
An Introduction to DB2 Indexing
This article is adapted from the upcoming edition of Craig’s book, DB2 Developer’s Guide, 5th edition. This new edition, which will be available in May 2004, updates the book to include coverage of DB2 Version 7 and Version 8.
You can create indexes on DB2 table columns to speed up query processing. An index uses pointers to actual data to more efficiently access specific pieces of data. Once created, DB2 automatically maintains each index as data is added, modified, and deleted from the table. As data is selected from the table DB2 can choose to use the index to access the data more efficiently. It is important to remember that index modification and usage is automatic – that is, you do not need to tell DB2 to modify indexes as data changes nor can you tell DB2 to use a particular index to access data. This automation and separation makes it easy to deploy DB2 indexes.
To illustrate how an index works think about the index in a book. If you are trying to find a reference to a particular term in this large book, you can look up the word in the index, which is arranged alphabetically. When you find the word in the index, one or more page numbers will be listed after the word. These numbers point to the actual pages in the book where information on the term can be found.
Just like using a book’s index can be much faster than sequentially flipping through each page of a book, using a DB2 index can be much faster than sequentially accessing every page in a table. And, just like the book index, an index is only useful if the term you seek has been indexed.
A DB2 index is a balanced B-tree structure that orders the values of columns in a table. When you index a table by one or more of its columns, you can access data directly and more efficiently because the index is ordered by the columns to be retrieved.
Figure 1 depicts a simple b-tree index structure. By following the index tree structure data can be more rapidly accessed than by sequentially scanning all of the rows of the table. For example, a four level index (such as the one shown in the figure) can locate indexed data with 5 I/Os — one for each of the four levels and an additional read to the data page. This is much more efficient than a table scan which would have to access each table space page, of which there may be hundreds, thousands, or even millions depending on the size of the table.
There are 3 types of index data pages needed to form the internal index structure used by DB2: root, nonleaf, and leaf pages. The root page is the starting point of the search through an index. It is always at the top of the index structure and physically it is stored as the third page in the index space (after the header page and the space map page). Entries are made up of the key and RID of the highest key value contained in each page on the level below it. A RID is an internal “pointer” that uniquely identifies each row to DB2. The RID is made up of:
- Page number (3 or 4 bytes) — the page in the table space where the row is stored. The page number will be 4 bytes for LARGE table spaces; otherwise it will be 3 bytes.
- Identifier (1 byte) — the ID map entry number on the associated page that contains the page offset for the row.
So, DB2 index entries are made up of a key and a RID. But when multiple rows exist with the same key value, the index entry will contain a single key followed by chain of RIDs.
Nonleaf pages are index pages that point to other index pages. When the number of levels in an index reaches 3, the middle level will be this type of page. Prior to the index reaching 3 levels, there are no nonleaf pages in the internal index structure (just a root page that points to leaf pages). Entries in nonleaf pages are made up of the key and RID of the highest key value contained in each page on the level below it. Leaf pages contain key/RID combinations that point to actual user data rows.
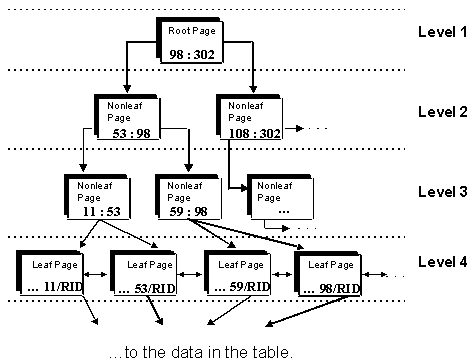
Figure 1: Conceptual diagram of a B-tree index structure.
Let’s clarify these points by examining the simplified index structure in Figure 1 a little more closely. Suppose we wanted to find a row containing the value 59 using this index. Starting at the top we follow the left path because 59 is less than 98. Then we go right because 59 falls between 53 and 98. Then we follow the link to the leaf page containing 59. Leaf pages are at the bottom-most level of an index (level four in this case). Each leaf page contains indexed values followed by one or more RIDs.
Creating Indexes
A proper indexing strategy can be the most important factor to ensure optimal performance of DB2 applications. However, indexing is most likely improperly implemented at most DB2 sites. This is so due to the nature of database development. Database objects typically are created near the beginning of a project[md]after the logical data model has been transformed into a physical database design, but before any application code or SQL has been written. So the DBA takes an initial best guess at creating some indexes on each table. Of course, indexes are best designed based on how the data will be accessed. Without the SQL, proper indexes cannot be created. Therefore, as the development process progresses an iterative approach is taken to index creation. New indexes are created to support new queries; old indexes are removed if they are not being used. Such an approach is fraught with potential problems, but such is life.
An index is created using the CREATE INDEX statement, which is similar in several ways to the CREATE TABLESPACE statement. Both require the user to specify storage (USING, PRIQTY and SECQTY), free space (PCTFREE and FREEPAGE), a buffer pool (BUFFERPOOL), and how to close the underlying data sets (CLOSE). However, there are also many differences.
One big difference is that separate CREATE statements are not used to create an index and an index space. An index space is the underlying storage structure for index data and it is automatically created by DB2 whenever an index is created. There can only ever be one index in an index space. Of course, there are many other differences because indexes are different than table spaces, and serve different data processing needs.
In DB2, uniqueness is enforced using an index. You can create a unique index that forces the columns specified for the index to be unique within the table. If you try to INSERT or UPDATE these columns with non-unique values, an error code is returned and the request fails.
Creating a unique index is the only way to ensure uniqueness for a column (or columns) in DB2. You can have more than one unique index per table. It usually is preferable to enforce the uniqueness of columns by creating unique indexes, thereby allowing the DBMS to do the work. The alternative is to code uniqueness logic in an application program to do the same work that DB2 does automatically. Remember: If security is liberal for application tables, ad hoc SQL users can modify table data without the application program, and thereby insert or update columns that should be unique to non-unique values. However, this cannot happen if a unique index is defined on the columns.
You can use an index to guide DB2 to control how table space data is physically stored on disk. This is called clustering. A DB2 index is a clustering index if the CLUSTER keyword is specified when the index is created. Clustering causes inserted rows to be stored contiguously in sequence whenever possible. Additionally, when the table space is reorganized the data will be sequenced according to the clustering index. Since there can only be one physical sequence for data on disk, there can only be one clustering index per table. If you do not specify a clustering index DB2 will choose to cluster the data using the oldest existing index. It is wise to explicitly specify a clustering index instead of letting DB2 decide because you will almost always choose better than the (basically random) choice DB2 makes.
Indexes also can be used to control partitioning. Prior to DB2 V8, a partitioning index was the only way to partition data. As of V8, though, partitioning can be specified and controlled in the table DDL. Notwithstanding this separation of partitioning from indexing, an index can be partitioned itself into separate data sets.
Indexed columns can be specified as ascending or descending. This is accomplished by specifying either ASC or DESC after each column in the index. Specifying ASC causes index entries to be in ascending order by the column (this is the default). DESC puts the index entries in descending order by the column.
Finally, through the use of the DEFINE and DEFER parameters DB2 can delay the creation of the index and its data sets until a later time.
Before creating any indexes, you should analyze your data and consider the following factors:
- Percentage of table access versus table update
- Data access patterns, both ad hoc and planned
- Amount of data accessed by each query against the table
- Performance requirements of accessing the table
- Performance requirements of modifying the table
- Frequency of INSERT, UPDATE, and DELETE operations
- Storage requirements
- Impact on recovery
- Impact of reorganization
- Impact on the LOAD utility
Remember that indexes are created to enhance performance. But although an index may speed up the performance of a query, each new index will degrade data modification. Keep the following in mind as you create indexes:
- Consider indexing on columns used in UNION, GROUP BY, ORDER BY, and WHERE clauses.
- Limit the indexing of frequently updated columns.
- If indexing a table, explicitly create a clustering index. Failure to do so will result in DB2 clustering data by the first index created. If indexes are subsequently dropped and recreated, this can change the clustering sequence if the indexes are created in a different order.
- Consider clustering on columns in GROUP BY and ORDER BY specifications to improve sequential access.
- If no sorting or grouping is required, analyze your WHERE clauses and cluster on the columns most frequently referenced; or better yet, most frequently run.
- Choose the first column of multicolumn indexes wisely, based on the following hierarchy.
First, choose columns that will be specified most frequently in SQL WHERE clauses (unless cardinality is very low). Second, choose columns that will be referenced most often in ORDER BY and GROUP BY clauses (once again, unless cardinality is very low). Third, choose columns with the highest cardinality.
- The biggest payback from an index comes from DB2’s capability to locate and retrieve referenced data quickly. DB2’s capability to do this is reduced when cardinality is low because multiple RIDs satisfy a given reference. Balance the cardinality of a column against the amount of time it is accessed, giving preference to data access over cardinality.
- There are no hard and fast rules for index creation. Experiment with different index combinations and gauge the efficiency of the results.
- Keep the number of columns in an index to a minimum. If only three columns are needed, index on only those three columns. As more columns are added to the index, data modification degrades.
- Sometimes, however, it can be advantageous to include additional columns in an index to increase the chances of index-only access. (Index-only access is discussed further in Chapter 21 “The Optimizer.”) For example, suppose that there is an index on the DEPTNO column of the DSN8810.DEPT table. The following query may use this index:
SELECT DEPTNAME
FROM DSN8810.DEPT
WHERE DEPTNO > 'D00';
DB2 could use the index to access only those columns with a DEPTNO greater than D00, and then access the data to return the DEPT.
| Note: The number one rule for index creation is to keep creating indexes to enhance the performance of your queries until the performance of data modification becomes unacceptable. Then delete the last index you created. This general approach is best described as keep creating indexes until it hurts. |
Indexing Large and Small Tables
For tables over 100 pages, always define at least one index. As the table grows larger (over 1,000 pages), try to limit the indexes to those that are absolutely necessary for adequate performance. When a large table has multiple indexes, update performance can suffer. When large tables lack indexes, however, access efficiency usually suffers. This fragile balance must be monitored closely. In most situations, more indexes are better than fewer indexes because most applications are query-intensive rather than update-intensive.
For tables containing a small number of pages, for example up to 50 pages, create appropriate indexes to satisfy uniqueness criteria or if the table frequently is joined to other tables. Create indexes also when the performance of queries that access the table suffers. Test the performance of the query after the index is created, though, to ensure that the index helps. When you index a small table, increased I/O (due to index accesses) may cause performance to suffer when compared to a complete scan of all the data in the table.
When to Avoid Indexing
Really, there are only a few situations when you should consider not defining indexes for a table. Consider avoiding indexing when the table is very small, that is, less than 10 pages. However, there are scenarios where even a small table can benefit from being indexed (for example, for uniqueness or for specific, high-performance access requirements).
Another scenario where indexing might not be advantageous is when the table has heavy insert and delete activity but is relatively small, that is, less than 20 pages.
A table also should not be indexed if it always is accessed with a scan — in other words, if there is no conditional predicate access to the table.
Sometimes you should not define indexes for specific columns. If the column is updated frequently and the table is less than 20 pages, do not place that column in an index.
Additionally, avoid defining an index for a column if an index on the column exists that would make the new index redundant. For example, if an index exists on (COL1, COL2) in TABLE1, a second index on COL1 only is redundant. An index on COL2 alone is not necessarily redundant because it is not the first column in the index.
Indexing Variable Columns
Prior to Version 8, when indexing on a variable column, DB2 automatically pads the variable column out to its maximum size. So, for example, creating an index on a column defined as VARCHAR(50) will cause the index key to be padded out to the full 50 bytes. Padding poses several problems. You cannot get index only access with a padded index because DB2 will always have to access the table space data to retrieve the actual size of each column.
Remember, the size of a variable length column is stored in a two-byte prefix and this information is not in a padded index. Also, padding very large variable columns can create very large index with a lot of wasted space.
DB2 V8 offers the capability to direct DB2 whether variable columns in an index should be padded or not. Appropriately enough, a new keyword, PADDED (or NOT PADDED) can be specified when creating indexes. The specification is made at the index level — so every variable column in the index will be either padded or not padded.
When PADDED is specified DB2 will create the index just as it did prior to V8 — by padding all variable columns to their maximum size. When NOT PADDED is specified DB2 will treat the columns as variable and you will be able to obtain index only access. The length information will be stored in the index key.
Keep in mind that DB2 cannot perform index only access using a padded index — even if every required column exists in the index. This is so because the actual length of the VARCHAR column(s) is not stored in a padded index. So, DB2 will have to access the table to retrieve the length from the two-byte column prefix.
Indexing and Partitioning
The indexing requirements for partitioning change significantly in DB2 Version 8. For all releases of DB2 up through and including Version 7, a partitioning index is required to specify the limit keys for each partition — this means that a partitioning index was required and was used to determine which data goes into which partition.
But this all changes with DB2 Version 8. To understand partitioning in DB2 V8, first we need to define some terminology: namely, partitioned versus partitioning.
Partitioned and non-partitioned — a partitioned index means that the index itself is physically partitioned into separate data sets; a non-partitioned index, though, may still be a partitioning index.
Partitioning and secondary index — a partitioning index means that the index keys correlate to the columns that are used to partition the data. The index may or may not also be partitioned.
Control of partitioning changes from index-controlled to table-controlled as of DB2 V8.
Actually, DB2 V8 supports both types of partitioning, but table-controlled partitioning enables new features that are not supported under index-controlled partitioning. For example, the ability to easily add or rotate partitions is only supported with table-controlled partitioning.
DB2 will automatically switch from index-based to table-based partitioning if any of the following operations are performed:
- Dropping the partitioning index
- Altering the partitioning index to be not clustered
- Adding a partition using ALTER TABLE ADD PART
- Rotating partitions using ALTER TABLE ALTER PART ROTATE
- Altering a partitiong using ALTER TABLE ALTER PART n
- Creating a data-partitioned secondary index (DPSI)
- Creating an index with the VALUES clause, but without the CLUSTER keyword
When creating partitioned table spaces using DB2 Version 8 or greater, use table-controlled partitioning instead of index-controlled partitioning. Also, you should seriously consider switching your current index-controlled partitioning structures to be table-controlled because of the additional flexibility and functionality it provides.
Clustering and Partitioning
Prior to DB2 V8, the partitioning index for a partitioned table space had to be a clustering index. This means that the data in the table space had to be clustered by the partitioning columns. As of DB2 V8, though, data in a partitioned table space no longer needs to be clustered by the partitioning key. That is, clustering and partitioning are completely independent from each other as of V8.
Data Partitioned Secondary Indexes
One of the biggest problems DBAs face when they are managing large partitioned DB2 table spaces is contending with non-partitioned indexes. DB2 Version 8 helps to remedy these problems with a new type of index — the data partitioned secondary index, or DPSI (pronounced dipsy). However, before we examine the solution, let’s first investigate the problem in a little more detail.
Problems With NPIs
Prior to V8, a partitioning index was required in order to define a partitioned table space. The CREATE INDEX statement specifies the range of values that DB2 will store in each specific partition. The partitioning index will have individual PART clauses, each which specifies the highest value that can be stored in the partition. To illustrate, consider the following SQL to create a partitioning index:
CREATE INDEX XEMP2
ON DSN8710.EMP (EMPNO ASC)
USING STOGROUP DSN8G710
PRIQTY 36 ERASE NO CLUSTER
(PART 1 VALUES('H99'),
PART 2 VALUES('P99'),
PART 3 VALUES('Z99'),
PART 4 VALUES('999'))
BUFFERPOOL BP1
CLOSE YES
COPY YES;
This creates four partitions. Behind the scenes, DB2 will create four separate data sets — both for the table space data and for the index data. However, every other index defined on the table will be a "regular" DB2 index — that is, a non-partitioning index (NPI). This index resides in a single data set unless the PIECESIZE clause is used to break it apart — and even then the data will not be broken apart by partition.
NPIs can cause contention, particularly with DB2 utilities. You can run a utility against a single table space or index partition, but you do not have that luxury with NPIs because they are not partitioned. You can minimize and manage downtime by running utilities a partition at a time. However, running utilities against NPIs can impact an entire table space. Additionally, contention on NPIs can cause performance bottlenecks during parallel update, insert, and delete operations.
Solving Problems with DPSIs?
DB2 V8 introduces the Data Partitioned Secondary Index, or DPSI. DPSIs are significant because they help to resolve the problems involved with NPIs discussed in the preceding section. A DPSI is basically a partitioned NPI.
Consult Figure 2 for a graphical depiction of the difference between a DPSI and an NPI. This diagram shows a table space partitioned by month. We need to build an index on the CUSTNO for access requirements - but we have a choice as to whether we create an NPI or a DPSI. You can see the different results in the diagram: the DPSI will be partitioned by the same key ranges as the table but the NPI will not be partitioned at all.
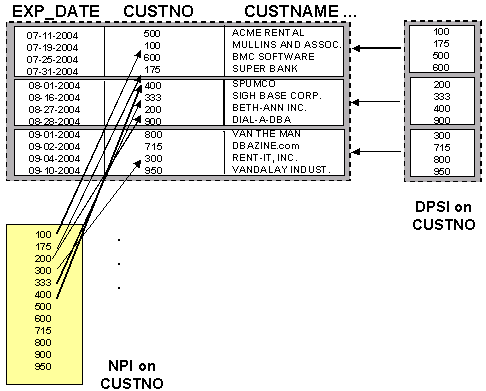
Figure 2: DPSI versus NPI.
So, with a DPSI the index will be partitioned based on the data rows. The number of parts in the index will be equal to the number of parts in the table space — even though the DPSI is created based on columns that are different from those used to define the partitioning scheme for the table space. Therefore, partition 1 of the DPSI will be for the same rows as partition 1 of the table space, and so on. These changes provide many benefits including:
- The ability to cluster by a secondary index
- The ability to drop and rotate partitions easily
- Potentially less overhead in data sharing
NPIs historically have caused DB2 performance and availability problems, especially with utilities. DPSIs solve many of these problems. With DPSIs there is an independent index tree structure for every partition. This means that utilities do not have to share pages or index structures. In addition, logical drains on indexes are now physical at the partition level. This helps utility processing in several useful ways. For example, you can run a LOAD by partition with no contention because the DPSI is partitioned the same way as the data and the partitioning index. Additionally, when reorganizing with DPSIs, the BUILD2 phase is not needed. Even your recovery procedures may be aided because you can copy and recover a single partition of a DPSI.
However, DPSIs are not magical objects that solve all problems. Indeed, changing an NPI to a DPSI will likely cause some queries to perform worse than before. Some queries will need to examine multiple partitions of the DPSI as opposed to the single NPI it previously used. On the other hand, if the query has predicates that reference columns in a single partition only, then performance may improve because only one DPSI partition needs to be probed.
Keep in mind that each DPSI partition has its own index structure. So, a query could potentially have to probe each of these individual index structures to use the DPSI. This type of operation, obviously, will not perform as well as a single probe that would be required against the NPI. So, of course, not every index on a partitioned table should be a DPSI. An additional drawback is that a DPSI cannot be defined as a unique index.
The bottom line on whether to create DPSIs or NPIs is that you will need to analyze your data access and utility processing requirements. DPSIs are easier to manage and can be processed more efficiently by utilities, but can require special query formulation to be efficient. NPIs are typically most efficient for general purpose queries but come with a lot of administration baggage.
Before using DPSIs, you will have to examine your queries to determine predicate usage and the potential performance impact.
Modifying Indexes
As data is added to the table, it is also added to every index defined on the table. For INSERT operations, new keys are placed in the proper sequence in the index. Existing keys are moved to the right to make room for the new entry. If there is not enough room on the page for the new entry, DB2 will try to find space on neighboring pages or on the next free page. When a neighboring page is used, DB2 attempts to redistribute entries in the pages to accommodate the INSERT operation.
As data is deleted from the table, it must also be removed from every index defined on the table. The more indexes defined to a table, the more time it will take for DB2 to perform DELETE operations.
For UPDATE operations, indexes are impacted only if the columns being modified participate in an index. The more indexes containing the columns being modified, the longer the UPDATE will take.
Forming Index Levels
As data is added to the index it will grow and change. For very small indexes, the root page can also act as a leaf page. As data is added, the root page will fill up. When the index becomes too large to accommodate both root and leaf page data, DB2 will create two new leaf pages. Each of these leaf pages will contain half of the entries that were in the original root page. And the root page will contain pointers to the leaf pages. You have just witnessed the birth of a new index.
Over time, as more data is added, more index entries are added. Eventually, the root page grows too large causing DB2 to create two more new pages. These will be nonleaf pages, each containing half of the entries that were in the root page. The root page now contains pointers to nonleaf pages — and thus, another new level is borne.
The greater the number of levels in an index, the less efficient it becomes. This is so because DB2 will need to perform an additional I/O operation for an index lookup for each new level in the index.
Some General Index Guidelines
Create a Unique Index for Each Primary Key: Every primary key explicitly defined for a table must be associated with a corresponding unique index. If you do not create a unique index for a primary key, an incomplete key is defined for the table, making the table inaccessible.
Promote Index Only Access: When an index contains all of the columns being selected in a query DB2 can choose to use index only access. With index only access, DB2 will read all of the data required from the index without having to access the table space. Index only access can reduce the number of I/Os required to satisfy a query. For example, consider the following query:
SELECT DEPTNAME, MGRNO
FROM DSN8810.DEPT
WHERE DEPTNO > 'D00';
Now, also consider that there is only one index on this table[md]a two column index on DEPTNO and MGRNO. DB2 will most likely choose to use this index to satisfy the DEPTNO > 'D00' predicate. But, if we add the DEPTNAME column to this index, DB2 can conceivable use this index for index only access because all of the required columns are stored in the index. So, it can be worthwhile to overload an index with an additional column or two to encourage index only access. However, this practice should be deployed with care; you do not want to overload every index because it will become unwieldy to manage.
Multicolumn Indexes: If a table has only multicolumn indexes, try to specify the high-level column in the WHERE clause of your query. This action results in an index scan with at least one matching column. A multicolumn index can be used to scan data to satisfy a query in which the high-level column is not specified (but another column in the index is specified). However, a non-matching index scan of this sort is not as efficient as a matching index scan.
Because DB2 can utilize multiple indexes in an access path for a single SQL statement, multiple indexes might be more efficient (from a global perspective) than a single multicolumn index. If access to the columns varies from query to query, multiple indexes might provide better overall performance for all your queries, at the expense of an individual query.
Multi-Index Access: DB2 can use more than one index to satisfy a data retrieval request. For example, consider two indexes on the DSN8810.DEPT table: one index for DEPTNO and another index for ADMRDEPT. If you executed the following query, DB2 could use both of these indexes to satisfy the request:
SELECT DEPTNO, DEPTNAME, MGRNO
FROM DSN8810.DEPT
WHERE DEPTNO > 'D00'
AND ADMRDEPT = 'D01';
If multi-index access is used, the index on DEPTNO is used to retrieve all departments with a DEPTNO greater than 'D00', and the index on ADMRDEPT is used to retrieve only rows containing 'D01'. Then these rows are intersected and the correct result is returned. Of course, an alternative to the multi-index access just described is a single multicolumn index on (ADMRDEPT, DEPTNO). Multi-index access is usually less efficient than access by a single multicolumn index.
Summary
In this article we have learned about DB2 indexes including the basics of how they work, how they can improve query performance, and the DDL required to create them. This introduction can be helpful as you start to understand how DB2 uses indexes to augment performance. Of course, there are a lot of details that you still must master in order to create DB2 indexes for performance.
--
Craig Mullins is an independent consultant and president of Mullins Consulting, Inc. Craig has extensive experience in the field of database management having worked as an application developer, a DBA, and an instructor with multiple database management systems including DB2, Sybase, and SQL Server. Craig is also the author of the DB2 Developer’s Guide, the industry-leading book on DB2 for z/OS, and Database Administration: Practices and Procedures, the industry’s only book on heterogeneous DBA procedures. You can contact Craig via his web site at http://www.craigsmullins.com.
Contributors : Craig S. Mullins
Last modified 2006-01-16 04:13 AM