
What’s New in DB2® Universal Database™ Version 8.1.2: Part 1, SQL Enhancements
The IBM® DB2 Universal Database (DB2 UDB) family of products has a long tradition of delivering innovation and key technology in a timely fashion to the marketplace. Customers who invest in the DB2 UDB engine can count on the fact that they will receive features throughout the version life cycle that make it easier to use, more resilient, and more powerful.
This is the first in a series of articles that covers the new features delivered to the DB2 UDB environment via Fix Pack 1 and the DB2 UDB V8.1.2 update. This series will group enhancements in four key categories: SQL, Administration, Application Development, and Miscellaneous. This particular article focuses on SQL enhancements.
What’s in a Name?
In the past, maintenance and new features have been delivered throughout a version release via Fix Packs. Fix Packs were release quarterly (roughly) and could contain any number of maintenance fixes or features. In DB2 UDB V8.1, a new nomenclature and approach to interim maintenance and feature delivery has been implemented.
To help identify feature-oriented ship vehicles from fix-oriented vehicles, vehicles that deliver mainly maintenance and fixes to a DB2 UDB installation are still referred to as Fix Packs (FPs). Those that deliver new features are called updates and change the Modification Level of the DB2 UDB code from a naming perspective (more on this in a bit).
Fix Packs and updates are planned for delivery in an "every-other" fashion. Applying Fix Pack 1 to a DB2 UDB V8.1 installation would yield DB2 UDB V8.2 + Fix Pack 1. Applying the DB2 UDB V8.1.2 update (what would have formerly been known as Fix Pack 2) to DB2 UDB V8.1 would yield DB2 UDB V8.1.2.
All shipped vehicles are cumulative in nature. Therefore, applying Fix Pack 3 would also include the 8.1.2 update and Fix Pack 1. The numbering convention, from a naming perspective, will follow such that both the modification level and the Fix Pack are part of the sequence number. For example, Fix Pack 1 is followed by 8.1.2, followed by Fix Pack 3, followed by 8.1.4, etc. This is shown in the diagram below.
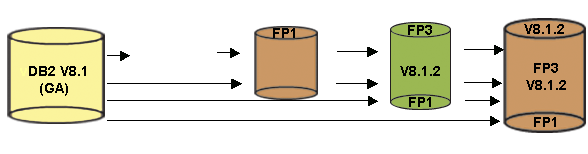
You can download Fix Packs and updates from the DB2 UDB Technical Support site at: www.ibm.com/cgi-bin/db2www/data/db2/udb/winos2unix/support/index.d2w/report. (We have detailed the naming conventions in this section so that you can better understand IBM communications about DB2 UDB. Some Web sites may still use the old nomenclature.)
This new naming convention is the first step in identifying the difference between feature-based and maintenance-based downloads.
In certain scenarios, from a path perspective, applying a Fix Pack will also change the modification level of a release. For example, applying Fix Pack 1 to a DB2 UDB V8.1 installation would update the Microsoft Windows registry as follows:
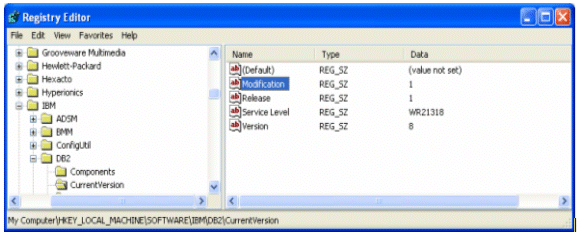
So, in this case there is a modification change by applying Fix Pack 1. Again, this is from a naming perspective. Applying Fix Pack 1 would show results (for example) in the Windows registry as 8.1.1, but is still referred to as Fix Pack 1.
Merge SQL
A common database design is one that has a master table containing the existing or current knowledge of a domain (for example, a PARTS or ACCOUNTS table) and a table that details transactions (for example, a SHIPMENT or TRADES table) containing a set of changes to be applied to the master table. This transaction table can contain updates to objects existing in the master table and/or new objects that should be inserted into the master table. To apply the changes from the transaction table to the master table requires two separate operations, an UPDATE operation for those rows already existing in the master table and an INSERT operation for those rows that do not exist in the master table. It may even be the case that the business process requires a DELETE.
MERGE-type operations are very useful in data warehousing and client/server-oriented applications that request row sets from the database and allow users to modify data through a provided GUI, and then store the data back to the database. A combined UPDATE, DELETE, and INSERT operation would allow a user to change or add new rows from a GUI and then the underlying application could easily harden these changes in the database.
DB2 UDB V8.1.2 introduces support for the SQL-standard MERGE statement that will combine conditional UPDATE, DELETE, and INSERT operations on a target table or updatable view. These operations are performed using results from a table reference in a single statement.
Additional search conditions can be added in the WHEN clause to have finer granularity for matching; this allows different UPDATEs, DELETEs, or INSERTs to be performed depending on the statement’s sub-condition. Users can also specify a signal statement to be returned if an error condition in the WHEN clause is detected. Any row that does not satisfy any WHEN clause is ignored.
One of the most common types of data maintenance applications written today involves the merging of data from a set of new transactions into an existing table. Some applications also include logic that would delete records from an existing table that are not found in the transaction table. Rather than write an application in a conventional programming language, the SQL language includes the MERGE statement that mimics this functionality in a single SQL statement.
A simple example will illustrate the power of the MERGE statement. Consider a retail store where a list of products, their description, and quantity are kept in a single table. The definition of this table is:
CREATE TABLE PRODUCTS
(
PROD_NO INT NOT NULL,
DESCRIPTION VARCHAR(20),
QUANTITY INT NOT NULL
);
INSERT INTO PRODUCTS VALUES
(1,'Pants',10),(2,'Shorts',5),(3,'Shirts',20),(4,'Socks',12),(5,'Ties',5)
Every morning, stock is delivered to the store and a transaction table is created that includes all of the new merchandise that has been delivered to the store. This transaction table is identical to the PRODUCTS table. The SQL language has a simple way of creating a table based on an existing table definition:
CREATE TABLE PRODUCT_TXS LIKE PRODUCTS
The following MERGE command will take the contents of the PRODUCTS_TXS table and merge it with the existing PRODUCTS table:
MERGE INTO PRODUCTS PR
USING (SELECT PROD_NO, DESCRIPTION, QUANTITY FROM PRODUCT_TRANSACTIONS) TXS
ON (PR.PROD_NO = TXS.PROD_NO)
WHEN MATCHED THEN
UPDATE SET PR.QUANTITY = PR.QUANTITY + TXS.QUANTITY
WHEN NOT MATCHED THEN
INSERT (PROD_NO, DESCRIPTION, QUANTITY)
VALUES (TXS.PROD_NO, TXS.DESCRIPTION, TXS.QUANTITY);
The original table contains the following rows:
| PRODUCT Table Contents | ||
| PROD_NO | DESCRIPTION | QUANTITY |
| 1 | Pants | 10 |
| 2 | Shorts | 5 |
| 3 | Shirts | 20 |
| 4 | Socks | 12 |
| 5 | Ties | 5 |
In addition, the PRODUCT_TXS (transaction) table contains the following data:
| PRODUCT Table Contents | ||
| PROD_NO | DESCRIPTION | QUANTITY |
| 1 | Pants | 15 |
| 3 | Shirts | 30 |
| 6 | Shoes | 5 |
| 7 | Belts | 10 |
After the MERGE command has run, the PRODUCT table will contain the following rows:
| PRODUCT Table Contents | ||
| PROD_NO | DESCRIPTION | QUANTITY |
| 1 | Pants | 25 |
| 2 | Shorts | 5 |
| 3 | Shirts | 50 |
| 4 | Socks | 12 |
| 5 | Ties | 5 |
| 6 | Shoes | 5 |
| 7 | Belts | 10 |
The number of pants and shirts available has increased by the quantity found in the transaction table, while two new entries have been added for shoes and belts.
Query Sampling
Today’s databases (especially data warehouses) are growing so large, and their query workloads are becoming so complex, that it often becomes impractical and perhaps even unnecessary from a business perspective to access all of the data relevant to a query. Take, for example, an analyst that may be strategically leveraging the data warehouse for trend or exception analysis to drive new marketing programs.
In order to validate a hypothesis, it may be acceptable to arrive at a conclusion based on a sample of the data and results that lie within some acceptable error range. If this approach were acceptable, a random sample of the database would greatly increase query performance. For the most part, the amount by which the database is reduced with sampling, would lead to the same ratio in terms of performance benefits. If a database were to sample 20 percent of the records, it would be assumed that the performance increase in the query should be at around 80 percent.
DB2 UDB V8.1.2 adds the ability to do efficient sampling of data for SQL queries in the engine. Sampling is supported in DB2 UDB V8.1.2 with the new TABLESAMPLE clause, which is added to the FROM clause of the SQL statement. The TABLESAMPLE clause includes the approximate percentage of that table to sample, called the sampling percentage or sampling rate. For example, if the sampling rate is set to 0.1, then only 1/10 of a one percent of data will be sampled. This would mean that in a 10,000-row table, only 10 rows would be accessed – this may or may not be appropriate for your business.
Sampling in DB2 UDB V8.1.2 has ISO standards compliance and uses the Mersenne Twister algorithm for random number generation, as well as Bernoulli sampling.
Empirical results have demonstrated that the accuracy of aggregate values (e.g., counts, sums, averages,) computed over a large base of sampled data is typically very good, even with low sampling rates (e.g., one percent or less when tables are large enough).
The most common application of query sampling is for aggregate queries such as AVG, SUM, and COUNT, where reasonably accurate answers of the aggregates can be obtained from a sample of the data. Sampling can also be used to obtain a random subset of the actual rows for auditing purposes.
In general, we recommended that the TABLESAMPLE clause be added to only one table in the query, typically the fact table in a star schema. When specifying more than one TABLESAMPLE clause for multiple tables, results could have questionable meanings.
The following SQL statement illustrates the use of the TABLESAMPLE clause; it retrieves the average value of sales by each store from the transactions table by sampling only 10 percent of the data:
SELECT STORE, AVG(SALES) FROM TRANSACTIONS TABLESAMPLE BERNOULLI(10) REPEATABLE(5)
GROUP BY STORE
The TABLESAMPLE clause includes either the BERNOULLI or SYSTEM specification. BERNOULLI sampling examines every row to determine whether or not it is included in the answer set, while SYSTEM sampling does the sampling on a page-by-page basis. While SYSTEM sampling will be generally faster, it may result in skewed results if your calculations are based on a column that is also used for clustering the table, or for multi-dimensional organization of the data. In this case, BERNOULLI sampling may be more appropriate.
The REPEATABLE clause is used to generate identical answer sets on subsequent runs of the SQL statement. The value within the brackets is used to seed the random number generator that is used as part of the sampling process. A user may want to use the REPEATABLE clause during the testing of the SQL data to generate consistent result sets.
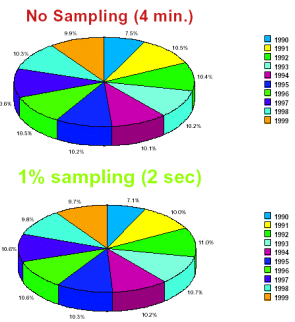
The time to execute the previous query is an order of magnitude faster than running it against the entire answer set. The following chart illustrates the results returned from a query run against the entire database, and then using one percent sampling.
If the TABLESAMPLE clause is used with the COUNT or SUM function, the results will need to be scaled to produce the correct result. For instance, a SUM function using 20 percent sampling will only return a SUM based on 20 percent of the total number of rows. In order to show the correct result, the SUM must be divided by .2 (20/100) to produce a result that reflects 100 percent of the records. In general, any COUNT or SUM function must be divided by the sampling value (represented as a decimal number).
In addition to doing quick computations against a database, the TABLESAMPLE clause can also be used for SQL development and for generating test data. For developers needing to test their SQL data against large tables, the TABLESAMPLE allows them to quickly test their logic without having to scan entire tables. In addition, temporary test tables can be produced that reflect an accurate subset (or demographics) of the data. The following SQL statement will populate a table with five percent of the original table:
INSERT INTO TEMP_TRANSACTIONS
SELECT * FROM TRANSACTIONS TABLESAMPLE BERNOULLI(5);
While the TABLESAMPLE feature can be very useful for quick analysis, SQL development, and testing, users should remember that these results reflect sampling of values and not the entire table!
List Partitions Table Feature
In a partitioned environment, database partition information is stored in the db2nodes.cfg file, which resides on the DB2 UDB catalog partition. In DB2 UDB V8.1, there is no other way than to open the file to read its contents, or fetch the information via the Control Center.
DB2 UDB V8.1.2 introduces the new db_partitions() table function, defined in the SYSPROC schema, to return the information stored in the db2nodes.cfg file. The result table will take the form:
Partition_Number SMALLINT, Host_Name VARCHAR(128), Port_NUMBER SMALLINT, Switch_Name
VARCHAR(128)
In order to invoke this function in an SQL call, a database object and a connection must exist.
This function will not work on DB2 UDB Workgroup Server Unlitmited Edition, DB2 UDB Workgroup Server Edition, DB2 UDB Personal Edition, or DB2 UDB Express Edition servers since those servers do not have a db2nodes.cfg file.
Identity and Sequence Support in a Partitioned Database Environment
Identity and Sequence objects were implemented in the Version 7 release to facilitate the migration process for new DB2 UDB customers from other databases that used this feature (for example, Sybase). In DB2 UDB V7.x, these features were only supported on DB2 EE and child editions (DB2 UDB WE, DB2 UDB PE).
DB2 UDB V8.1.2 extends the support for these objects such that they are supported in a partitioned database environment (DB2 UDB ESE with the database partitioning option).
In a partitioned environment, each node maintains a local cache (with a default size of 20, unless otherwise specified by the user) from which identity or sequence values are assigned. If this cache becomes empty, it is refilled from a central location on the catalog node. Therefore, the rest of the nodes will need to generate remote requests to refill their caches (unless the cache is being refilled on the catalog node, in which case, a local request is made). This could cause a minor performance delay, depending how often the cache needs to be repopulated.
Remote requests for cache refills can be minimized by using a larger cache size. However, take into account that this approach will increase the average dispersion of generated values (assigned on different database nodes), as well as the potential number of (identity/sequence) values, which could be lost in the event of a database shutdown. For example, assigning values 1-50 versus 1-20 in a cache increases the ‘gapping’ between partitions.
Many applications require the use of sequence numbers to track invoice numbers, customer numbers, and other objects that get incremented by one whenever a new item is required. Identity columns are used directly in tables to generate new values, while sequence objects are available for use throughout the database.
The SEQUENCE object in DB2 lets the DBA or developer create a value that gets incremented under programmer control and can be used across many different tables. The following SQL statement would create a sample sequence number for customer numbers using the data type of integer:
CREATE SEQUENCE CUSTOMER_NO AS INTEGER
By default, this sequence number starts at one, and increments by one at a time, and is of an INTEGER data type. The application needs to get the next value in the sequence by using the NEXTVAL function. This function generates the next value for the sequence, which can then be used for subsequent SQL statements.
VALUES NEXTVAL FOR CUSTOMER_NO
Instead of generating the next number with the VALUES function, the programmer could have used this function within an INSERT statement. For instance, if the first column of the customer table contained the customer number, an INSERT statement could be written as follows.
INSERT INTO CUSTOMERS VALUE
(NEXTVAL FOR CUSTOMER_NO, 'ZIKOPOULOS CAR WASH AND SUSHI BAR', ...)
If the sequence number needs to be used for inserts into other tables, the PREVVAL function can be used to retrieve the previously generated value. For instance, if the customer number we just created needs to be used for a subsequent invoice record, the SQL statement would include the PREVVAL function.
INSERT INTO INVOICES
(34,PREVVAL FOR CUSTOMER_NO, 234.44, ...)
In addition to being simple to set up and create, the SEQUENCE object has a variety of additional options that allow the user more flexibility in generating the values:
- Use a different data type (SMALLINT, INTEGER, BIGINT, DECIMAL)
- Change starting values (START WITH)
- Change the sequence increment, including specifying increasing or decreasing values (INCREMENT BY)
- Set minimum and maximum values where the sequence would stop (MAXVALUE/MINVALUE)
- Allow wrapping of values so that sequences can start over again (CYCLE/NO CYCLE)
- Allow caching of sequences to minimize catalog contention (CACHE/NO CACHE)
Even after the sequence has been generated, the user can ALTER many of these values. For instance, the DBA may want to set a different starting value, depending on the day of the week.
Health Monitoring User Defined Functions (UDFs)
In DB2 UDB V8.1, administrators can access health snapshot data via DB2 C APIs and the command line processor. While this is useful, some high-level programming languages (such as SAP R/3 ABAP) cannot leverage these APIs directly. These languages can use SQL, however. Fix Pack 1 provides an SQL interface into this data via a UDF that is callable from the SQL API. This new feature is an extension of the GET HEALTH SNAPSHOT monitor data that was provided in DB2 V8.1 through the same facility. DB2 V8.1 with Fix Pack 1 introduces 12 new UDFs that can be used to retrieve health snapshot information for the DBM, DB, table spaces, and containers.
The implemented UDFs call the DB2 API db2GetSnapshot() that was made available in DB2 V8.1. This UDF can be used in a partitioned environment as well using the “partition” input parameter. The UDF will convert the self-defining data stream returned from the API into a virtual table for SQL manipulation.
For each tracked group (DBM, DB, table spaces, and containers) there are three categories of UDFs: INFO, HI (Health Indicator) and HI_HIS (Health Indicator HIStory). As a general rule of thumb:
- INFO captures the global information for the specific logical group (for example, the server instance name for DBM)
- HI UDF contains the latest health indicator information
- HI_HIS UDF contains the health indicator history information
The current list of supported calls is found in the following table:
| Function | Purpose |
HEALTH_DBM_INFO |
Returns information from a health snapshot of the DB2 database manager |
HEALTH_DBM_HI |
Returns health indicator information from a health snapshot of the DB2 database manager |
HEALTH_DBM_HI_HIS |
Returns health indicator history information from a health snapshot of the DB2 database manager |
HEALTH_DB_INFO |
Returns information from a health snapshot of a database |
HEALTH_DB_HI |
Returns health indicator information from a health snapshot of a database |
HEALTH_DB_HI_HIS |
Returns health indicator history information from a health snapshot of a database |
HEALTH_TBS_INFO |
Returns table space information from a health snapshot of a database |
HEALTH_TBS_HI |
Returns health indicator information for table spaces from a health snapshot of a database |
HEALTH_TBS_HI_HIS |
Returns health indicator history information for table spaces from a health snapshot of a database |
HEALTH_CONT_INFO |
Returns container information from a health snapshot of a database |
HEALTH_CONT_HI |
Returns health indicator information for containers from a health snapshot of a database |
HEALTH_CONT_HI_HIS |
Returns health indicator history information for containers from a health snapshot of a database |
The following SQL statement will retrieve health information about the status of the SAMPLE database:
SELECT SNAPSHOT_TIMESTAMP,
DB_NAME,
ROLLED_UP_ALERT_STATE_DETAILFROM TABLE(HEALTH_DB_INFO('SAMPLE',-2)) AS S;
SNAPSHOT_TIMESTAMP DB_NAME ROLLED_UP_ALERT_STATE_DETAIL
-------------------------- -------- ----------------------------
2003-04-24-14.31.35.488293 SAMPLE Normal
1 record(s) selected.
A DBA can use these Health Center snapshots to write scripts that check on the status of databases and send appropriate alerts or invoke corrective actions. This type of functionality is also available in the Health Center, but the ability to get information through SQL gives the user more flexibility in retrieving the information.
--
Paul C. Zikopoulos, BA, MBA, is an IDUG keynote and award-winning speaker with the IBM Global Sales Support team. He has more than seven years of experience with DB2 and has written numerous magazine articles and books about it. Paul has written articles on DB2 for many magazines and has co-authored the books: DB2 - The Complete Reference, DB2 Fundamentals Certification for Dummies, DB2 For Dummies, and A DBA's Guide to Databases on Linux. Paul is a DB2 Certified Advanced Technical Expert (DRDA and Cluster/EEE) and a DB2 Certified Solutions Expert (Business Intelligence and Database Administration). You can reach him at paulz_ibm@msn.com.
George Baklarz, B Math, M Sc (Comp Sci) is the manager of the DB2 Worldwide Pre-sales Support Group. He has more than 19 years of experience with DB2 and has co-authored the DB2 UDB Version 8.1 Database Administration Certification Guide (Prentice-Hall, 2003). In his spare time, he teaches database theory at the University of Guelph and presents at a variety of conferences, including the International DB2 Users Group. You can reach George when he's not traveling at baklarz@yahoo.com.
Trademarks
DB2, DB2 Universal Database, and IBM are trademarks or registered
trademarks of International Business Machines Corporation in the United
States, other countries, or both.
Copyright International Business Machines Corporation, 2003. All rights reserved.
Microsoft and Windows are registered trademarks of Microsoft Corporation in the United States, other countries, or both.
Other company, product and service names may be trademarks or service marks of others.
Contributors : Paul C. Zikopoulos, George Baklarz
Last modified 2005-12-16 06:57 PM