
Why DB2 Universal Database Version 8? - Part 2: A Look at Decision Support and Other Performance Enhancements
Part 1 | Part 2
In part 1 of this article, we detailed some of the many transactional performance enhancements that are part of the IBM® DB2® Universal Database™ (DB2) Version 8 release. In this article, we’ll continue this discussion with a focus on decision support and other enhancements. Additionally, when appropriate, we’ll highlight some new features coming in DB2 Version 8.2 (formerly known as DB2 “Stinger”).
Optimizer Enhancements
One major performance enhancement in Version 8 is the optimizer’s ability, by default, to use a hash join. Before Version 8, you had to enable the optimizer to consider the use of a hash join by using a registry variable that was not turned on by default.
Now, by default, the optimizer chooses from a rich set of join strategies, including nested loop, sort merge join (also called merge scan join), and hash join. Each of the supported join strategies has their advantages and disadvantages, and are automatically selected by DB2 based on the server’s configuration and the query workload.
A hash join is a powerful join strategy when there is a need to merge two data streams, but the order of the result is not valuable for subsequent query processing steps (in other words, no sorting of the data is required). DB2 has made hash joins more and more efficient and they have become a frequently chosen join method by the DB2 optimizer.
In addition to the default enablement of hash joins, Version 8 has substantially increased the flexibility of its outer join support in the optimizer, particularly for queries that mix inner and outer joins in the same query. These enhancements are completely transparent to users and applications, so all you have to do to leverage these new features is generate a new access plan.
The following chart shows an example of the benefits that a hash join can have on workload performance.
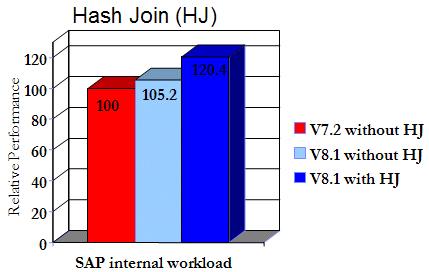
DB2 Version 7.2 is used in this example as a performance baseline for comparison and its value has been set to 100.
Hash joins can have a dramatic effect on performance because they allow for the quick determination of matching rows from two input streams (representing two tables), particularly in 64-bit environments where memory is plentiful. Hash joins don’t require that these input streams be ordered (as would be the case for a sort merge join). If the query workload is right, this join strategy can have a tremendous effect on performance as shown in the previous figure.
Multidimensional Clustering (MDC) Tables
DB2 Version 8 introduces a fresh, innovative, and unique approach to data access and storage with support for multidimensional clustering (MDC) tables. MDC provides flexible, continuous, and automatic clustering of data along multiple dimensions. This new feature can result in significant improvement in the performance of queries, as well as a significant reduction in the overhead associated with data management operations such as reorganization and index maintenance after insert, update, and delete operations.
MDC delivers the following benefits:
- Faster queries through access to only those data pages that contain the requested data, without erroneous searching, and with fewer disk accesses. This reduces demand for CPU and disk input/output (I/O), and makes these resources available to other applications.
- Reduced index size, which leads to disk savings and faster queries and operations.
- Virtual elimination of some maintenance operations, such as table reorganization for reclustering.
- Faster insert and delete operations.
As we mentioned, MDC enables a table to be physically organized along more than one dimension simultaneously (don’t confuse this with OLAP dimensions, although MDC tables are great for OLAP workloads, MDC dimensions refer to columns within the table); this is similar to having multiple clustered indexes on a single table, if it were possible to do so. In particular, an MDC table ensures that rows are organized on disk in blocks that contain contiguous pages, such that all rows within any block have the same predefined dimensional values. (In MDC terminology, a block is synonymous with a DB2 extent.)
All blocks contain the same number of pages, and multiple blocks can have the same dimension values if there are enough records having those dimension values to warrant it. Dimensions for an MDC table are specified when the table is created. Special block indexes are then automatically created for each dimension and when you have more than a single dimension, a composite block index is created for the entire set of dimensions. (You can learn more about MDC tables here.)
The following chart shows speedup factors for specific core database operations between MDC and traditional tables:
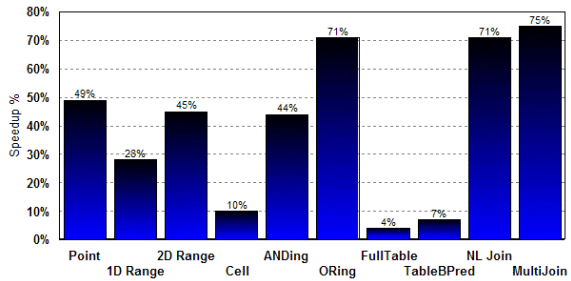
We have also seen a 30- to 90-percent improvement in some customer workloads. These improvements are a result of reduced I/O, more efficient data coverage, and block index look-ahead prefetching, which are all possible with MDC tables. The next chart shows a sample of an actual business intelligence workload and the performance boost that MDC tables were able to deliver to this customer.
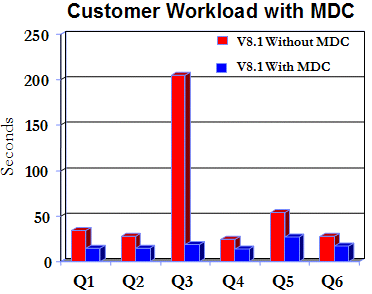
There are some considerations to keep in mind if you are thinking about implementing MDC tables. When thinking about implementing a table with MDC capabilities, one should consider both the number and the granularity of the dimensions, the additional work required to organize an MDC table during data load operations, and the additional overheard during data load operations if the dimensions need to be created at run-time.
In DB2 Version 8.2, we have enhanced the Design Advisor to include design guidance for MDC tables (including the selection of dimensions and their granularity) as part of the schema changes that the Design Advisor can recommend based on an input query workload.
Other Performance Enhancements
In this section, we’ll briefly discuss some additional performance enhancements that are available in DB2 Version 8. Specifically, we will cover:
- Replication
- Null and default value compression
- Declared global temporary tables
- Trace enhancements
- Control Center enhancements
- Operating system-specific enhancements
DataPropagator™ CAPTURE and APPLY Enhancements
There are a number of key improvements to the core CAPTURE and APPLY components that make this type of replication much faster in Version 8. For example, the CAPTURE program is multithreaded in Version 8 and can perform multiple captures in parallel. In addition, the work performed by the DataPropagator product in the staging area is more efficient with respect to how SQL operations are moved through this process because they require fewer joins and sorts.
The following figure illustrates the Version 8 performance enhancements to the CAPTURE and APPLY replication components:
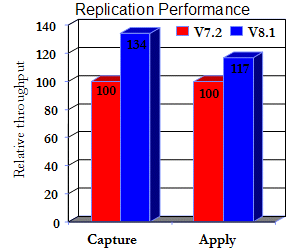
Once again, we use DB2 V7.2 as the baseline and set it to 100 percent of relative throughput. As you can see, both replication components have shown significant performance enhancements on the DB2 V8 platform.
The next release of DB2 Information Integrator (DB2 II), code named “Masala,” adds even more scalability and options to replication with the addition of a queue-based replication architecture built on IBM WebSphere® and MQSeries® technology.
NULL and Default Value Compression
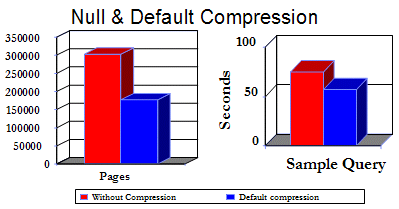
DB2 Version 8 introduced a new feature that can optionally compress NULLs and system default values. Compression in Version 8 has the potential for huge (>50 percent) space savings under the right circumstances.
Most people will think of this feature as a space saving one — and it is. However, there is a performance component to compression as well. For example, with compression, more data can fit into data pages because of a reduced data consumption rate. Using fewer data pages means a reduction in overall I/O loads for SELECTs, INSERTs, and so on. For an I/O-bound system, this can lead to significant performance improvements. Typically, a larger performance gain will result from compression in decimal columns.
The following chart shows the performance boost observed during a sample compression test case. In the following figure, you can see that the use of compression reduces both the total number of pages consumed and the total elapsed time for a query run.
Declared Global Temporary Tables (DGTTs)
DB2 Version 8 dramatically expands the usability of DGTTs by making them more like full-fledged table objects. There is now support for indexes, statistics, and the ability to roll back transactions against DGTTs.
With the existence of indexes and the corresponding index and table statistics, the query optimizer has much better information and a richer set of access methods (like RID-based fetches, and so on) from which to choose when selecting optimal query plans.
Trace Enhancements
DB2 Version 8 has a completely reworked the trace utility and the result is dramatically improved performance. The performance gains come from the implementation of reduced trace buffer synchronization. The following illustrates just how fast the trace utility is in Version 8.
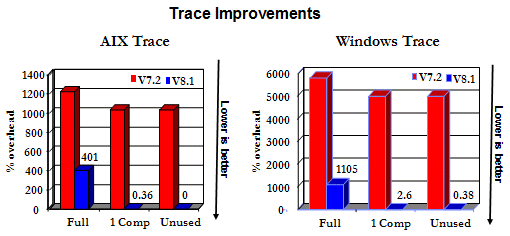
As you can see, regardless of whether all DB2 components are traced or just a single one, there are dramatic improvements in the performance of trace. Most importantly, if a highly selective trace mask is employed and the execution path doesn’t touch the code identified by the mask, then there is the greatest reduction in overhead. In other words, the overhead of trace is a function of how often you need to actually generate trace records.
Control Center Enhancements
The Control Center in DB2 Version 8 is noticeably faster than it was in Version 7. IBM Corp. added Support for JDK V1.3 and took advantage of its ability to multithread the JVM (new in Version 8).
In addition to this, a number of visual cues were added that let you know when a task has completed, and changed the isolation level from Cursor Stability to Uncommitted Read (where possible) to reduce database contention.
DB2 Version 8.2 will add a significant performance enhancement to this tooling with support for JDK V1.4 and some rework within the tooling itself, including a fast launch option on Windows.
Operating System-specific Enhancements
The bulk of the DB2 code is common. In fact, over 90 percent of the code is the same for each of the supported distributed platforms. The remaining 10 percent is optimized for the underlying operating system. For example, in a Windows environment, DB2 uses a threaded model instead of the process-based model used in the UNIX® and Linux® implementations; it fully exploits hyper-threading, which allows the operating system’s scheduler to schedule two threads against a single processor; it supports NTFS, and so on.
Some Operating System-specific Enhancements in DB2 Version 8
AIX
DB2 Version 8 exploits AIX 5.2 by taking advantage of large pages, pinned buffer pools, and ML03 (which delivers significant benefits for JFS2). Version 8 also leverages significant I/O exploitation, including support for direct, asynchronous, and concurrent I/O.
The Version 8 code uses the latest in compiler technology, including the use of profile-guided optimization to recognize core operations (such as fetching a row, updating a row, scanning a table, and so on) and to use this profile to identify which parts of the DB2 code are of key importance from a performance perspective. This information is used for code optimization, such as moving out infrequently used code so that it doesn’t “get in the way.”
There are more improvements coming in DB2 Version 8.2 including support for AIX 5.3, and the IBM eServer® POWER5® systems such as the p5-570, that are showcased in the leading performance TPC-C benchmark published for 16-way systems.
Solaris
DB2 continues to fully optimize for the Solaris operating system environment. For example, DB2 for Solaris Version 8 also takes advantage of asynchronous I/O, and uses the new Fort C++ Version 6.2 compiler, which delivers optimization and performance benefits.
HP-UX
There are significant changes to DB2 on HP-UX in the Version 8 release. DB2 is fully optimized for HP-UX 11i.
Before Version 8, DB2 was heavily constrained by the shared memory addressing space limitations on this platform. This has now been resolved with complete support for 64-bit environments. In addition, IBM has introduced a new set of DB2 for HP-UX binaries to run on the Intel® Itanium 2 chip set.
The DB2 for HP-UX Version 8 release uses a different compiler (Version 03.31) than what was used for DB2 Version 7. This has resulted in performance improvements of up to 25 percent in some circumstances. DB2 Version 8.2 will see even more scalability enhancements for DB2 on the HP-UX operating system in the area of large SMP concurrency.
Linux
DB2 Version 8 starts with a new kernel base (the minimum level for Version 8 is the 2.4.19 kernel). For enterprise-class deployments on Linux, Red Hat Enterprise Linux (RHEL) Version 3 U1, and SuSE Linux Enterprise Server (SLES) V8 SP3 are the distributions we recommend the most; this is where the majority of the DB2 V8 customers are, and where IBM has done a lot of work. Testing of DB2 has been successfully completed with the latest 2.6 Linux kernel on SLES9, and this platform has significant price performance benefits. At the time this article was written, DB2 had the world record for price/performance measured in the TPC-C benchmark on this platform.
DB2 Version 8 uses a new compiler (Intel Version 6) with profiling to deliver the same benefits as profiling does for DB2 for AIX. The code has also undergone a significant optimization effort for the Itanium 2 processor.
DB2 Version 8.2 will introduce a number of significant performance-enhancing techniques, including support for the 2.6 kernel, vector and asynchronous I/O, page pinning, large page support, as well as 64-bit support on all major server systems, including zSeries, iSeries, and pSeries.
Windows
DB2 Version 8 includes many enhancements to the Windows platform. From a performance perspective, the speed of the native DB2 OLE DB provider has been greatly increased (thanks to the Common Client, as noted in part 1 of this article), with greater functionality (for example, it fully supports loosely coupled transactions). Also, an ADO.Net provider is available in Version 8, and it too has undergone extensive performance enhancements.
DB2 for Windows also uses a new compiler that yields significant performance benefits for Intel-based workstations (refer to the Linux section).
Wrapping it Up
DB2 Version 8 is the fastest release of DB2 ever! Across platforms, across workloads, and with different hardware, you can expect good things from the latest version of DB2.
To help gauge the performance benefits that Version 8 could deliver in a business intelligence environment, we ran a number of different workloads on the different operating systems that DB2 Version 8 supports. The results in the chart below are from the generally available version of DB2 Version 8. We run this regression test bucket on each subsequent FixPak, and have seen a wide range of improvements (from modest to impressive) in the Version 8 maintenance stream.
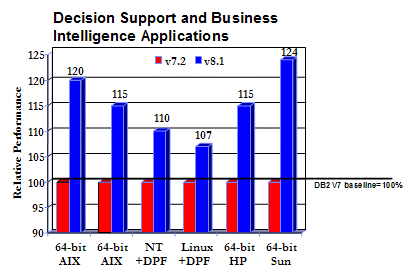
As you can see, the DB2 Version 8 release delivers a significant performance boost for decision support applications.
We hope that we’ve demonstrated just how significant an impact the DB2 Version 8 release can have on your environment. And, we just touched on the performance aspects in this series; there are many advances in autonomic computing, development integration, deployment, and so on that you can exploit in this release as well.
--
Berni Schiefer is a Distinguished Engineer and manager of the DB2 Universal Database Performance and Advanced Technology team. He has responsibility for the performance of DB2 across all platforms and all application areas. He joined IBM in 1985, and has worked on a wide range of database development projects – including SQL/DS™ and the Starburst experimental relational database at the IBM Almaden Research Laboratory – prior to working on DB2. His current focus is on introducing advanced technology into DB2, with particular emphasis on performance, self-tuning, self-administration and next generation I/O and communication fabrics.
Paul C. Zikopoulos, BA, MBA, is an award-winning writer and speaker with the IBM Database Global Sales Support team. He has more than ten years of experience with DB2, and has written numerous magazine articles and books about it. Paul has co-authored the books: DB2 Version 8: The Official Guide, DB2: The Complete Reference, DB2 Fundamentals Certification for Dummies, DB2 For Dummies, and A DBA's Guide to Databases on Linux. Paul is a DB2 Certified Advanced Technical Expert (DRDA and Cluster/EEE) and a DB2 Certified Solutions Expert (Business Intelligence and Database Administration). You can reach him at paulz_ibm@msn.com.
Trademarks and Disclaimers
The views expressed in this article are those of the authors and not necessarily those of IBM. Features referred to in the DB2 V8.2 release may or may not be present in its final availability. All benchmarks are internal tests and meant to represent the potential advantages that the new features outlined in this article could deliver – your mileage may vary.
AIX, DB2, DB2 Universal Database, eServer, IBM, MQSeries, POWER5, SQL/DS, VisualAge, and WebSphere are trademarks or registered trademarks of International Business Machines Corporation in the United States, other countries, or both.
Microsoft, Windows, and Windows NT are trademarks of Microsoft Corporation in the United States, other countries, or both.
Intel is a trademark of Intel Corporation in the United States, other countries, or both.
Linux is a trademark of Linus Torvalds in the United States, other countries, or both.
UNIX is a registered trademark of The Open Group in the United States and other countries.
Other company, product, and service names may be trademarks or service marks of others.
For further TPC-related information, please visit http://www.tpc.org/.
Contributors : Berni Schiefer, Paul C. Zikopoulos
Last modified 2006-01-04 04:38 PM