
Existence Checking in DB2
Did you all know that when Glenn Tracy's daughter was little, he was talking to her as all good fathers do about life and other important stuff like where to find a good hot sauce. He said, "Do you see that sunset over there?"
She replied, "Why Father, of course I see it."
Glen proudly continued, "I did that."
She said, "Daddy, you don't know very much, do you? Mommy did the sunset!"
…The voice of authority hates to be busted ...
... even in DB2 Land. It happens to people who are supposed to know. They'll go nameless, not to protect them because they are innocent (they're not), but because we don't want anybody to know our names.
Best Way to Verify Existence and Other Mysteries
Several books and magazine articles suggest that the best way to verify the existence of a row is to do a SELECT COUNT(*) …WHERE. So programmers did. We copy code; we don't reinvent the wheel.
Well guess what? In this day and age when performance is desired, the COUNT(*) was found out to be not good - it is bad news. At its worst, it's a tablespace scan; at its best, it is still slower than other methods.
So other methods were taught that were said to be better. Later, another article came along saying, those methods aren't right; here's how it should be done. DBAs teaching the new employee class propagated some of the good and some of the bad (depending on whatever we'd last read). We stand by everything else we taught. Well, somebody has to be right and somebody has to be wrong. What is a DBA to do? Who are you going to believe?
Have you ever heard the phrase, 'it depends'? Its been a standard answer from IBM and DBAs for over 15 years, whenever they're asked a question. It's a phrase that has been beaten to death, and then beaten some more. Frankly, I'm tired of it myself. But for the question, "What is the best way to check existence?" 'it depends' is the answer.
But before we came up with that answer, it had to be unequivocally verified and true. We had to find out for sure, and establish credibility. Our goal was to be able to say, "The best way to verify existence is … (whatever it is)."
Obligatory disclaimer: We ran multiple sets of tests (to get averages) using DB2 V6, against tables with 24, 7, 4, and 46 million rows, some using indexes and some not. All that means is, when V7 comes along, there might (will probably?) be another way to check existence that is better.
Ready?
Four Methods for Existence Checking
There are four ways (that I know of) to check for existence:
Count SELECT COUNT(*)
FROM .
WHERE …
Singleton SELECT 1
FROM .
WHERE …
Non-Correlated SELECT 1
FROM SYSIBM.SYSDUMMY
WHERE EXISTS
(SELECT 1
FROM .
WHERE …)
Correlated SELECT 1
FROM SYSIBM.SYSDUMMY A
WHERE EXISTS
(SELECT 1
FROM . B
WHERE …
AND A.IBMREQD = A.IBMREQD )
The first set of tests were set up to test three sets of conditions and not using an index.
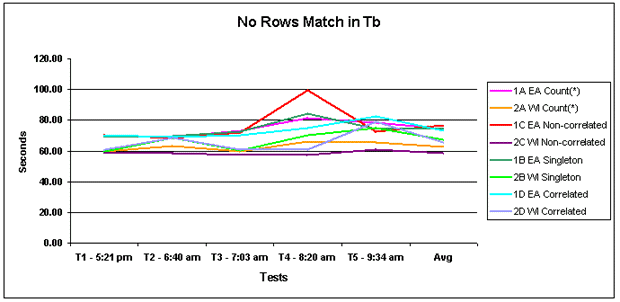
Figure 1: No rows found They all ran about the same amount of time
(80 to 90 seconds) and all read every row of the table (tablespace scan).
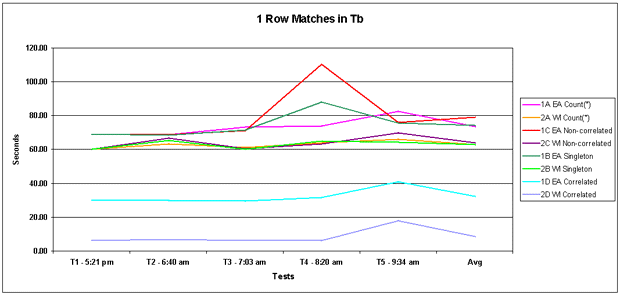
Figure 2: 1 Row found The correlated query was fastest (under 10 seconds). The singleton
was about 10 - 15 seconds faster than the other two (still 80 to 90 seconds).
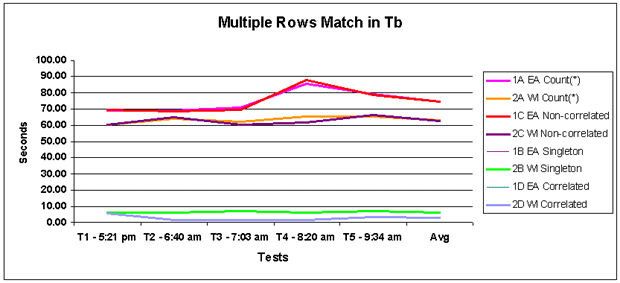
Figure 3: Multi-rows found The correlated query was still fastest
(under 2 seconds and can't be seen on the graph above), closely followed by
the singleton (2 - 3 seconds slower). The other two were still slow.
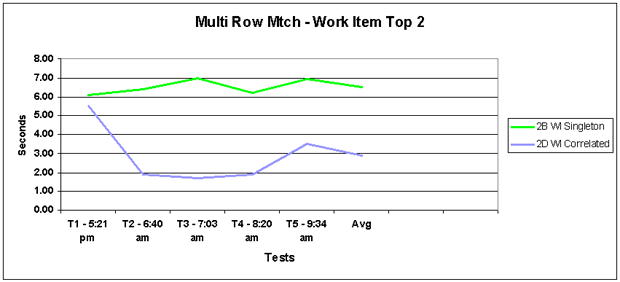
Figure 4: Multi-Row (Singleton and Correlated): Since the other graph couldn't quite clarify the distinction between the correlated and singleton for the 2.5 million row table, here it is.
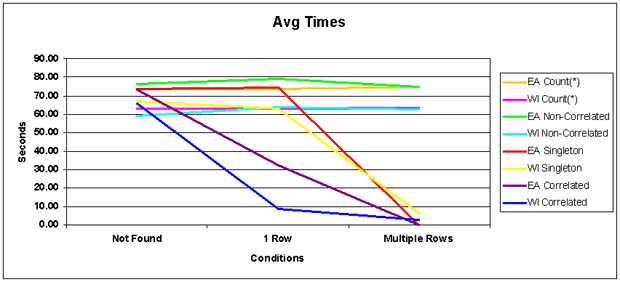
Now for the overall graphical depiction, the correlateds are better for one row and still a little better than the singletons for multiple rows.
After I learned how to graph using MS-Excel, I'm staring at the pretty pictures thinking "OK, now I know which way is best. I've run the tests against several tables with multiple conditions and everything is pretty conclusive. I can go to the programmers and say 'Jed, move away from there, correlated is the way to go, existence checks, better performance…'."
I do this.
"Au contraire, my blissful DBA friend," the friendly programmers countered, "The singleton is better."
"Let me have your query, I'll modify my test program and it will show the correlated is better," I shot back (in a friendly sort-of-way).
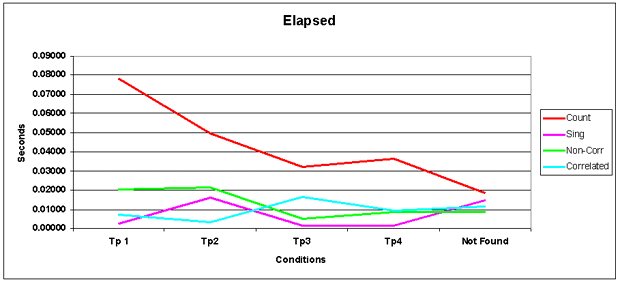
So, with four different conditions and not a found result, the singleton on average out-performs everybody else for elapsed times.
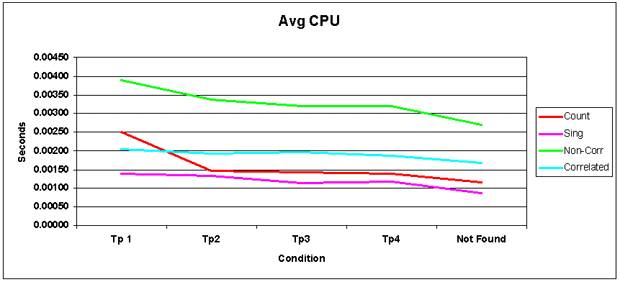
And the average CPU is all the way across the board.
What's up with this? These singletons are performing better than the correlated, and in some instances, the SELECT COUNT(*) is as well, but in my tests, it was the other way around.
Are you asking yourself, "Why? Why? Why? And if you aren't asking yourself why, why aren't you?
The answer is right there in the graphs and queries run. The first set of tests were not using an index. In the second set and several others that I tried as well that used an index, the singletons were the better performers.
The Bottom Line
It boils down to this. If any of the predicates (the stuff in the WHERE clause) are leading index columns, use the singletons. If none of the predicates are the first column of an index for that table, use the correlated query. Under no circumstances should the COUNT(*) ever be used, nor should you use the non-correlated.
And Yes, It Still Depends
Now when borrowing code, we have to know what is going on - because the right answer is still, "it depends."
To find what table columns are indexed in a database, run the following query:
SELECT CREATOR ,IX.TBNAME ,IX.NAME AS IXNAME
,COLSEQ ,CO.NAME AS COLNAME ,COLTYPE ,LENGTH
,ORDERING ,UNIQUERULE ,IX.CLUSTERING
,CLUSTERED ,COLCARD
FROM SYSIBM.SYSKEYS KY
,SYSIBM.SYSINDEXES IX
,SYSIBM.SYSCOLUMNS CO
WHERE CREATOR = &DB
AND IXCREATOR = CREATOR
AND IXNAME = IX.NAME
AND CO.TBCREATOR = CREATOR
AND IX.TBNAME = CO.TBNAME
AND CO.NAME = KY.COLNAME
ORDER BY IX.TBNAME, IX.NAME ,COLSEQ
If a predicate is an index column, use the following example for coding the singleton select.
EXEC SQL SELECT 1 INTO :WS-COUNT FROM. WHERE … END-EXEC IF SQLCODE EQUAL ROW-FOUND DISPLAY 'SQLCODE = ROW FOUND' ELSE IF SQLCODE EQUAL ROW-NOT-FOUND DISPLAY 'SQLCODE = ROW NOT FOUND' ELSE IF SQLCODE EQUAL MULTI-ROWS DISPLAY 'SQLCODE = MULTIPLE ROWS FOUND' ELSE DISPLAY 'PGM T88TST - PG 3000 -' ' - BAD STUFF IS HAPPENING WITH THE SQLCODE ' DISPLAY 'SQLCODE ' SQLCODE DISPLAY 'SQLERRMC ' SQLERRMC MOVE Y TO TIME-TO-QUIT-FLAG GO TO 3000-EXIT .
The singleton does kick out an SQL Error code -811 when duplicates occur - the way it performs (SELECT 1), it only expects one row to be returned. Sometimes its nice to know if there are duplicates.
If none of the predicates are indexed, use the following example for coding the correlated select.
EXEC SQL SELECT 1 INTO :WS-COUNT FROM SYSIBM.SYSDUMMY1 A WHERE EXISTS (SELECT 1 FROM. B WHERE … AND A.IBMREQD = A.IBMREQD ) END-EXEC IF SQLCODE EQUAL ROW-FOUND DISPLAY 'SQLCODE = ROW FOUND' ELSE IF SQLCODE EQUAL ROW-NOT-FOUND DISPLAY 'SQLCODE = ROW NOT FOUND' ELSE DISPLAY 'PGM T88TST - PG 3000 -' ' - BAD STUFF IS HAPPENING WITH THE SQLCODE ' DISPLAY 'SQLCODE ' SQLCODE DISPLAY 'SQLERRMC ' SQLERRMC MOVE Y TO TIME-TO-QUIT-FLAG GO TO 3000-EXIT .
--
Randy Custard is a database administrator for the State of Texas Comptroller of Public Accounts. As well as working with a great group of friends, he makes a mean cup of coffee, likes to listen to Alison Krauss and Union Station, thinks the Dallas Morning News has the best Sports section, and is a Scoutmaster in Round Rock.
Contributors : Randy Custard
Last modified 2005-04-12 06:21 AM