
Data Warehouse Performance Options
There are many options available to help you improve the performance of your data warehouse, and knowing all the different aspects of performance, issues, and considerations for building your data warehouse can be a tremendous task. DB2 offers many performance enhancements missing from other DBMSs that can make a huge difference. This article will highlight the performance advantages of DB2 and how to handle all the design issues, alternatives, and considerations experienced while building a large high-performance data warehouse.
We will explore how to build your data warehouse for maximum SQL access performance while maintaining the key values for partitioning and parallelism considerations. We will also evaluate OLAP tool performance features, connectivity issues to the Internet, and we will discuss considerations necessary for accommodating large numbers of concurrent users. This article will expose you to many design options and design alternatives to help you to achieve maximum performance from your data warehouse.
Considering Extract, Transformation, Load and Data Maintenance
The first consideration in designing a data warehouse is the extract, transformation, load (ETL) and data maintenance processes. Parallelism must be designed into the data warehouse to reduce the time windows for ETL, maintenance, and end-user access. Parallel processing should be considered and weighed against each design alternative to ensure that the best overall design is achieved.
Many corporations only focus on the data that they gather internally and not on information that is available for purchase from outside vendors. This can be a major mistake, since information your business needs or would gain extra value from may only exist externally. You should always take outside data into consideration when designing a database, then, keeping in mind the issues of data standardization and conversion overhead.
Any data brought into the data warehouse should be as clean, consistent, and carefree as possible. Data transformations processes are very expensive for processing large amounts of data daily or weekly for building very large databases (VLDBs). Cleansing or transformation processes must consistently follow business rules and keep in context across multiple, diverse source systems. Data consistency and standard domains and ranges are vital for developing clear and usable data that can easily be understood for business decisions points.
Different types of business decision points and business intelligence analysis provide different insights from the warehouse data. The input data used and its analysis should be reflective of the type of decisions and the overall mission statement your company has developed for the data warehouse.
As you evaluate the different source systems available as input, you should develop comparison criteria to determine how much standardization and transformation each source requires. The amount of processing can quickly add up, so make sure to do the extra processing calculations. And make sure to include all the various SQL validation and dimensional key translation work .
Data Structures and Partitioning
Common data warehouse designs detail the fact and dimension objects. Designing the index keys and minimizing the size, number, and dependencies between the objects can be critical to overall performance.
Zip Code = 60515 |
Figure 1: Split key partitioning.
Split key partitioning
One of the ways to partition DB2 database tablespaces in the z/OS environment is to split data into two columns, each being a partial key and partitioning it off the split data (refer to figure 1). (This can also be done on the DB2 Linux UNIX and Windows platform via multiple tables and a global view, but to explore that technique would require another article.) You can use partial index keys to group data together or split data across the database. Partial keys are defined by splitting a column into two columns; but you must conduct this redefinition carefully to ensure end-user access or transformation process performance does not suffer. By splitting the data along the separated column values, it can be grouped to a particular machine, partition, or department. This method can also be effective for segregating the data to different physical devices that can provide an extra performance factor during backups or recovery scenarios.
You can randomly generate keys from a formula or algorithm for partitioning, a very effective means of randomizing the data across the database. Using the second column as the data partitioning determining location factor, the data might be able to be spread across 100 segments of the database. Random numbers and data placement based from the data key would be evenly spread out across the database.
Client Id = 96808755 |
Figure 2: Result key partitioning.
Result key partitioning
Another way to partition a database is by using result keys (refer to figure 2). Sometimes a key is developed from a formula or business practice that uses a derived key. This can be done for a variety of reasons such as security, new business practices, or for randomizing the key values.
Hashing keys are usually a secondary key, calculated and used for a particular purpose. A simple remainder formula or a complicated calculation can be embedded in a source system that is needed in the warehouse. Documenting this type of key is very important because a transformation process may need the formula to make new key values.
This key type is good for evenly distributing the data across a range of partitions or machines. The difficulty is that the end user can rarely use this type of key for querying the database because of the calculations. Therefore, using this type of index should be researched and justified carefully.
Region Code = 01 |
Figure 3: Composite key partitioning.
Composite key partitioning
Composite keys are much more common then partial keys (refer to figure 3). Composite keys are built from many different columns to make the entire key unique or to include numerous columns in the index structure. For example, a product department may not uniquely identify an item, but if details about the SKU number, color, and size columns are added, this will uniquely identify that item. The combination of all the columns gives a greater value to the index key.
During dimension definition, it is sometimes best to minimize the number of objects. If the dimensions keys have common domains, it is sometimes convenient to combine the entities and combine their index keys. Combining objects can greatly enhance performance by eliminating the extra I/Os going to the extra table; however, before combining objects, make sure all relationships and integrity are maintained.
Configuration rules or index structures are sometimes used to separate information across the DASD configuration, the physical nodes, or the database partitions. Based on a key or a rule, the data is stored in a particular allocation of DASD. Separating the data makes it easier to reorganize, maintain, backup, or recover in the event of a hardware failure. Data separation rules, in particular, are very important because of the potential to evenly distribute the data. Distributing the data allows multiple entry points into the data based on the rules or keys that separate the data.
In some DBMSs, limit keys defined in an index structure provide the mechanism for separating the data across partitions or nodes. These limit keys can be customized to reflect the data value distributions to provide an even distribution. The distribution can be controlled via a single column value or multiple column values.
Eliminating and minimizing I/Os can make or break performance objectives, so creating a prototype database design and estimating typical queries is an important task. And, SQL Traces on the system during the user testing can help point out what tables are most popular or which ones might become bottleneck or system issues.
When designing a database, determine how many partitions or nodes to include depends on a variety of factors. The physical CPU configuration and the I/O hardware can be a big performance factor; by matching the hardware to the database design, you can determine how many partitions and parallel processing streams your CPU, I/O and network can support.
Alternative Table Types
By utilizing DB2’s Materialize Query Tables (MQTs) and creating summary tables that total departments or product lines (also called horizontal aggregation) you can greatly enhance end-user-access performance by limiting the amount of data accessed to get the answer.
You should also consider tracking query activity, since this can sometimes point to special data requirements or queries that happen on a frequent basis. These queries may be totaling particular products or regions that could be developed and optimized through an MQTs or horizontal aggregate.
Designers must analyze how much an MQT is utilized to justify its definition; like all aggregates, MQTs and horizontal aggregates that are well utilized can eliminate I/Os and conserve CPU resources. MQTs and horizontal aggregates work from a particular dimension key that is can be easily separated from the rest of the data.
You can also create specialized tables by using Global Temporary Tables (GTTs), although you need to ensure that the GTTs information is included in all end-user tool information so it can be evaluated and possibly utilized for end user query result sets. GTTs can also be used to limit the data accessed and can provide extra security against departments looking at other department’s data. All in all, the GTTs or horizontal aggregate security technique is very effective and also maximizes query performance.
Another method of speeding analysis is through the use of table views as aggregate data stores that specialize in a limited dimensional data. These views are good for taking complicated join predicates and stabilizing the access path for end-users. Data warehouse data can also be summarized into views to provide standard comparisons for standard accounting periods or management reports.
The aggregate function works best when defined to existing end-user comparison points (e.g., a department, product code, or time data). These aggregates can be used extensively for functions and formulas because of their totaled data.
It is important to understand that documentation and meta-data about aggregates must be well published and completely understood by all end-users and their tools. Tools should be aggregate-aware and able to include the different, appropriate aggregates in their optimization costing and end-user processing. These data aggregates can save a tremendous amount of I/Os and CPU, but be sure that the aggregates and summaries are monitored to demonstrate and justify their creation.
SQL-OLAP Features
The SQL OLAP functions performed inside DB2 provide answers much more efficiently then manipulating the data in a program. Like join activities and other data manipulation that DB2 can do directly, the SQL OLAP functions can greatly reduce overall I/O and CPU utilization. These OLAP functions are particularly good for getting the top number of data rows that match a criterion.
OLAP RANK Function (refer to example 1)
The OLAP RANK function can be used to order and prioritize your data according to your specific criteria. RANK orders your SQL query data by your criteria and assigns successive sequential numbers to the rows returned. The SQL query ranked rows can be individual data rows or groups of data rows.

Example 1: Rank.
OLAP DENSERANK Function (refer to example 2)
The OLAP DENSE_RANK function can also be used to order and prioritize your data according to your specific criteria. DENSE_RANK orders your data and assigns successive sequential numbers based on the OVER PARTITION data values found. DENSE_RANK differs from RANK because common values or ties are assigned the same number.
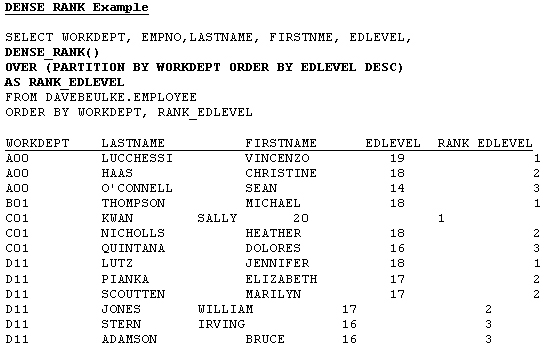
Example 2: Dense rank.
OLAP ROW NUMBER Function (refer to example 3)
The OLAP ROW NUMBER function can be used to assign row numbers to the retrieved data. Because ROW NUMBER assigns successive sequential numbers to the returned SQL query data the end-user, associated tool or application program can to make decisions for further processing.

Example 3: Row number.
Conclusion
Success, ROI, and performance are all determined by the end-user getting their questions answered. The common preliminary questions for sales-based data warehouse applications that must be answered are:
- How much product did we sell last (year, month, or time period)?
- How do these sales figures compare to last (year, month, or AP)?
- How much profit did we make on sales during this period?
- Who did we sell our products to?
- What categories or classifications separate our customers?
- What products were sold to which customer classifications?
- What was the response rate on the marketing promotion?
- What percentage of our customers are new?
There are many more considerations that effect data warehouse system performance. But taking advantage of the tips and techniques discussed within the ETL processes, parallelism, partitioning, and OLAP functions can greatly improve overall performance.
--
David Beulke is an internationally recognized DB2 consultant, author and lecturer. He is known for his extensive expertise in database performance, data warehouses and internet applications. He is member of IBM DB2 Gold Consultant program and currently President of the International DB2 Users Group (IDUG). He is a certified DBA for z/OS, Linux, Unix, and Windows platforms, a certified Business Intelligence Solutions Expert, an IBM Gold Consultant, and the past president of IDUG. You can reach him at Pragmatic Solutions Inc., 703-798-3283 or DBeulke@compuserve.com.
Contributors : David Beulke
Last modified 2005-04-12 06:21 AM