intervention by automating mundane tasks such as state mounting, tape cataloging, database recovery procedures, and any other procedures which might require the intervention of fallible human beings.
Causes of System Outages: Gartner Group
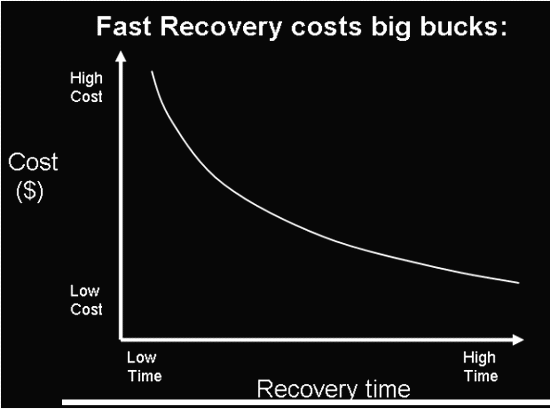
Fast Recovery Is Expensive
If you want super-fast failover without any service interruption, using RAC with TAF, or a customized webserver failover will provide this protection. Of course, there are significant costs associated with the setup and testing of these tools.
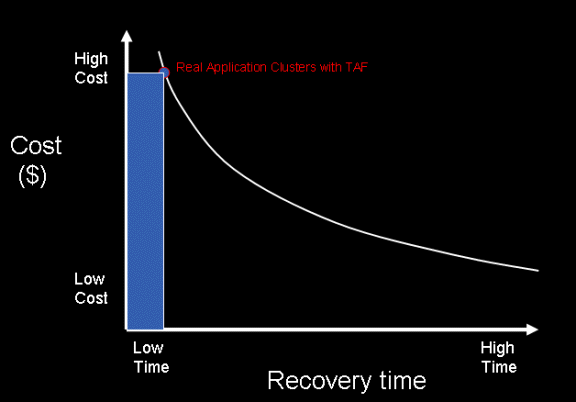
Specific Continuous Availability Costs
When we look at the specific costs of continuous availability systems, we see a split between hardware costs and the costs of human beings. On the hardware end, we know that massively parallel replicated machines can be quite expensive, and we also know that mirroring disks will double the amount of disk devices required for the system.
On the human factors, we also see a significant expensive highly trained computer systems professionals such as Oracle DBAs who were charged with building and testing the continuous availability architecture for the system.
In fact, the set-up and testing costs are so high for Oracle's Real Application Clusters with Transparent Application Failover that many companies in the real world are considering building customized Web server failover solutions. Many of these customized Web server failover solutions utilize an Oracle extension to the Apache Web server, where the Web server programmer can automatically cache and restart fail transactions should any single database engine stop responding.
Cost Issues Surrounding Continuous Availability
It's important for companies to remember that continuous availability is not inexpensive. While the software components are readily available, the human effort for the installation, set up, and testing of continuous availability systems can be very expensive and time-consuming. The set-up for Oracle time for using Real Application Clusters, and the Transparent Application Failover product can run in the many hundreds of hours of time for the installation, configuration, and testing of these tools.
In practice, companies must take a look at their relative costs of downtime, and choose a high availability or continuous availability solution that meets their economic loss of downtime.
On one end of the spectrum, we know that large financial institutions have down times are expressed in hundreds of thousands of dollars per minute. These kinds of companies cannot tolerate any kind of unexpected outages, and they are willing to invest the millions of dollars necessary in order to ensure that their systems are always available, even in cases of catastrophic tragedies such as the events of September 11th.
Moving down the spectrum, companies they can tolerate a small amount of unplanned downtime during the year can often use less expensive continuous availability solutions. The solutions would involve standby databases, or traditional database recovery using Oracle's RMAN utility.
Conclusion
In any case, it is the job of Oracle management to weigh the costs of unexpected downtime with the cost of additional layers of continuous availability protection. For systems to be truly 24 by 7, many replicated servers across the globe may have to be installed and sophisticated techniques put into place to ensure that these replicated databases remain synchronized. For those companies willing to tolerate a meantime between failures of less than one decade, replicated systems can be placed within the same machine room over high-speed interconnect, and these two systems can be only a few feet from each other. Each system feeds continuous updates to the other in order remain synchronized, and both systems can be open and available for use by the end-user community.
--
Donald K. Burleson is one of the world’s top Oracle Database experts with more than 20 years of full-time DBA experience. He specializes in creating database architectures for very large online databases and he has worked with some of the world’s most powerful and complex systems. A former Adjunct Professor, Don Burleson has written 15 books, published more than 100 articles in national magazines, serves as Editor-in-Chief of Oracle Internals and edits for Rampant TechPress. Don is a popular lecturer and teacher and is a frequent speaker at Oracle Openworld and other international database conferences. Don's Web sites include DBA-Oracle, Remote-DBA, Oracle-training, remote support and remote DBA.
Contributors : Donald K. Burleson
Last modified 2005-06-22 12:32 AM