
Database Recovery Control in Practice - Part 5: BDRC Registration
From Database Recovery Control (DBRC) in Practice by Peter Armstrong (Third Edition); copyright 1990 BMC Software.
Part 1 | Part 2 | Part 3 | Part 4 | Part 5 | Part 6
Registration is for physical DL/I and Fast Path data entry databases, including VSO DEDBs. There is no support in DBRC for main storage databases (MSDB) or generalized sequential access method (GSAM). Partitioned databases are registered to DBRC as databases with multiple data set groups (DSgroups). In other words, there will be one INIT.DBDS for each partition. You cannot combine DSgroups and partitions in one database. This means that DBRC does not actually recognize the existence of partitions. As far as DBRC is concerned, it is one database; while you can copy or read partitions in parallel, you cannot run updating utilities against partitions in parallel as DBRC only allows utilities to share at the database level, not at the block level. If you want to update multiple partitions in parallel with batch jobs, then you must run these as BMPs or use n-way sharing.
Database Registration
In order for DBRC to use Share Control (or Recovery Control if you are a coward) for a particular database, you must tell DBRC which databases you want it to control. This is done with two commands: INIT.DB and INIT.DBDS (plus INIT.ADS for Fast Path).
INIT.ADS provides the extra area information required for Fast Path. If you are using multiple area data sets, you issue one INIT.ADS for each copy of the area, minimum one, to a maximum of seven. You'll see more details on Fast Path DEDB registration and a sample MADS record later in this article.
The INIT.DB command is used to define a database and provide data sharing information. The INIT.DBDS command is used to define the database data sets and to provide recovery related information. The SHARELVL parameter on the INIT.DB command specifies the maximum level of sharing desired:
- Level 0 means that DBRC will ensure no sharing occurs.
- Level 1 means database level sharing is allowed.
- Level 2 means block level sharing in one MVS image.
- Level 3 means block level sharing across multiple MVS images.

Figure 10: Sample DB record.

Figure 11: Sample DBDS record.
Some of the parameters in the INIT.DBDS command are as follows:
• RECOVABL/NONRECOV
The default for databases is that they
are recoverable-in other words that you will use image copies plus
logs/change accumulations to recover them.
However, there are some databases that you may never want to recover this way, e.g. work databases that you simply reinitialize. NONRECOV is designed for these. (You cannot specify NONRECOV for a Fast Path DEDB.)
If you register a database as NONRECOV, you are not required to image copy it and DBRC will not record any ALLOC/LOGALL information for it in RECON. As far as DBRC is concerned, the database never gets updated. To recover it, you will reload it, reinitialize it, or use SECONDARY INDEX UTILITY/EP, or take one image copy at the beginning and use GENJCL.RECOV RESTORE to restore it from this original image copy.
IMS will write before images to the log in case backout is required, but it writes no after images. At archive time, the before images are not copied across to the SLDS or RLDS for NONRECOV databases. This means that dynamic backout and /ERE backout and batch backout from batch logs perform normally, but you cannot run batch backout for NONRECOV databases in an online system (e.g., after /ERE failure) from a SLDS-this can only be done from the OLDS. This can also have implications on disaster recovery procedures.
• GENMAX
Use this to say how many generations of image
copy data sets you want DBRC to remember for this particular database
data set. For example, if you set GENMAX to three, DBRC keeps
information about the latest three image copies for this database data
set in RECON.
• REUSE/NOREUSE
This parameter dictates how you are going to allocate your image copy output data sets.
REUSE tells DBRC you are going to predefine GENMAX image copy data sets for later use by the image copy utility. DBRC reuses these data sets in a round-robin fashion. This is designed for pre-allocated data sets on DASD. If you use REUSE, issue INIT.IC commands for the number of generations you wish DBRC to record, i.e., if GENMAX=3, then register three image copy output data sets in RECON for this database data set. If they are on DASD, you must physically allocate them using IEFBR14. You should use GENJCL.IC to generate your image copy JCL with the correct output data sets. Your skeletal JCL will contain:
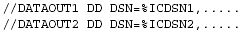
Figure 12: Image copy skeletal JCL with REUSE.
DBRC fills in the appropriate data set names, VOLSERs, etc., from the information you have stored in RECON via the INIT.IC commands.
NOREUSE tells DBRC that there are no predefined data sets in RECON. DBRC picks up the information from your JCL when you run the image copy and stores the information in RECON. This is the way to use DBRC with GDGs. Define NOREUSE and do not issue any INIT.IC commands. Use the same JCL every night (you won't use GENJCL.IC). Your JCL will look like this:
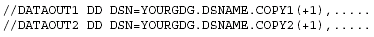
Figure 13: Image copy skeletal JCL with NOREUSE.
DBRC stores the fully expanded GDG name in RECON after successful completion of the utility.
• RECOVPD
With the RECOVPD parameter, you are instructing
the system to retain image copy data sets until they are over n days
old. The parameter interacts with GENMAX and REUSE/NOREUSE. It is best
explained with an example.
Say you have GENMAX set at 3 and RECOVPD at 20 days. If you run the fourth image copy when the first image copy is only 15 days old, the first image copy is not thrown away. If you specified NOREUSE, DBRC dynamically changes GENMAX from 3 to 4 and does not automatically change it back later. One customer has implemented a procedure that tries to reset GENMAX at the end of each day; DBRC will only reduce GENMAX and delete the extra generations if they are outside the RECOVPD. Alternatively, you can have a look at my GENJCL.USER Examples and Description manual (top of the Falkland Islands reading list last winter) for an example of cleaning up GENMAX. Database Registration
If you specify REUSE, DBRC does not find a fourth generation in RECON and the job fails. You then have to change GENMAX, issue another INIT.IC command, allocate the output data set(s), and rerun GENJCL
GENMAX Cycle - Log Cleanup in RECON
When GENMAX is exceeded (e.g., you have set it at three image copies and you create a fourth image copy that causes the first one to be discarded), many cleanup operations occur. The oldest image copy is deleted. Now IC2 is the oldest image copy for this database. DBRC deletes any ALLOC records that occurred prior to what is now the oldest image copy (IC2). The same cleanup occurs for reorganization records and recovery records.

Figure 14: Log cleanup in RECON.
When ALLOC records are discarded, DBRC performs maintenance on the LOGALL record associated with the PRILOG record referenced by the ALLOC records. Records that are associated with logs (i.e., PRILOGs, PRISLDs, etc.) are not automatically deleted. To delete these records, DBRC control statements must be issued, followed by a RECON reorganization.
The correct command to use in a Recovery Control or Share Control environment is DELETE.LOG INACTIVE — see "DELETE.LOG INACTIVE" for more details.
Size of RECONs
If you are using DBRC Recovery Control or Share Control, RECON must keep records for the maximum value of
GENMAX x Image Copy Frequency
If you have a database you copy once per month and you have an installation default of six generations, the RECONs must be large enough to hold six months worth of recovery-related information. Keep your RECONs small-they are a potential bottleneck, especially when shared between multiple jobs/MVS images. Do not submit 500 image copy jobs at the same time-the enqueues will be horrendous. Group databases together in job steps, and design your jobs to "get in and out" of the RECONs as fast as possible.
Change Accumulation Registration

Figure 15: Sample CAGRP record.
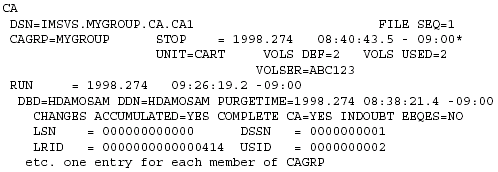
Figure 16: Sample CA record.
Use the INIT.CAGRP to register CAGRPs in RECON. Some of the parameters are as follows:
• GRPMAX
GRPMAX is similar to the GENMAX parameter on the
INIT.DBDS command. GRPMAX specifies how many generations of change
accumulation data sets you want to maintain for this group.
• REUSE/NOREUSE
These are similar to the parameters
specified for image copies. REUSE allows you to predefine to DBRC a
number of data sets (using INIT.CA commands, followed by IEFBR14) to be
used for output for this change accumulation group in a round-robin
fashion. You should use GENJCL.CA. Your skeletal JCL will contain the
following:
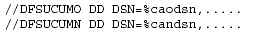
Figure 17: Change Accumulation Skeletal JCL with REUSE.
DBRC fills in the appropriate data set names, VOLSERs, etc., from the information you have stored in RECON using the INIT.CA commands. NOREUSE tells DBRC there are no predefined data sets in RECON. DBRC picks up the information from your JCL when you run the change accumulation and stores it in RECON. This is the way to use DBRC with GDGs. Define NOREUSE and do not issue any INIT.CA commands. Your JCL will not be the same every time because the logs selected will be different. So use GENJCL.CA and set up your skeletal JCL to look like this:
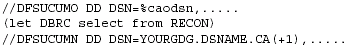
Figure 18: Change Accumulation Skeletal JCL with NOREUSE.
DBRC stores the fully expanded GDG name in RECON after successful completion of the utility.
It is possible to generate multi-step jobs with DBRC. For example, you can use the VOLNUM parameter on GENJCL.CA to create a new step each time the VOLNUM number of input log volumes is exceeded. If you use GDGs, this can cause problems as DBRC generates the same GDG numbers in each step. The solution to this is to use the %SET keyword in your skeletal JCL to select a new skeletal JCL member for the next step. For example, skeletal JCL member 1 finishes with a %SET for member 2. Member 1 uses GDG(0), member 2 uses GDG(+1), etc.
DSLOG
Do NOT use this facility-it is slow, inefficient, a nightmare for the data administrator, and is no longer supported in IMS V3, and oh yes I absolutely hate(d) it!
Reordering DSGroups
You cannot reorder data set groups in a database without deleting the database from the RECONs. Unload the database, DELETE.DB it from the RECONs, re-register it, and then reload it.
At registration time, DBRC assigns a data set ID to each DBDS record. If you change the order of the data set groups, reorganization gets confused-"Data set identifier in DBDLIB and RECON do not match."
DBDS Groups and DB Groups
A DBDS group is a named collection of DBDSs or DEDB areas. DBRC can perform various operations by DBDS group so that you do not have to repeat the command for every member of the group.
INIT.DBDSGRP GRPNAME(name) MEMBERS((dbname,ddname),..) When you specify a DBDS group on a command, DBRC invokes that command for each member of the DBDS group. Groups can be used on the LIST command and GENJCL.USER command-have a look at my GENJCL.USER Examples and Description manual for some examples.
You can also specify a CA group as a DBDS group. DBRC then executes the command for each member of the CA group.
You can define as many DBDS groups as you wish. Up to 1024 DBDSs can be in a group (2000 in IMS V6). All DBDSs in a group must be registered in RECON. A DBDS can belong to more than one DBDS group. A DBDS group can be "implied." An implied DBDS group exists for each database registered in RECON. The members of this implied group consist of all DBDSs of the database. To use an implied group, specify the database name without specifying a ddname on the above GENJCL and LIST commands.
When using DBDS groups, DBRC holds and releases RECON for each execution of the command for each member DBDS. As a result, integrity of the output is preserved for each DBDS but may not be preserved across the group. This is because RECON may have changed between its last release and hold. The trade-off here is that performance could be adversely affected if DBRC were to hold RECON while processing an entire DBDS group. A DB group is a named collection of databases or DEDB areas. A DB group name can be specified in the /START, /STOP, and /DBRECOVERY commands instead of issuing these commands separately for each database or area. This greatly reduces the number of times these commands must be issued. Use the DATAGROUP keyword to specify the DB group name.
INIT.DBDSGRP GRPNAME(name) DBGRP(dbname,..)
You can define as many DB groups as you wish. Up to 1024 databases or areas may be in a group (2000 in IMS V6). A database or area can belong to more than one DB group and need not be registered in RECON. Note: Although a DBDS group can be used as a DB group, you should use a database group whenever possible. Processing a DBDS group as a DB group entails increased overhead.
Fast Path users are recommended to read the Guide to IMS/VS Version 1.3 DEDB Facility manual, GG24-1633. This is an excellent and comprehensive manual. This article only contains a few summary points.
Registration
There are some extra parameters on the INIT.DBDS command for Fast Path DEDBs:
• PREOPEN|NOPREO
are mutually exclusive, optional
parameters you use to specify whether an area is to be opened after the
first checkpoint following the next control region initialization or
when the next /START AREA command is processed. The default is NOPREO.
If you specify PRELOAD, then PREOPEN is the default.
• VSO|NOVSO
are mutually exclusive, optional parameters
you use to specify whether an area will reside in virtual storage the
next time the control region is initialized or when the next /STA AREA
command is processed.
• CFSTR1(name)
is an optional parameter you use to specify the name of the first coupling facility structure for the identified area.
• CFSTR2(name)
is an optional parameter you use to specify the name of the second coupling facility structure for the identified area.
• LKASID|NOLKASID
are mutually exclusive optional
parameters you use to specify whether local data caching for the
specified area is used for buffer lookaside on read requests.
• PRELOAD|NOPREL
are mutually exclusive, optional parameters you use to specify whether a VSO area is to be loaded the next time it is opened.
The other differences from the DL/I DB specifications already discussed are as follows:
• INIT.DB
for DEDBs, code the additional parameter TYPEFP. The default is TYPEIMS.
• INIT.DBDS
Instead of coding DDN(name), you should code AREA(name).
• INIT.ADS
Fast Path DEDBs can have multiple area data
sets (i.e., multiple copies of the same areas). To provide DBRC with
the necessary information to control the multiple data sets, this
command must be issued once for each copy of each area registered (even
if you are only using single area data sets).
If a Fast Path database is registered in RECON, then IMS can use this information for dynamic allocation-there is no need to run the DFSMDA macro for them.
Multiple Area Data Sets
MADS allow you to continue accessing the whole of an area, even if one or more CIs are bad (read from another copy). It requires DBRC Recovery or Share Control. The area data sets must be registered in RECON using the INIT.ADS command.
New utilities:
- MADS Compare and MADS Create provide in-flight recovery.
- Concurrent Image Copy provides in-flight copy.
Image copy runs as long as there is at least one good copy of each CI available. Bad CIs are indicated via the presence of EQEs in the second CI of the area data sets. A maximum of ten are allowed before the area data set stops.

Figure 19: Sample MADS record.
Flags and Counters
The following charts show how the Fast Path utilities and DBRC commands interact with the flags in RECON:
- PFA = Prohibit Further Authorization
High Speed Sequential Processing (HSSP)
This was a new feature introduced in IMS V3; it allows batch-type programs (BMPs) to do track I/O against a DEDB instead of block I/O (gosh, there's a good idea, I wonder where I've seen that before?!). It could also take an image copy as it was working its way through the area. Internally it was using the cache in the DASD control units, and it transpired that the hardware gave you the performance improvements and the HSSP benefit was unpredictable and often not significant.
Command Record Flag/Status

Figure 20: Interaction of flags and commands for Fast Path.
DEDB Init Image Copy Full Recovery
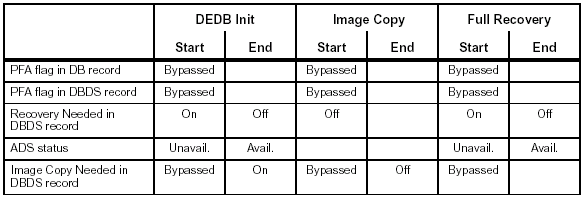
Figure 21: Interaction of flags and utilities for Fast Path.
Now, no one understood how all this worked and I never met anybody who used it. Fortunately, it all got totally rewritten in IMS V5, with the result that it is now simple, comprehensible, and works. The principle is still the same, as you work your way through the database with a BMP, it takes an image copy at the same time and registers this in RECON. However, nowadays it is using software techniques and central storage to achieve performance improvements, with chained reads, look-ahead reading etc.
The V5 HSSP Image Copy option is also totally new. It now runs asynchronously-in parallel with and slightly behind HSSP application processing-and creates a standard image copy.
HSSP requires the DEDB to be registered as REUSE if you want to use the Image Copy feature. Image copies created by HSSP are Concurrent Image Copies.
One other thing to watch out for with HSSP image copies is that the term "sequential" must be taken literally. If you try to take an HSSP image copy with an application that does random processing instead of sequential, you can expect the application to promptly go into convulsions and die.
Part 1 | Part 2 | Part 3 | Part 4 | Part 5 | Part 6
--
Peter Armstrong joined IBM in 1976 and was the UK Country IMS specialist. He helped design parts of DBRC and wrote the Recovery/Restart procedures for IMS disk logging. He joined BMC in 1986 and travels the world discussing computing issues with customers, analysts, etc. He has used all this technical and practical experience to write a book on how DBRC works in practice rather than a boring theoretical tome. He hopes you will enjoy it.
Peter Armstrong's Blog - Adopting a Service Mentality
Contributors : Peter Armstrong
Last modified 2006-01-04 12:54 PM