
Disk Management for Oracle
As a tuning professional, I can tell you that, for the vast majority of non-scientific systems, the primary bottleneck is disk I/O. Back in the days before RAID and giant db_cache_size, the DBA had to manually load balance the disk I/O sub-system to relieve contention on the disks and the disk controllers.
Many DBAs would like to believe that this disk technology has changed. Sadly, the only major changes to disk technology since the 1970s are these hardware and software changes:
- Large data buffers — Today the DBA can cache large portions of the data blocks in the db_cache_size reducing disk I/O.
- Disks with on-board cache — Many of the newer disks have an on-board RAM cache to hold the most frequently-referenced data blocks.
- RAID — The randomizing of data blocks with RAID 0+1 (and RAID 5 for read-only systems) has removed the need for disk load balancing by scrambling the data blocks across many disk spindles. In Oracle10g, the Automatic Storage Management (ASM) feature requires “mirroring and striping everywhere,” which is essentially RAID 0+1 (sometimes called RAID10).
However, other than these three advances, disk technology has not changed since the 1970s. The Oracle DBA must remember this and understand the internals of disk management to maximize the performance of their I/O-bound systems.
Remember, not all systems will benefit from reducing disk I/O. Computationally intensive systems (e.g., scientific applications) will read a small sub-set of data, and then perform complex calculations.
Time and time again, I see Oracle DBAs tuning a portion of their database that is not on the critical path, and they are surprised to find that their change did not make a huge difference in performance. All Oracle databases have some physical constraint, and it is not always disk. The best way to find the constraint for your system is to examine the top five wait events on your STATSPACK report:
- Disk constrained — The majority of the wait time is spent accessing data blocks. This can be db file sequential read (usually index access) and db file scattered read (usually full-table scans):
Top 5 Timed Events
~~~~~~~~~~~~~~~~~~ % Total
Event Waits Time (s) Ela Time
--------------------------- ------------ ----------- --------
db file sequential read 2,598 7,146 48.54
db file scattered read 25,519 3,246 22.04
library cache load lock 673 1,363 9.26
CPU time 1,154 7.83
log file parallel write 19,157 837 5.68
- CPU Constrained — The majority of the wait time is spent performing computations. You can also see this when the CPU run queue exceeds the number of CPUs on your database server (using the “r” column in vmstat UNIX):
Top 5 Timed Events
~~~~~~~~~~~~~~~~~ % Total
Event Waits Time (s) Ela Time
---------------------------------- ------------ ----------- --------
CPU time 4,851 4,042 55.76
db file sequential read 1,968 1,997 27.55
log file sync 299,097 369 5.08
db file scatt 53,031 330 4.55
log file parall 302,680 190 2.62
- Network Constrained — Network bottlenecks are very common in distributed systems and those with high network traffic. They are manifested as SQL*Net wait events:
Top 5 Wait Events~~~~~~~~~~~~~~~~~ % Total Event Waits Time (cs) Wt Time --------------------------------- ------------ ------------ -------SQL*Net more data to client 3,914,935 9,475,372 99.76 db file sequential read 1,367,659 6,129 .06 db file parallel write 7,582 5,001 .05 rdbms ipc reply 26 4,612 .05 db file scattered read 16,886 2,446 .03
Once you have determined that your Oracle database is I/O-bound, you must fully understand the internals of your disk devices and the configuration of your disk controllers and physical disk spindles. Let’s start with a review of disk architecture and then return to disk tuning and see how to troubleshoot and repair disk I/O problems.
Back to the future
Back in the days of Oracle7, almost all databases were I/O-bound. Because most applications are data intensive, the database industry came up with all sorts of elaborate methods for load-balancing the I/O subsystem to relieve disk contention.
On the IBM mainframes, the DBA could specify the specific absolute track number for any data file with the “absolute track” (ABSTR) JCL argument. This allows the mainframe DBA to control placement of the data files on their IBM 3380 disks. Prior to RAID, data file placement rules were quite different (or were they?):
- File Cylinder Placement
- File Striping
- File Segregation
Let’s take a look at each of these approaches, remembering that the fundamental nature of disks has not changed since the 1970s. Today’s disks still have three sources of delay, and though the “average” disk latency is 15 milliseconds, there can be a wide variation in disk access speed.
Inside Disk Architecture
Internally, disks have changed little since the 1970s. They still have spinning magnetic-coated platters, read-write heads, and I/O channels. Let’s take a minute to understand how disk I/O works at the device level.
- Read-write head delay (seek delay) — This is the time required to place the read-write head under the appropriate disk cylinder, and this time can be 90 percent of disk access time. It is especially bad then competing files are placed in outermost cylinders. Back in the days of 3350 disks, you could load an ISAM file into a 3350, and watch the device shake as the read-write heads swung back and forth. The probability of traveling an arbitrary distance across the disk (pdi) is:
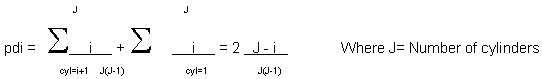
- Rotational delay — Once on the proper cylinder, the read-write heads must wait until the track header passes beneath them. The rotational delay is the speed of rotation divided by two, assuming that a platter will have to spin a half-revolution to access any given track header.
- Data transmission delay — This delay can be huge for distributed databases and database on the Internet. For example, many worldwide Oracle shops use replication techniques and place systems staggered across the world to reduce data transmission time.
Even today we still see these three components of disk access latency. Back before large data buffer caches and RAID, the DBA had to manually place data files on the disk and monitor I/O patterns to ensure that there was no disk contention.
Remember, if you are not using RAID striping, these rules remain important. The manual disk placement rules include:
- File Placement — The DBA would place high I/O data files in the “middle” absolute track number to minimize read-write head movement. This is a situation in which the low access data files reside on the inner and outer cylinders of the disk. In figure 1, we see where high impact data files should be placed to minimize read-write head movement:
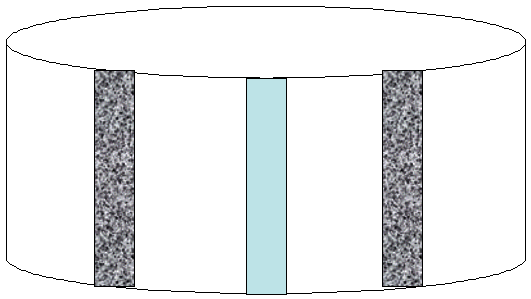
Figure 1: Hot file placement of non-RAID data file.
- File Striping — High impact data files were supposed to be spread across many disk drives to spread the load and relieve disk and channel contention:
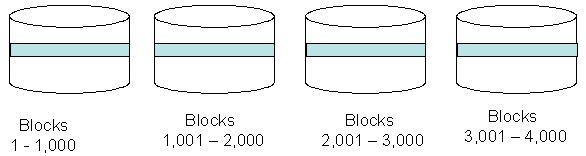
Figure 2: Striping a non-RAID data file across many disks.
- File Segregation — An index file and a data file should be placed on separate disk spindles to relieve contention. This is also true for online redo logs, the archived redo log file directory, and the undo log files.

Figure 3: A segregated non-RAID Oracle file system.
Remember, if you are not using hardware or software RAID, RAM SAN, or 100% data caching, all of these disk I/O rules still applies.
Now that we see the manual methods for Oracle data file management, let’s see how advances of the past decade have simplified this important task.
The Age of Change
As we can see, the manual file placement rules are cumbersome and complex. During the 1980s, many DBAs spent a great deal of their time managing the disk I/O sub-system. There are three main technologies that have changed this approach:
Solid State Disk
The new solid-state disks retrieve data thousands of time faster than traditional disks at a cost of about $10k per gigabyte. Many Oracle shops are using RAM SAN technology for their TEMP tablespace, undo files, and redo log files. The noted Oracle author James Morle has a great whitepaper on solid state disks.
Large RAM Caching
In 64-bit Oracle, the db_cache_size is only limited by the server, and many shops are running fully-cached databases. In the next five years, prices of RAM should fall such that most systems can be fully cached, making disk management obsolete.
Oracle8i provides a utility called v$db_cache_advice that allows you to predict the benefit of adding additional RAM buffers (refer to figure 4).
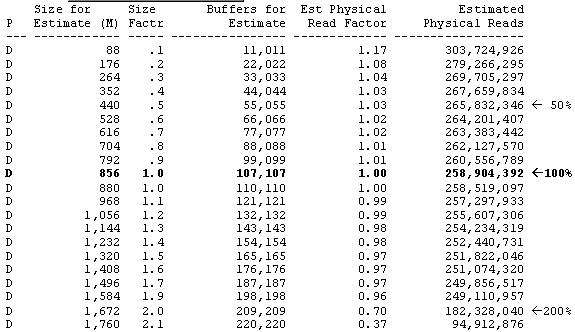
Figure 4: Output from the v$db_cache_advice utility.
In figure 4 we see that Oracle estimates the physical reads for different sizes of the db_cache_size. In this example, we see that doubling the db_cache_size from 856 to 1,672 will reduce disk I/O by more than 80 million disk reads. However, as we approach full-caching, less frequently referenced data becomes cached, and the marginal benefit of caching decreases (refer to figure 5).
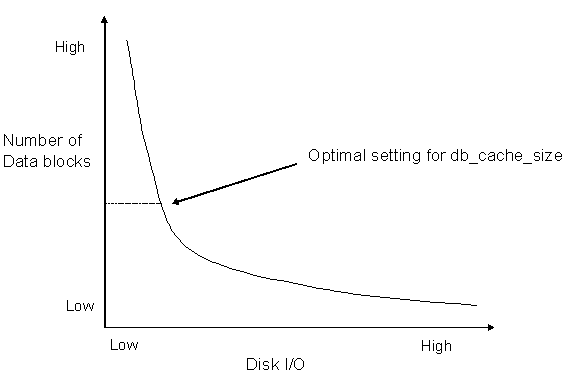
Figure 5: The marginal gains from large RAM caches.
As we see in figure 5, as we approach full data caching, the marginal benefit of blocks to db_cache_size decreases. While Oracle has not published the mechanism, this approach is likely the foundation of the new Oracle10g Automatic Memory Management (AMM) feature. With AMM in Oracle10g, you can tell Oracle to track the usage of RAM within the shared_pool_size, pga_aggregate_target and db_cache_size, and Oracle10g will automatically adjust the sizes of these SGA regions based on current usage.
RAID Technology
The advent of hardware and software RAID has relieved the need for the DBA to manually stripe data files across multiple disk spindles. The two most common “levels” of RAID are RAID 10 (mirroring and striping) and RAID5.
Oracle recommends using RAID 10 (a.k.a. RAID 0+1) for all systems that experience significant updates. This is because of the update penalty with RAID 5 architectures.
The Horrors of RAID 5
Using RAID 5 for a high-update Oracle system can be disastrous to performance, yet many disk vendors continue to push RAID 5 as a viable solution for highly updated systems.
This has become so problematic for Oracle DBAs that the Oracle Oak Table Consortium has formed the Battle Against Any Raid Five (BAARF) Party. This party boasts a membership of some of the world’s top Oracle DBAs (I’m proud to be member #27).
According to the BAARF charter, Oracle customers are “being cheated” by unscrupulous disk vendors, and BAARF’s mission statement says it all:
“The reason for BAARF is that we’ve had it. Enough is enough. For 15 years, a lot of the world’s best database experts have been arguing back and forth with people (vendors and others) about the pros and cons of RAID-3, 4, and 5. Cary Millsap has written excellent articles on RAID technologies that should have stopped the useless and pointless discussions many years ago. James Morle and others have written books where they discussed the uselessness of RAID-F stuff.”
In sum, it is clearly problematic for any company with high volumes of updates to use RAID 5, and Oracle10g with Automatic Storage Management (ASM) wants Oracle customers to use RAID 0+1.
Conclusion
Until such time that solid state disk is cheap enough to fully cache large databases, the Oracle DBA will still be concerned about their most critical performance area, the disk I/O sub-system. The main points of this article include the following:
- If you are not using RAID, the old-fashion file placement rules still apply, and you must manually place Oracle data files across your disk spindles to relieve I/O contention.
- Using a RAID10 approach (mirroring and striping) distributes data blocks across all of your disk spindles, making “hot” disks a random and transient event.
- RAID 5 is not recommended for high-update Oracle systems. The performance penalty from the parity checking will clobber Oracle performance.
- Oracle9i and Oracle10g continue to refine the ability to support very large RAM data buffers with the v$db_cache_advice utility and Oracle10g Automatic Memory Management (AMM).
- Solid state disk is getting cheaper, and may soon replace traditional disk devices. Many Oracle customers are using solid state disks for high I/O data files such as TEMP, UNDO, and REDO files.
- If disk is not your bottleneck, improving disk access speed will not help. Be sure to check your top-5 STATSPACK wait events to ensure that disk I/O is your bottleneck before undergoing expensive changes to your disk I/O subsystem.
In sum, Oracle DBAs must continue to fully understand their disk I/O sub-system and make sure that disk I/O does not impede the high performance of their systems.
--
Donald K. Burleson is one of the world’s top Oracle Database experts with more than 20 years of full-time DBA experience. He specializes in creating database architectures for very large online databases and he has worked with some of the world’s most powerful and complex systems. A former Adjunct Professor, Don Burleson has written 15 books, published more than 100 articles in national magazines, serves as Editor-in-Chief of Oracle Internals and edits for Rampant TechPress. Don is a popular lecturer and teacher and is a frequent speaker at Oracle Openworld and other international database conferences. Don's Web sites include DBA-Oracle, Remote-DBA, Oracle-training, remote support and remote DBA.
Contributors : Donald K. Burleson
Last modified 2005-06-22 12:18 AM