
You Can Be a DB2 Recovery Expert
First presented at IDUG 2002 - North America, May 2002
Introduction
Of course, an hour is not enough to become an expert in even so narrow a specialty as DB2 for z/OS Recovery. But this presentation should give you a chance to begin your journey if you are a novice. Common myths are exposed and dissected, and you are given a guide for becoming an expert. The experts among you can test your knowledge and may find ways to explain the facts to your colleagues.
Things that are basic to DB2 for z/OS backup and recovery are often the subject of myth and misunderstanding. The basics are carefully reviewed with an eye to avoiding these myths. Restart and recovery logs are essential to this topic and we explore what your logs are telling you. Experts know things about copies and logs that you may not and these things are outlined. We wrap up your training with a discussion of how experts classify and solve problems.
The Basics
| Basic Tools |
|
RECOVER uses the history of events contained in the SYSCOPY and SYSLGRNX tables. (SYSCOPY is part of the catalog and SYLGRNX is part of the directory.) SYSCOPY records everything that may impact RECOVER, not just copies. RECOVER automatically accesses image copies recorded in SYSCOPY and dynamically allocates them, adjusts for events recorded there, and automatically accesses log records in the subsystem log(s). REBUILD extracts key values from a table and rebuilds an index. Starting in V6, indexes were allowed to have image copies. RECOVER was no longer used to rebuild indexes, and the REBUILD syntax had to be used in the IBM utility for this purpose. DB2 introduced the COPY YES option for indexes. This does not preclude doing a REBUILD.
Certain exceptional situations allow RECOVER to work without a COPY for table spaces (index spaces must either have a copy or be rebuilt since CREATE, LOAD and REORG don't log sufficient information to recover them):
- If a table space is loaded (REPLACE) or reorged with LOG YES, the space can be recovered from the log starting at that point. All the log records must be available since the LOAD REPLACE or REORG.
- If a table space was created and then had normal INSERT, UPDATE and DELETE activity, it can be recovered entirely from the log. All the log records must be available since the create.
------------------------------
| Image Copy |
|
Image copies are made with utilities, primarily COPY but also with other utilities (for example, LOAD and REORG). They are recorded in SYSCOPY, a DB2 catalog table. They contain logical pages from the space. There are also utilities to make new copies from multiple incrementals or a full and subsequent incrementals and functions to combine copies and logs to make a more up-to-date copy. For example, IBM’s MERGECOPY combines copies to create a new copy and DB2 Change Accumulation Tool uses copies and logs to create a new copy. Other vendors have similar solutions in different tools. One image copy (a separate sequential file) is for a data set, partition or the entire space. The most you can put in one image copy is one space (all partitions or data sets). You cannot have one sequential data set for all the spaces in a database, for example, nor can you copy a single table from a table space with multiple tables.
SYSCOPY information is deleted when a space is DROPPED and older rows can be eliminated by running the MODIFY utility.
There are a few examples of copies that are not simple sequential data sets. Some utilities support hardware-assisted backups and record them for a special restore at RECOVER time. An example of this is IBM COPY CONCURRENT COPY using the features of certain IBM disk devices.
------------------------------
| Pop Quiz - Copying Tables |
|
Question:
Can you copy a table for RECOVER? Answer: NO! |
Placing more than one table in a table space is a backup and recovery decision as well as a performance and convenience decision. Image copies, loading and recovery have to be coordinated when tables share a space.
------------------------------
| Image Copy Types |
|

IBM RECOVER uses the backup copy if the primary copy is unavailable. LOCAL or RECOVERY copy is selected based on the SITETYP ZPARM or can be overridden with a LOCALSITE or RECOVERYSITE option on the RECOVER. Other vendors may allow different syntax for selection from these identical copies. Multiple identical copies are usually made simultaneously during the COPY process. However, there are utilities that make and register additional copies later by copying the copy.
The syntax for making a full or incremental copy is the FULL YES/NO option. FULL NO (incremental) may take less time to produce and may take up less space in the sequential data set. Some utilities allow selection of the type to be made by the utility.
Incrementals must be used with a previous FULL copy. If an incremental can’t be used, the log after the last usable copy is used. Therefore you may not wish to make backups of incrementals. Incremental copies are more efficient if the table space has the TRACKMOD YES option set. This option causes an area in the space maps to be maintained that shows the pages updated since the last full or incremental copy. This option will cause updates to the space maps and logging of these updates. If no incremental copies are planned, it is more efficient during updating to have TRACKMOD NO.
You cannot make incremental copies of index spaces with IBM COPY. Incremental copies are a way to limit the log processed by RECOVER without having to make a full copy but they require a more complex RECOVER (additional input files for every space) and, if indexes are being copied and updated (e.g. INSERTs are occurring) then the incrementals may not substantially reduce RECOVER time if they are made for table spaces because much of the log may be read for the index recovery.
------------------------------
| Copy Consistency |
|
SHRLEVEL CHANGE copies are a great idea and work well. A QUIESCE point after a set of SHRLEVEL CHANGE copies can create a common reference point for point-in-time recovery of a set of related spaces. In fact, a QUIESCE after a set of SHRLEVEL REFERENCE copies is also a great idea because it allows far simpler RECOVER syntax.
RECOVER TABLESPACE A.A
TABLESPACE A.B
TABLESPACE A.C
TOLOGPOINT X’000028A182F2’
-- or --
RECOVER LIST DBA TOLOGPOINT X’000028A182F2’
instead of
RECOVER TABLESPACE A.A TOCOPY A.A.FC.MONDAY
RECOVER TABLESPACE A.B TOCOPY A.B.FC.MONDAY
RECOVER TABLESPACE A.C TOCOPY A.C.FC.MONDAY
------------------------------
| Log Record Basics |
|
Log records contain internal DB2 column formats, possibly compressed and, for updates, may only contain changed columns. They are primarily designed to be used with an appropriate page image to repeat or undo a change.
Log records identify the space they update by the internal DBID and PSID. Tables are identified by OBIDs that may be found in some log records. Log records specify the physical page updated. If the change is for a particular row, the ID of that row on the page identifies it. Each row on a page is located by a map at the end of the page giving offsets.
Log point information is not retained in the space for each row, only for each page. If you have a table space with only one row per page (due to size or the MAXROWS option), you can locate the last log record that updated a row because of the value on its page.
The log point in the page is called PGLOGRBA.
Many log records also contain ‘undo’ data. This information is used to handle ROLLBACK. Log tools count on this information for some of their functions. For example, this data shows the contents of deleted rows.
------------------------------
| Log Points |
|
An RBA is a string of 12 hexadecimal characters. An LRSN is also a string of 12 hexadecimal characters. RBAs were the original log points, representing a byte count from the beginning of logging on a subsystem. With the introduction of data sharing, byte counts on logs could no longer serve to coordinate pages and log records because there are separate logs for each data sharing member. Thus, IBM introduced the concept of log record sequence number (LRSN). This term is really meant to be generic. If data sharing is not being used, then RBAs are LRSNs. If data sharing is being used, a time-based value is used as the LRSN. It is based on the values returned by STCK (store clock), but it is only twelve hexadecimal digits instead of a double word. In an LRSN the 31st bit is incremented every 1.048576 seconds. The beginning of 2002 is about X’B6F82BC8xxxx’ and this value increases about X’000141D8xxxx’ a day, about X’D69xxxx’ an hour and X’39xxxx’ a minute. If you are a younger person than I, you may be interested to know that this value will be FFFFFFFFFFFF0000 on September 17th, 2042 17.53.24.370480 U.S. Central Standard Time. In data sharing, RBAs are used to locate areas of specific member logs but all coordination uses the time-based LRSN. In non-data sharing, you may refer to the RBA as a log point or LRSN and, to add some confusion, log records have a time-based value in non-data sharing in the position of LRSN in a log record and DSN1LOGP outputs label it LRSN. It’s really just a time-based value like an LRSN in data sharing. But it can never be used to refer to a log point!
------------------------------
| SHRLEVEL CHANGE Copies |
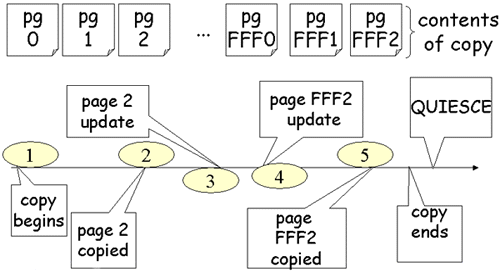 |
Every expert should be confident that SHRLEVEL CHANGE copies work and why.
A SHRLEVEL CHANGE copy is registered (in SYSCOPY) at a log point such that any updates before the log point are guaranteed to be on the copy. There is no registration of the log point of the end of the copy. The COPY utilities guarantee that every log record before the registration point is reflected in the pages on the copy, however, updates made during the copy may or may not be on the copy. In this case, Page 2 is copied without the update that occurred during the copy process. Page FFF2 is copied after the update that occurred during the copy process and contains it.
There is a log point that is on every logical page in the table space and that remains on the copied pages. This value is called PGLOGRBA in the Diagnosis Guide. It is a log record sequence number (LRSN) and it is the LRSN of the log record that was last applied to the page. The log point of every log record is compared to the log point in the page before the update is applied during RECOVER. If the page log point is greater than or equal to the log record’s LRSN then the log record is already reflected on the page. The log point of page 2 on the copy will be less than the log point of the update shown. The update is applied. The log point in page FFF2 is equal to the log point of the update shown for it. A RECOVER utility does not attempt to apply that update. (If there were subsequent updates to this page the page log point could be greater than this log record.)
------------------------------
| Log Compatibility |
|
Log records in the subsystem log are not logical in the sense that they rely on the internal location of the information (internal space IDs, page numbers and an ID within a page). Even log records for index spaces are by page. This causes certain activities to make different ranges of log records incompatible. This means that RECOVER needs a new starting point. LOAD REPLACE and REORG can be run with LOG YES. These activities create a new starting point without a copy. (LOAD REPLACE with a DUMMY SYSREC and LOG YES is often used to conveniently reset a space.) A REBUILD of an index in COPY YES status makes RECOVER impossible until a new copy is made. (REBUILD sets an index space with COPY YES set into the advisory status ICOPY. You can also rebuild it again if necessary.)
If a database table space is accidentally dropped, not only can you not use a RECOVER in a normal way (because SYSCOPY entries and SYSLGRNX entries are lost when a table space is dropped) but you can not readily apply log even if you get a copy restored to your space. There are tools directed at this problem. Some may require preparation in advance.
------------------------------
| Log Roadblock |
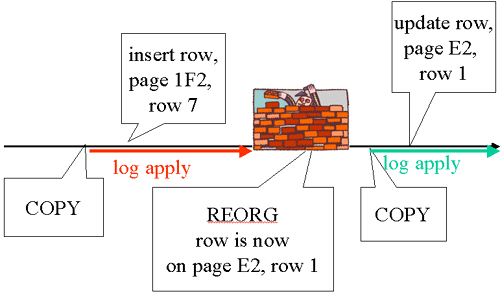 |
RECOVER cannot process with inconsistent log records. The log apply shown on the left can be done with its corresponding copy and the log apply shown on the right can be done with its corresponding copy, but they cannot be combined. All important events for the recovery of the spaces are in the SYSCOPY table. The events are identified by the ICTYPE column. That’s how RECOVER identifies this road block. If the COPY after the REORG isn’t usable, the older copy cannot be used to get to current.
SYSCOPY Columns
Column Description
----------- ----------------------------------------------------------
DBNAME Name of the database.
TSNAME Name of the target table space or index space.
DSNUM Data set number or partition number. A zero indicates all.
(continued)
------------------------------
| SYSCOPY Mining | ||
| Who? | What? | When? |
| DBNAME TSNAME DSNUM GROUP_MEMBER DSNAME JOBNAME AUTHID |
ICTYPE STYPE SHRLEVEL ICBACKUP PIT_RBA OTYPE ICTIME |
ICDATE TIMESTAMP START_RBA |
SYSCOPY Columns, cont.
Column Description
----------- ----------------------------------------------------------
ICTYPE Type of Operation:
A - ALTER
B - REBUILD INDEX (recorded for COPY YES index space)
D - CHECKDATA LOG(NO)
F - COPY FULL YES
I - COPY FULL NO
P - RECOVER TOCOPY or RECOVER TORBA or TOLOGPOINT; PIT_RBA
reflects the log point of the copy or log point specified.
Q - QUIESCE
R - LOAD REPLACE LOG(YES)
S - LOAD REPLACE LOG(NO)
T - TERM UTILITY COMMAND (Terminated Utility)
W - REORG LOG(NO)
X - REORG LOG(YES)
Y - LOAD RESUME LOG(NO)
Z - LOAD RESUME LOG(YES)
ICDATE YYMMDD
START_RBA This is really an LRSN and orders the events in time.
…
DSNAME Copy data set name if ICTYPE is ‘F’ or ‘I’. If ICTYPE is ‘P’ and
the RECOVER was TOCOPY, contains the copy data set name used for
TOCOPY. Otherwise, dbname.spacename if created after V4.
------------------------------
| Pop Quiz - Avoid Copies? |
|
Can you keep all logs and never make copies? NO! Not if REORG or LOAD are used with LOG NO. |
(SYSCOPY TABLE continued)
Column Description
----------- ----------------------------------------------------------
ICTIME HHMMSS
SHRLEVEL C - entry is a copy and was SHRLEVEL CHANGE
R - entry is a copy and was SHRLEVEL REFERENCE
blank - not a copy
…
TIMESTAMP Same value as represented in ICDATE, ICTIME, IBM recommends using
this one.
ICBACKUP When multiple copies are made, represents which one the entry is for.
blank - LOCALSITE primary copy
LB - LOCALSITE backup copy
RP - RECOVERYSITE primary copy
RB - RECOVERYSITE backup copy
…
STYPE Additional information about the event. For example, on a QUIESCE
row (ICTYPE = ‘Q’) a ‘W’ in this column indicates QUIESCE
WRITE(YES). For partial recovery (ICTYPE = ‘P’) an ‘L’ indicates
LOGONLY.
PIT_RBA An LRSN that is the log point of a TOLOGPOINT or TORBA recovery or
the log point of a copy used in TOCOPY.
------------------------------
| RECOVER Flavors |
|
The RECOVER utility can seem to have a daunting set of options but at its simplest it restores full copies merged with incrementals (if any) and applies logs from the point of the last copy. The copies are registered with log points (LRSNs). If TOCOPY is not specified, logs are applied from the log point of the last copy used. We’ve already seen why SHRLEVEL CHANGE copies work with log records.
When logs are applied, all log records for the space in the subsystem log(s) after the copy’s LRSN are applied with two exceptions.
You can request that RECOVER stop at a particular log record. This is usually done to get back to a point in time when the space wasn’t logically corrupted. This is done with the TOLOGPOINT option. It is entirely up to the user to pick a TOLOGPOINT that is reasonable (usually corresponding to a QUIESCE entry).
When you do a TOCOPY or TOLOGPOINT RECOVER and later, before you have done another COPY, you do another RECOVER (either to current or to another point after you executed the first RECOVER), RECOVER skips the group of log records eliminated by the first recovery. (This is shown in the following illustrations.)
It is possible to execute a RECOVER … TOLOGPOINT operation using the (undamaged) space and processing the log backward to the TOLOGPOINT, avoiding image copies. IBM’s RECOVER does not have this function.
------------------------------
| RECOVER Example |
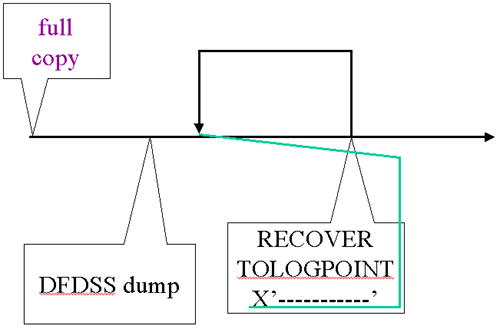 |
This is an example of the events for a space: a full image copy, a DFDSS dump taken when DB2 was stopped and a RECOVER …TOLOGPOINT. This is used in the following slides’ illustrations. We return to this set of events for each example and do a different recovery.
The full image copy and the RECOVER … TOLOGPOINT are recorded in SYSCOPY. The entry for the RECOVER has a START_RBA consistent with the log point at the time the RECOVER was executed but it has another log point (LRSN) in the column PIT_RBA that is the value given for TOLOGPOINT in the RECOVER.
------------------------------
| RECOVER … LOGONLY |
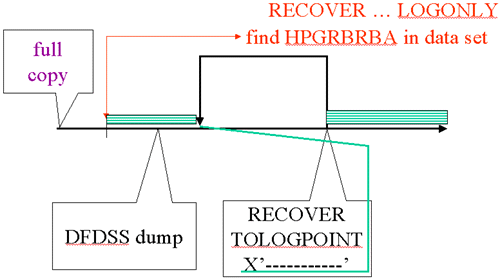 |
The LOGONLY option looks in the data set header page for the HPGRBRBA (recovery base RBA value). The DFDSS dump is restored before the RECOVER execution and this log point will be consistent with a time less than or equal to the pack dump time. Efforts have been made to update HPGRBRBA more often in recent releases and, if the space was closed or DB2 down when the dump was taken, the selection caused by SYSLGRNX entries will avoid processing some log. (We will discuss this a bit more in a moment.) This is the starting point for the log apply. HPGRBRBA is really an LRSN in data sharing.
Log records are skipped (even though there are SYSLGRNX entries for them) if a RECOVER … TOLOGPOINT has been executed before as in this example. Since this RECOVER did not specify a TOLOGPOINT, it uses all the log records found until the end of the logs, using SYSLGRNX as a guide but skipping the area between PIT_RBA and START_RBA on the RECOVER SYSCOPY entry for the prior RECOVER.
Note: A RECOVER, even with a TOLOGPOINT option, sets HPGRBRBA to the current log point for the subsystem or data sharing group. A RECOVER with LOGONLY cannot be used after a TOLOGPOINT recovery to adjust a space to a more current point.
------------------------------
| RECOVER TOLOGPOI |
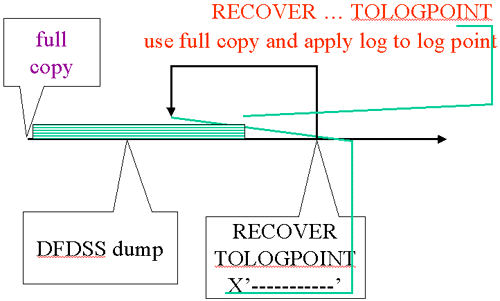 |
In this example, we had the same starting situation (full copy, dump, prior RECOVER). We use a LOGPOINT that is lower than the START_RBA for the prior RECOVER and don’t specify LOGONLY. RECOVER finds the image copy using the information in SYSCOPY (including the START_RBA of the image copy which tells us where to start applying log records). The image copy pages are restored and log applied.
In this case log records are used that were skipped in the first RECOVER executed. That is because the log point selected is before the START_RBA of the first recover and after the PIT_RBA.
------------------------------
| RECOVER Skips Range |
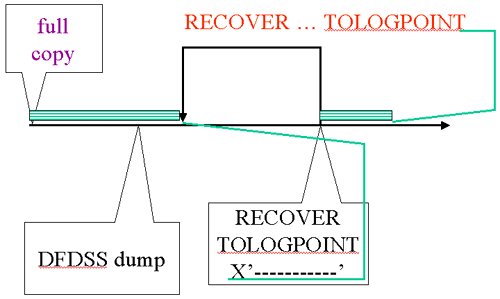 |
Again, we assume the same starting situation (full copy, dump, prior RECOVER). Once again, LOGONLY is not specified so the full copy is located and used. Log apply stops at the point specified. Notice that in this case the point is after to the point where the previous RECOVER ran (the TOLOGPOINT is greater than that RECOVER’s START_RBA). That RECOVER is acknowledged by skipping log records. Note that this is reasonable because the log records in the second area were against a version of the data that didn’t include that part of the log.
The Log
| Logs are a Shared Resource |
|
When spaces share a subsystem (or DB2 data sharing member) for update, they share log data sets.
There is one set of log data sets per DB2 member. When using RECOVER for one space, log records may be read and bypassed that are system records or log records for other spaces. Since each data sharing member has its own logs, a strategy of updating applications on different members would isolate those applications for log use.
DB2’s RECOVER utility merges the logs from different subsystems during recovery. If they are on tape, this may require one drive per data sharing member during recovery.
------------------------------
| Index Logging |
|
If your logs are filling fast, there are many possible explanations. Of course, the size and rate of changes are primary factors. In addition, index changes, frequency of check points on the system and DATA CAPTURE CHANGES tables can all cause additional logging. (Controlling log size could be the subject of an entire presentation! Submit an abstract for next year and get your conference registration for free if it’s accepted.)
Since logs are a shared resource, it is important for the recovery expert to know that the amount of logging may affect the I/O to the log for a given set of spaces during the RECOVER process.
------------------------------
| Identifying Relevant Log |
|
The log ranges in the SYSLGRNX table help control the log read for any given space, but ranges can be open for long periods. Ranges are kept for index spaces only if they are currently defined COPY YES.
The active log data set parameters ROSWITCH CHKPTS and ROSWITCH TIME (DSNZPARM values PCLOSEN and PCLOSET) are responsible for controlling when log ranges are terminated if a space or partition becomes inactive. PCLOSEN is a number of checkpoints since a space was last updated and PCLOSET is an amount of time since a space was last updated. The end value in a SYSLGRNX row will reflect the last time the space was updated so infrequently updated spaces will have fairly discrete log ranges. However, frequently updated spaces may have quite long ranges extending over many logs because the space must become inactive to get a log range closed.
LRSN (log record sequence number) values in the SYSLGRNX rows coordinate the logs from different members of a data sharing group. They are relative byte addresses if a system is non-data sharing.
------------------------------
Copy Expert
| Image Copies |
|
Experts know that even if RECOVER can’t use an image copy, it still may be useful. Running REPORT RECOVERY and preserving the output is a good way to have information at hand when problems occur. The MODIFY utility removes SYSCOPY and SYSLGRNX entries. If image copy data sets are deleted by the operating system or become uncataloged, this information is not detected in SYSCOPY automatically. Nor does MODIFY automatically uncatalog or delete the data sets in rows removed from SYSCOPY.
Some UNLOAD utilities can run against image copies. If the data is appropriate and consistent, this can be a way to recapture table data. (The copy should be SHRLEVEL REFERENCE at least.) You can’t apply log records directly to this data if it’s reloaded into a table but log analysis utilities may also be able to provide logical inserts, updates and deletes from the log records.
DSN1PRNT can be used on image copies to discover internal ID information after a table or table space is dropped. (If the table space is dropped, you will need to find the copy based on naming conventions or outputs from COPY or REPORT RECOVERY jobs run previously. DROP eliminates SYSCOPY entries.) DSN1COPY can restore an image copy to a space and even change IDs and reset log points. It can also restore the data to a completely different space if all physical characteristics are the same including partitioning or segmented definition and size, compression, definition of table(s), and whether ALTER statements have been run.
------------------------------
| Outsider Copies |
|
Relying completely on data sets dumps is not a wise idea. Important data should be image copied on some schedule and image copies should be made after LOG NO activities, particularly REORG. (If LOAD REPLACE is executed, the LOAD file may be preserved to reload but saving and using this data requires a special process for that space and you will not be able to apply log to the reloaded space with RECOVER.)
A complete set of system data (logs, bootstrap data sets and all spaces including the catalog and directory) can be copied after a subsystem is taken down cleanly or while a SET LOG SUSPEND is active, using special fast hardware copies. These data sets can be restored and used to restart the entire subsystem at that point. Using SET LOG SUSPEND is the subject of past conference presentations. All the data is made consistent at RESTART in much the same fashion as after a power failure. Procedures have also been developed to attempt to use a restart with a more up-to-date logs and BSDS and to bring the system to a point further than the state of committed transactions at the time of the dumps. This involves using DEFER on all the spaces during restart and using LOGONLY recovery. There are a number of issues to manage.
If a space is copied outside of DB2 while DB2 is down or while the space is stopped, the copy can be restored and LOGONLY RECOVER used to apply log. If a single data set is copied outside DB2 while the space is active, you might be able to do the same but this is not recommended by IBM.
------------------------------
| Log Tools |
|
Recovery experts keep an eye on the logging activity on their DB2 subsystems and know how to analyze log records if necessary.
A systems programmer or DBA may control the DB2 logs. However, to be a recovery expert for applications, you must understand what is being done.
Experts also understand how to use the log as a resource for problem solving. Everyone has the free standalone utility, DSN1LOGP. Many shops have an extra-cost tool to read and interpret logs and not only report on them but, if desired, produce SQL.
------------------------------
| Print Log Map |
|
Note: The number of archive logs that can be recorded in the BSDS is subject to a limitation set in the installation but, in any case, no more than 1000 are allowed.
The following is a part of the output from a DSNJU004.
LTIME INDICATES LOCAL TIME, ALL OTHER TIMES ARE GMT.
DATA SHARING MODE IS ON
HIGHEST RBA WRITTEN 00097B660F8E 2002.029 23:51:57.8
HIGHEST RBA OFFLOADED 00097B150FFF
ACTIVE LOG COPY 1 DATA SETS START RBA/LRSN/TIME END RBA/LRSN/TIME DATE LTIME
DATA SET INFORMATION
-------------------- -------------------- -------- ----- -------------------
00097A071000 00097B150FFF 1995.150 13:36 DSN=DSNDBE.DBE2.LOGCOPY1.DS01
B71A19155E46 B71C66347141 PASSWORD=(NULL) STATUS=REUSABLE
2002.027 23:38:05.8 2002.029 19:33:46.8
00097B151000 00097C230FFF 2001.101 12:14
DSN=DSNDBE.DBE2.LOGCOPY1.DS02
B71C66347142 ............ PASSWORD=(NULL) STATUS=NOTREUSABLE
2002.029 19:33:46.8 ........ ..........
------------------------------
| Looking at Log Records |
|
DSN1LOGP is free when you buy DB2. It does have quite a few limitations but can be useful. Some parts of the log records are formatted and interpreted but some are not. Some items in the unformatted portion of the output can be interpreted by reviewing the DSNDQJ00 macro provided with DB2.
If you have a more sophisticated log processing tool available you should learn how to use it and do non-destructive testing with it.
------------------------------
| DSN1LOGP Stand-Alone Utility |
|
DSN1LOGP allows filtering on log points and IDs as in the following syntax.
STARTRBA(000049273000)
ENDRBA(00004A32BFFF)
DBID (0124)
OBID(0002)
From the IBM utility guide, a bit of advice, “You can also find a column named OBID in the SYSIBM.SYSTABLESPACE catalog table. That column actually contains the OBID of a file descriptor; don't confuse this with the PSID, which is the information you must include when you execute DSN1LOGP.”
SELECT A.DBNAME, B.TSNAME,
HEX(A.DBID) AS DBID, HEX(A.PSID) AS PSID,
HEX(B.OBID) AS OBID, B.NAME AS TABLE
FROM SYSIBM.SYSTABLESPACE A, SYSIBM.SYSTABLES B
WHERE A.DBNAME = B.DBNAME AND A.NAME = B.TSNAME AND
B.DBNAME = 'LSBDB';
---------+---------+---------+---------+---------+-------
DBNAME TSNAME DBID PSID OBID TABLE
---------+---------+---------+---------+---------+-------
LSBDB LSBTS01 0124 0002 0007 DEMO_INVENTORY
LSBDB LSBTS02 0124 0004 000A DEMO_SUPPLIERS
LSBDB LSBTS03 0124 0006 000D DEMO_VENDOR_PARTS
| Spaces not in SYSCOPY |
|
The SYSCOPY entries for these spaces can still be found with REPORT RECOVERY and can be printed from the log with DSN1LOGP and the SYSCOPY option.
------------------------------
| Spaces Absent in SYSLGRNX |
|
Some catalog and directory spaces don’t have SYSLGRNX entries
|
SYSUTILX has to be recovered first and independently so that other RECOVERs can have information about utilities executing on spaces and so they can be terminated if necessary. The copy of SYSUTILX is recorded in the log and it has no log ranges. SYSUTILX must be recovered independently and it must examine every log record after the copy looking for updates.
------------------------------
| Order of Recovery |
|
The independent steps necessary and the absence of SYSLGRNX entries for some spaces make catalog and directory copies a high priority. When recoveries of application spaces are necessary, any catalog and directory spaces that must be recovered come first. Since everything has to be recovered in a disaster scenario, many users use a tool to help organize the disaster recovery scenario that involves careful ordering of a number of steps. This order is documented for each release of DB2.
------------------------------
Problems
| Problem Categories |
|
When recovery must be performed, there are three general possibilities. One is a hardware failure that has affected the DB2 data on disk. As RAID features protect more and more data from the head crashes of the past (by mirroring or parity recovery schemes), disk failure is less likely to cause a problem in DB2. However, the disk enclosure and connections may fail in such a way that any data in the enclosure is potentially compromised. There is more hardware and software in the enclosure that might fail than ever before and the exposure in a failure may be many more bytes.
A second possibility is that the programs and transactions acting on the data have done something wrong. This is called a logical or application failure. The DB2 subsystem generally appears to be operating normally.
The third possibility for a recovery is that a disaster has effectively destroyed the primary data center.
There are other specialized failures such as losing a log or BSDS (boot strap data set) or DB2 system failure causing data corruption. The BSDS should be duplicated and separated (different disk device). In a failure one is copied to the other. DB2 corrupting the data may require any number of actions depending on what happened.
------------------------------
| Media Failure |
|
With a storage failure, there are three steps:
- Find out what DB2 objects are affected. (What objects you maintain are on the volume or storage unit.)
- Identify unaffected data sets if it is a RAID unit failure. If the unit compromised data through a catastrophic cache failure, for example, spaces that have not been updated recently may not be affected.
- Prepare a RECOVER or REBUILD for every object affected to get them back to the exact desired state (often called ‘current’). If there are indexes to be rebuilt, make sure the REBUILD is executed after the RECOVER.
Note that application spaces are not single points of failure as long as multiple copies are made and dual logs are maintained. The log supports bringing copies to current. DB2 subsystems containing important data should use dual logs, actives and archives. The two copies of active logs and the two copies of the BSDS (boot strap data set) should be on separate packs or RAID units. If this rule is not followed and there is a problem with the storage containing logs or BSDS, data loss may occur and a conditional restart of the system followed by recovery of all spaces to a prior time may be required.
------------------------------
| Pop Quiz - Index Recovery |
|
If a table space is recovered must indexes be rebuilt (or recovered)? NO! Recovery to current (for a media failure) would not require it . Some objects are being recovered to overcome media failure. Related objects should still be consistent if they were unaffected by the media failure. |
It is only necessary to use RECOVER or REBUILD or some other technique for the spaces that are damaged or missing as long as TOLOGPOINT (or TOCOPY) is not used in recovering any objects. Normally you wouldn’t use these options when a media failure had occurred.
------------------------------
| Logical Failure |
|
If DB2 thinks everything is fine, but the users don’t think so...then you have a logical problem! On rare occasions the DB2 subsystem might compromise the data because of a software error. For example, there have been failures to externalize changed pages, failures to properly issue locks, etc. There is also a nasty sub-class of user error when a DBA or other authorized person drops an object such as a table, table space or database. These problems aren’t discussed here in detail. Usually, you are looking for a bad or duplicate batch job, a bad transaction or a user who has done something wrong.
------------------------------
| Finding a Corruption Point |
|
Look for a place where everyone agrees data wasn’t corrupted. Get as close to now as possible!
|
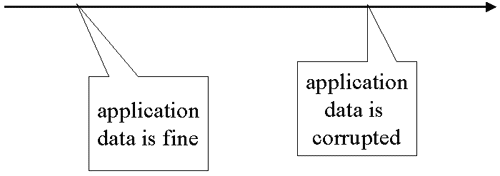
With data corruption, you need to find a prior time when the data was valid. This may be quite subtle. Just because no users noticed a problem between opening of business and 10AM, doesn’t mean everything was fine at the beginning of the day. If the source of the corruption is not known, the symptoms may be revealing. For example, if users are complaining that a group of customers seem to have duplicate order items and orders are grouped and processed at night, it is reasonable to assume that a duplicate batch job was run last night. If users are complaining about missing data, transactions or jobs that do deletes might be examined.
DSN1LOGP and more sophisticated log tools can be invaluable in researching such problems. Searching for log data on recent logs for the table spaces in question can reveal the problem. If using DSN1LOGP, you need to find a log range representing the time frame you need and run SQL to obtain the relevant IDs for the table spaces. The more sophisticated tools may allow time input, table names, column comparisons, etc. They may also collect the transaction information at the same time. DSN1LOGP may require multiple passes to get the relevant data changes and then search for the URID in them to find a transaction header (which will have some unformatted data you may recognize as Job name or authorization ID). DSN1LOGP cannot be run on the active logs on non-data sharing systems while DB2 is active.
------------------------------
| Consistency Point |
|
If RECOVER must be used, a point of consistency across affected table spaces must be located and any good updates after that point will be lost.
|
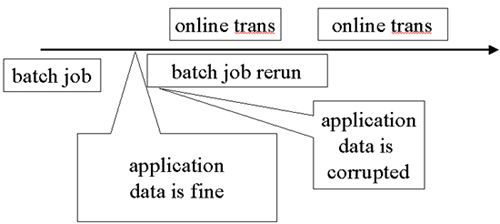
In the case shown here we have discovered a batch job that was rerun creating the problem. The corruption begins a bit earlier than when it was discovered, shortly after the start of that job. Other work was going on for the same application tables in online transactions. It might have been independent of the batch job but some or all of it might have depended on the values and rows corrupted by the batch job. This is an application question.
One possibility is to go back to the time after the first batch job using a point-in-time recovery (RECOVER with TOLOGPOINT on all the table spaces and COPY YES indexes and a rebuild for other indexes). It looks like from this diagram that nothing was happening for the spaces involved in our application prior to the batch job rerun. In a real situation, however, we have to discover this point. If we had a QUIESCE after every batch job, we can find the QUIESCE in the SYSCOPY table for our spaces.
------------------------------
| Looking for Mr. QUIESCE |
|
|

The first SQL statement shown on this slide shows all QUIESCE entries after a certain date for the spaces in some databases. The second gives the maximum QUIESCE point for for those data bases. The third determines if one of the spaces does not have an entry at the maximum QUIESCE point. These statements could be adapted to various situations. Caution should be taken if partitioned table spaces are quiesced by PART. This is not recommended.
------------------------------
| Using a SQL Approach |
|
If the result of the batch job was undone with SQL then the online transactions might be preserved and it would not be necessary to find a point of consistency for RECOVER.
|
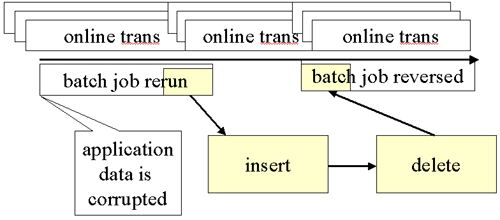
The picture has been altered here to push the bad batch job to the left and show a (possibly more realistic) situation where online transactions are constantly running and overlapping.
SQL that reverses everything done by the batch job provides several advantages.
The SQL corrections could also run with other transactions.
All the online transactions shown could still be reflected in the data.
It would not be necessary to find a point of consistency.
SQL to reverse the changes can be obtained by using a tool capable of creating UNDO SQL. (At least three vendors have one.) You could also write your own SQL. You could do this manually or using an application log and a planned procedure for processing it. It’s quite difficult to use the log as a source of manual data. For example, the log may contain incomplete updates; the log is in internal DB2 format; the log doesn’t include the key qualifiers nor column and table names; and the log data may be compressed. SQL reversing the changes must update the records with old data for updates, insert deleted rows; and delete inserted rows. To execute correctly when rows were affected multiple times, these inserts, updates and deletes should be in the reverse order from the original SQL. Cascading deletes or updates need to be accounted for as well.
------------------------------
| Caveats for a SQL Approach |
|

Using SQL to undo corruption can have some striking advantages. However, there are also some difficulties. In the illustration, transactions change customer addresses using an old tape, regressing many customers’ addresses. Then good transactions switch the salesmen assigned to customers based on zip code. Some of these transactions are incorrect because of the bad addresses. If we reverse the address changes, the salesmen assigned might still be wrong. It might be necessary to locate customer data that had the address changes and also had salesmen changes. Some tools can show these rows in a report.
Here is another example of depending on incorrect data in later transactions.
A corrupt transaction inserts rows for new customers using an incorrect credit evaluation. Some of the customers place orders and are given a confirmation on a credit plan based on the credit evaluation in the customer row. The order application requires the customer row and it’s already there so one is not inserted.
If new customer rows are deleted, the order rows are orphaned. If the new customer rows are not deleted, they all have incorrect credit evaluations.
If many rows were inserted and few orders subsequently placed by those customers, one approach is to reverse the inserts with the incorrect credit calculation except for those where the customers made orders. Some tools can create a report to help you locate those rows.
------------------------------
| Caveats for a SQL Approach |
|

Columns that are updated by corrupt transactions and subsequently updated by good transactions with proper values may be incorrect if they are reversed based on the log records for the corrupt transaction.
Many employee rows are updated by a corrupt transaction to zero a column that represents the 401K deduction percentage.
Good transactions change some of these rows to have a new and correct value for employees that had submitted changes. For example, Jane Doe had a percentage of 10% that was then erroneously zeroed out. Subsequently, a request was processed from Jane to set it to 5%. Other employees had similarly submitted new amounts.
If the log records for all the updates setting the values to zero are examined in isolation, Jane might have her percentage set to 10% again. So the good transaction for her request is effectively reversed.
Some products can produce reports to point out these anomalies or have techniques to help avoid them.
In this case, using point-in-time recovery on the application spaces to a point before the bad transaction and then ‘replaying’ the good transactions would work. Some products can create REDO SQL for this purpose.
Columns that are accumulated can cause complex problems as in this example.
A corrupt transaction adds one to a column that counts the number of requests that a customer will be charged for in accessing a legal database. The column initially held a value of 110 so after the corrupt transaction it is 111.
Subsequently a good transaction adds two to the column making it 113.
The column value should be the original number in the column (before the corrupt transaction) plus two or 112.
If the update by the corrupt transaction is reversed in isolation and the original value returned, the value will be 110. For this reason, doing a traditional point-in-time recovery in cases like this and then rerunning the application to process the increments may be better practice.
Some tools may be able to locate rows that have this type of anomaly, allowing a manual update for them and reversal for others.
------------------------------
| Caveats for a SQL Approach |
|
If users may be reinserting accidentally deleted data as in the first bullet point, a log tool that bypasses -803 errors is useful. This would allow users to insert the rows needed to do their work before the deleted data was all re-inserted and still have the correction process continue for other rows. (This assumes a unique constraint or index on the rows.)
Tools can help but you must know your data. If you are not the application specialist you must engage the specialist to help avoid compounding logical errors. It is always worth noting that there is not a one-to-one correspondence between log records and SQL statements. So both DSN1LOGP and other log tools might show thousands of individual deletes or updates for a DELETE or UPDATE statement that qualifies many rows. There is one log record for every row as we have seen in discussing the organization of the log.
------------------------------
| Disaster Recovery |
|
The DB2 recovery expert may have a plan for every bit of the DB2 data. But he should know if it is dependent on a tape management system, the operating system components, the ICF catalog, DFSMS and other resources recovered by other teams. Beyond that, every category of DB2 resource must have a plan consistent with the backups being shipped. The plan must include the BSDS and logs as well as the libraries for DB2. The catalog and directory requires special consideration.
It is important to have disaster recovery tests and to prove the plans. Testing recoveries is one of the more difficult activities you will undertake.
------------------------------
| Disaster Recovery Planning |
|
Lowering the time to get back up increases the cost. Lowering data loss in the event of a disaster increases the cost.
If the use of mirroring for disaster recovery is contemplated, then you should study the hardware vendor’s capabilities. It is necessary to prevent what is described as a rolling disaster where separate volumes or units fail over time and cause the DB2 data sets at the remote site to be inconsistent with the expected configuration after a failure. Many vendors have a consistency group concept to handle this issue and it may require that you be certain that all the DASD DB2 is using is defined in such a group.
Also be aware of different states of your data. What will you do if you are in the middle of a REORG, LOAD or recovery at the production site when a disaster occurs? You must be able to clean up these activities at the remote site which may require image copies or load data or application logs to be mirrored along with the data itself. Care must also be taken in testing the disaster recovery plan with mirroring. Is your plan at risk for data loss during the test?
------------------------------
| Pop Quiz - Mirroring |
|
If I mirror the BSDS, logs, catalog, directory and all my spaces, is that enough? NO, maybe not. If you are doing REORGs, then image copies must be made and mirrored to recover if a REORG is in progress when a disaster occurs. |
When a REORG is in progress, a RECOVER will be needed at the disaster site. The easiest way to accommodate this is to make image copies and mirror them as well. Theoretically online REORG would be OK if you mirrored the shadow data sets as well as the primary ones. The online REORG could be restarted if it failed during rename and terminated if it failed before. Care should also be taken with LOAD operations. It might be wise to mirror the input to the LOAD so that it could be restarted or a prior image copy to RECOVER the data as it was before the LOAD began. If a RECOVER is done for a space at the production site, it will compromise the space while it’s running. So one better have the resources to recover it at the recovery site as well.
------------------------------
Expert Summary
| Expert Summary |
|
--
Linda Ball is the DB2 Corporate Architect in OS/390 Product Development at BMC Software, Inc. Linda has many years of experience with DB2 UDB for OS/390 and other relational data bases. She provided technical leadership on several backup and recovery and log analysis products for BMC.
Contributors : Linda Ball
Last modified 2005-04-12 06:21 AM