
A Shootout Between Sun E4500 and a Linux Redhat3.0 AS Cluster Using Oracle10g
In many Oracle shops, there is a move afoot to move from the larger, older, mid-range UNIX servers to the commodity-based Linux model of computing. Whether this is motivated by finance, technology, or just because Linux is the new kid on the block, it is important to understand how this move may affect the performance and behavior of your system.
Why Did I Choose Linux to Test Against?
There are many operating systems available for the data center, including Windows-based systems, other UNIX versions such as HPUX, AIX, and TRU64 — so why Linux?
Let’s look at a few of the most compelling reasons:
- Linux is one of the fastest growing operating systems; in 2002, its market share grew 18 percent as opposed to Microsoft’s three percent
- Linux provides enterprise-level OS features for a fraction of the cost
- Linux utilizes a non-centralized support model in which bugs are tracked, reported, and fixed by thousands of developers worldwide
- Linux outperforms most other operating systems, especially with Oracle (most new development at Oracle will be done on Linux, replacing Solaris)
Thus, Linux seems to be one of the up-and-coming operating system, and in my consulting practice, I have had more requests concerning conversion to Linux than to any other operating system.
What We Will Cover
This article discusses a testing methodology and the results of a test performed utilizing an Sun E4500 with 4-400 MHz RISC CPUs, with 2 GB RAM, using a AS5100 8x73GB FC disk array, against a Linux Redhat 3.0 AS DB Server Cluster, each with Dual 2.8 GHz Xeon CPUs, 2x36GB internal SCSI, 2GB RAM per server, with 2Gb/s FC HBA and a 12-disk SATA Array, 12x36GB 10K for a total system of 4 Linux Servers, 2 SATA Arrays, 8 FC Ports and 8 Gig-E Ports.
Now, some of you are no doubt saying, “Geesh, the E4500 is already out-gunned,” and I would have to agree with you. However, this is a typical configuration of those being replaced, and that is why it was chosen.
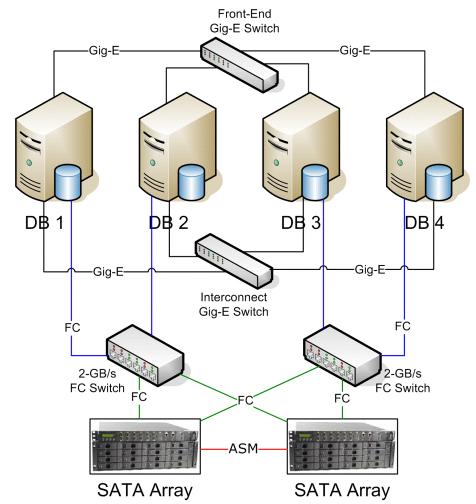
Figure 1: Linux server configuration.
None of the servers were preinstalled with Oracle; all were “Greenfield” boxes with just the operating system installed.
Basic Project Plan
The basic project plan consisted of setting up both systems utilizing the same release of Oracle10g (10.1.0.2) and configuring the Sun Solaris system as a single Oracle10g system and the Linux cluster as an Oracle10g RAC system. I picked this design because a majority of clients will be operating in Single-Instance mode on Oracle before they decide to go to Oracle10g using RAC.
We configured the RAC cluster by following this general procedure:
- Install CRS
- Install ASM and database software
- Create example RAC database on Linux
- Utilize TPCH dbgen to generate 10GB database load files
- Load example Linux database using SQLLoader
- Create indexes on Linux
Next, we configured the Solaris system:
- Install CRS
- Install ASM and database software
- Create single instance database on Solaris
- Utilize TPCH dbgen to generate 10GB database load files
- Load example Solaris Database using SQLLoader
- Create indexes on Solaris
Note that the Solaris and Linux configurations progressed in parallel as much as possible.
Once we had the basic database loaded, we used the qgen routine from TPCH to generate the standard queries; after reviewing the queries, one was chosen as the test query for our purposes. This query is shown in Listing 1.
select
ps_partkey,
sum(ps_supplycost * ps_availqty)value
from
partsupp,
supplier,
nation
where
ps_suppkey = s_suppkey
and s_nationkey = n_nationkey
and n_name = 'INDIA'
group by
ps_partkey having
sum(ps_supplycost * ps_availqty) > (
select
sum(ps_supplycost * ps_availqty) * 0.0001000000
from
partsupp,
supplier,
nation
where
ps_suppkey = s_suppkey
and s_nationkey = n_nationkey
and n_name = 'INDIA'
)
order by
value desc;
Listing 1: Query chosen for test.
Notice that the query uses a three-table join, a sub-select, a group by, and an order by, making it a fairly complex query that utilizes sorts, indexes, and summaries, and will therefore exercise much of the Oracle query engine.
Tools Used
We used the TPCH benchmark dbgen program (which had to be relinked for Solaris) to create a 10GB load set. The load set was generated in five flatfiles per major table, except for the nation and region table, which had one flatfile each. The databases were loaded using sqlloader (TPCH — Decision Support benchmark, available from http://www.tcp.org)
One item that is not well documented is that, to use the Oracle ASM product most effectively, you should use the ASMLIB set of routines from Oracle, so be sure that the oracleasm libraries and utilities are downloaded and installed (side note — Fedora cannot load this as it is branded for the commercial kernel). The oracleasm libraries provide the capability to mark entire disks (either actual or virtual) as ASM devices, making discovering them and managing them easier. Both the Oracle cluster file system (OCFS) and ASM can be used in the same database, but not for the same files.
Issues Resolved
We had several issues during the software install and load process:
Disk Reconfiguration
We established the required RAW devices (two at 150MB each) on the Linux cluster; this required a rebuild of the disk farm. If you need to rebuild CRS, you must remove the ocr.loc file from /etc/oracle (this is overlooked by the deinstall procedure from metalink).
Missing Library
The Linux box was missing a Library that allowed backward compatibility to 7.3, which caused the load to fail, and required analysis to resolve. The library is provided on the Linux install disk, which is why I usually use the ITHDT method of install on Linux boxes (“install the whole darn thing”). As with any other install, I usually end up searching the disks for that one RPM or utility that wasn’t get installed, and the difference in install size between the maximum typical install and the whole darn thing is usually only a gigabyte or two.
Script Miss-run
Also, do not run the rootdeinstall.sh script in CRS_HOME/install if you only want to deinstall a single node from CRS. Instead, just run rootdeletenode.sh. The first time through, we ran both when all that was needed was to run rootdeletenode.sh, which then required another reload of CRS to resolve.
ASM Issue
Once CRS was installed, we attempted to use the general database from the start; however, you need to use the advanced (custom) database or the installer assumes that you already have ASM installed. If you choose advanced, custom database, the dbca utility will allow you to install ASM. During the install, you will be asked for a discovery path for the ASM disks; this is “ORCL:” period — nothing else.
OUI GUI Lack of Warnings
Once the database was installed (note that there were several restarts during this process, and two of them were caused by hitting the “Back” button one too many times), we began the data loading.
Solaris Load Stall
The first system running and ready for loading was the Solaris system, so we started the load process there. (This concluded the first day.)
The next morning, we noted the Solaris load seemed to have stalled. We bounced the database and resumed the load which ran to completion.
Power Failure to Boxes
We finished the Linux install and started its load. By early afternoon, the Linux box had caught up with the Solaris box, right up to the point we lost power to the systems (they were plugged into the same circuit, with no UPS.) When the databases came back up, the Solaris database was OK, but the Linux database showed that its mirrors were out of sync. We attempted several times to restore the database, but it was not recoverable. Investigation showed this was because the cache was not being protected by battery backup (after all, this was just a demo box). We had to drop the database, reload CRS, reload the database software, and recreate the database. (This experience indicates a very important tip: If you are using memory caches, be sure they are battery-back-up caches!)
On the third day we rebuilt the Linux database and restarted its data load.
Possible ASM Configuration Issue
During the Linux data loads I had to restart them frequently because the control files would report bad blocks, and the loading instance would crash, but would then immediately restart. I theorize that this is because we used the RAID controller to stripe the drives and present them as one large, logical volume to the ASM unit. It probably would have been better to use individual disks, either mapped as raw devices or just ASM disks, and allow Oracle to perform the striping.
The drive arrays were divided into four logical volumes each, two 150MB raw partitions and two 50GB raw partitions. The 50GB partitions were mapped into the DATA and FLASH disk groups at the ASM level with DATA being used for all data, index, undo, rollback, and temporary files; and FLASH being used for a back-up area. The two 150MB partitions were used for the CRS cluster configuration disk area and the cluster quorum disk area.
Results
After everything was loaded, all indexes built, and schemas analyzed, we were ready to start. Before we look at the query testing results, let’s look at a few build statistics. First, let’s consider load times for the tables: The Line Item table was loaded form five files of 12 million rows each. The results comparing the SUN with its eight drives stripped by ASM and the Linux cluster with a 12 disk SATA array are shown in figure 2. The loads on the Linux cluster were done serially using SQLLoader from a single Linux node.
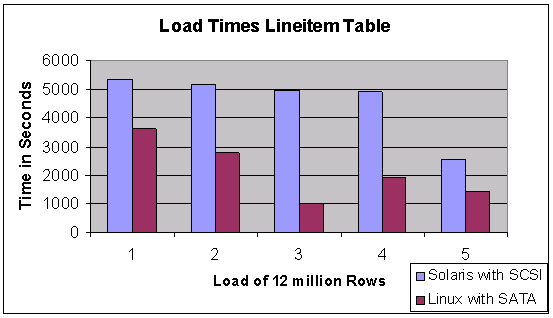
Figure 2: Example load time comparison.
As you can see, the load times were considerably less for the Linux cluster using SATA arrays verses the SCSI load.
Query Testing
We selected an example query from the query set generated from the qgen utility from the TPCH benchmark and used the Quest benchmark tool to submit it as 100 simultaneous queries, we then ran this test several times on each box. The results are shown in figure 3.
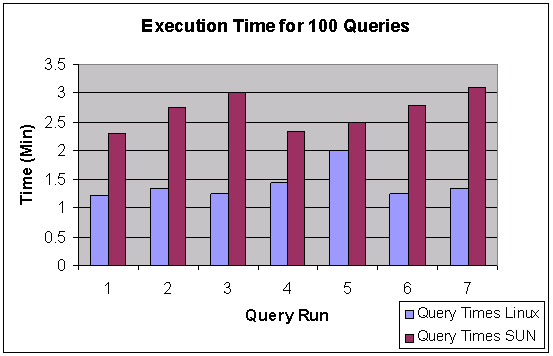
Figure 3: Query results.
As you can see, the Linux server once again beat the Sun server in simultaneous access from 100 users executing a query. The fluctuation in query five for the Linux box was due to all users being assigned to a single node in the cluster.
One interesting result from the testing was that, in using the client-side load balancing in OracleNET, we couldn’t get the load balancing algorithm to ever assign users to the fourth node in the cluster. We got user-to-node spreads of 60/40/0/0, 33/33/34/0, 100/0/0/0, and 50/50/0/0, but in all seven runs, we never got any users assigned to the fourth node. This highlights the fact that Oracle’s RAC load balancing must be done at the server level instead of the client level if you want equal use of the machines.
We assume we could have gotten even more interesting results if we had used parallel query as well as RAC, but we wanted to simulate just the placement of an existing system into a RAC environment.
Conclusions
All of this information leads to the following conclusions:
- Linux on Intel performance beats typical Sun installations
- SATA Array performance keeps up with native FC Arrays
- Placing an application onto RAC can provide performance improvements without requiring excessive modification of the application
- Oracle ASM is very sensitive to disk array arrangement
I hope you find this article useful in helping to decide if conversion to Oracle RAC on commodity hardware is the right decision. However, each application is different, and you should thoroughly test your application in a RAC environment before committing to such a venture.
--
Mike Ault is one of the leading names in Oracle technology. The author of more than 20 Oracle books and hundreds of articles in national publications, Mike Ault has five Oracle Masters Certificates and was the first popular Oracle author with his book Oracle7 Administration and Management. Mike also wrote several of the “Exam Cram” books, and enjoys a reputation as a leading author and Oracle consultant.
Contributors : Mike Ault
Last modified 2005-06-22 12:02 AM