
Say “No” to Down Time: How to Improve Database Availability, and Be a Hero to your Client
The Challenge
Several years ago, a large Canadian financial institution built a large marketing data warehouse using DB2 UDB for Linux, UNIX, and Windows. The majority of new data being added to this warehouse is done through a large batch monthly process. Today, EDS Canada manages the data warehouse; however, EDS was not involved in the development of this process, as it pre-dates EDS’ engagement.
The main part of the data warehouse is divided between a staging database and the database supporting the bulk of the user population; let’s call it STAR. The STAR database is approximately 1.5 TB. This separation allows for the transformation work for the new month to be done in a separate database while the users can continue to access STAR. Prior to the implementation of the changes described in this article, the staging process took about four days and the STAR load took about 36 hours. To add the new monthly data to the STAR database as quickly as possible, DB2’s Load utility was used extensively. With Version 7 of DB2 UDB, this meant that the STAR database had to be offline during the load process. To minimize the amount of down time during prime hours, the STAR load process would wait for a weekend before starting.
EDS was under constant pressure from its client to make the new data available earlier in the month, and to reduce the amount of time that the warehouse was unavailable. As EDS had no control over when the new data is received from the operations area of the client, there were only three ways to make the new data available earlier:
- Reduce the time it takes to run the staging process
- Reduce or eliminate the wait time for the following weekend
- Reduce the time it takes to run the STAR loading process
For more than three years, additional disk space was being purchased within the context of enterprise storage solutions (in our case, EMC), which was intended to eventually replace the server-attached RAID arrays. All major vendors of these solutions offer some implementation of split-mirror technology, which simply means you can decide at any point in time to un-mirror previously mirrored devices and re-mirror them and allow the O/S to “see” these as separate devices. It was decided that downtime due to the monthly load could be greatly reduced, and the need to wait for the following weekend could be eliminated, if we could have two copies of the STAR database, quickly synchronize or split them, and transparently direct the users to the copy of our choice. To accomplish this, we use EMC’s Business Continuity Volumes (BCV), Timefinder technology, and functionality added to DB2 UDB in Version 7.2.
How to Use Business Continuity Volumes
BCVs are disk volumes that are paired with standard EMC Symmetrix devices, similar to a mirrored volume. What makes these disk volumes special is that they can be disconnected or split from the standard volume with which they are paired. Once the BCV is split from its paired standard disk, the BCV is then available as an independently host-addressable device that is a point in time copy of its paired standard device. These split BCVs can then be used for a number of different purposes.
Timefinder is the software component that is used to establish, track, and manage BCVs. The BCV can be in a number of states; the initial state is established, in which the BCV is paired with a standard device. Timefinder will then copy all of the data from the standard device to the BCV to create the standard device and BCV pair. While the BCV is paired with its standard device, it is not available for use by any host.
After the standard device and BCV pair has been established (i.e., the data is synchronized between them), the BCV can be split from the standard device and it is then accessible by a host for other work. An incremental establish is performed when a previously established standard device/BCV pair has been split and then reconnected together. During the incremental establish, Timefinder only copies the tracks from the standard device to the BCV that have changed since the last split. This helps to reduce the time required to establish the pair and get the data synchronized. To do this, Timefinder keeps a record of the tracks that have changed since the last split. Again, the BCV is not available during the incremental establishment. The splitting process is an instantaneous procedure that can make the BCV available very quickly.
The information on the BCV can also be copied back to the standard device after a split. This provides a means to restore the standard device from the BCV. Once again, the BCV would be unavailable to any host during this copy.
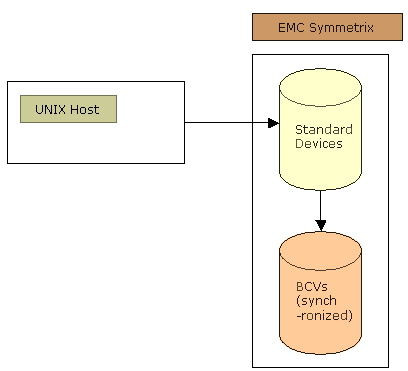
DB2 UDB Version 7.2 and BCVs
With respect to DB2, the BCVs can be used to quickly create a copy of a DB2 database. In our case, we use this database copy to allow the users to continue to access their data while the primary copy of the database is being loaded with new data.
DB2 Version 7.2 introduced a number of new features to help support the use of technology like EMC BCVs. During the splitting process described previously, it is important to make sure that there are no partial page writes on the source database. Although the database could be shut down as the split was performed, this would mean an outage for the data warehouse. DB2 UDB 7.2 introduced a new feature known as suspended I/O, which stops all write operations on the source database. The command for suspended I/O is, “DB2 set write suspend for database.” While the write operations have been suspended, the BCVs can be split from their standard device mate without causing problems for the new database. It must be noted that while the write suspend avoids partial page writes, it does not guarantee unit of work consistency. Of course, there is a Resume command to run after the BCV split has completed and it is, “DB2 set write resume for database.”
The next question is, what do you want to do with your newly created copy of the data? We use it to create a copy of our database that will be accessed by another instance. To do this, we split the BCVs, start our target instance, and then make the database usable using the “db2inidb dbname as snapshot” command. This command is run on our target instance and will bring the database into a consistent state by initiating crash recovery to resolve any inflight units of work. Our target instance is also on the same machine as our source instance, and in this case, we must change the directory path information for our containers. To do this, we use the relocate option of the db2inidb command. This option takes a config file that specifies the old and new paths for the logs and all of the containers. Once this is completed, our copied database is ready to accessed.
The BCV copy of the database can also be used as a warm standby database. In this instance, the target database is left in a rollforward pending state and logs from the source database are continually applied to the target database. If the target database is needed, the rollforward is completed and the database can then be accessed.
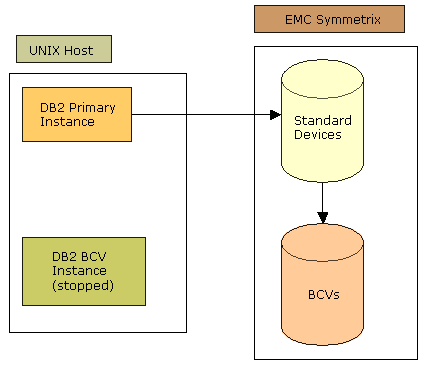
This diagram shows the standard devices synchronized to the BCVs. The primary instance accesses the standard devices. The BCV instance is stopped.
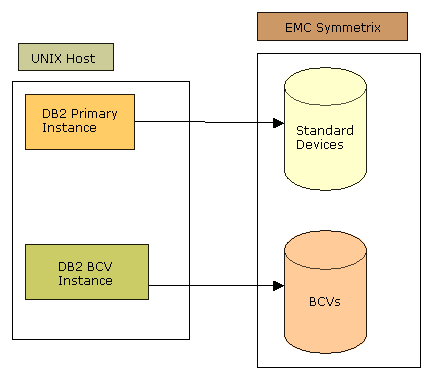
This diagram shows the BCVs split from the standard devices. The BCV instance and the primary instance are both started.
Additional Complexities
Although the concept of BCV use with DB2 is straightforward, there are two factors that added complexity in our environment:
1) We are a DB2 UDB EEE environment (multiple database partitions).
The “db2 set write suspend” and “db2 set write resume”commands need to be run on every partition.
For operational (and obvious) reasons, the interval between the “db2 set write suspend”and “db2 set write resume”commands should be a brief as possible, and there are some restrictions:
i. The database connection that runs the “db2 set write suspend”and “db2 set write resume”must be the same; therefore, the approach of running separate db2_all commands (i.e., one before the “EMC split” command and one after) is not possible.
ii. The ID that needs to run the “db2 set write …” commands must be the instance owner, and the ID that needs to run the “EMC split” command (which must run between the “db2 set write suspend” and “db2 set write resume”commands) is “root.”
Therefore the task of coordinating the timing of the “db2 set write …” commands for each partition, and the single “EMC split” command, while minimizing the duration of write suspension, provides a small challenge.
2) We had to put both the primary database and the “copy” database on the same O/S image.
This configuration is supported, but not recommended: one O/S image cannot have two hdisks with the same name. For this reason, when the primary and BCV disks are synchronized, the BCV hdisks cannot be “seen” by the OS. After the split occurs, some internal “magic” has to happen to internally rename these copy hdisks before they can be “seen” by the O/S. The details of this are beyond the scope of this article, but on AIX the most relevant command is “recreatevg.” If you were implementing on separate O/S images, you would probably have identical database, instance, and filesystem names between the primary and copy environment (although in an SP environment, you may be forced to have different instance names due to the cross-mounting of home directories).
In our environment we had to have different instance and filesystem names. This required building a large config file for use by the db2inidb command to tell DB2 where to find the internal files. We actually rebuild this config file “on the fly” just before running the db2inidb command to ensure it is up to date. Finally, the instance name is in the directory structure of the database directory, which is also one of the filesystems that has a BCV copy, so this has to be explicitly renamed on that copy before running the db2inidb command.
Other Uses of Our BCV Database
Though the main use of our BCV copy of the database has been to allow users to continue to access their data while new data is loaded, it has proven useful in other situations. It provides us with the ability to do selective restores. Since our BCV database is a copy of our production database before we loaded new data into it, if we run into data issues we can selectively copy back a table or part of a table.
The BCV copy has also been used to do performance benchmarking when we want to work with data that is production size. While the performance on the BCV devices is slower because of the type of disk they are using, we can still get relative performance information from using the BCV database.
Summary
This technology has served us well and meets the original objectives, and then some. We have successfully reduced the overall load time by several days while maintaining data availability at all times. We would suggest, however, that (particularly in our environment) the implementation is complex and needs to be documented and managed carefully.
References
“Split Mirror using Suspended I/O in IBM DB2 Universal Database Version 7” — Shahed Quazi
DB2 Command Reference Version 7.2
“Creating No Data Loss Standby Databases with IBM DB2 Universal Database 7.2, EMC Timefinder and EMC SDRF”—John Macdonald and Enzo Cialini
--
Geoff Daw is has been working as DBA for the last 16 years and has worked on many different DBMS’s during his career. The last three years, he been working with DB2 UDB EEE in a data warehouse environment.
Chris Wood is currently an independent consultant; he has been a DBA since 1989, working mainly in DB2 environments. He has focused almost exclusively on data warehousing since 1996.
Brenda Castiel is a past president of the International DB2 Users Group (IDUG) with more than 20 years of experience in IT development, marketing, and IT consulting. She works in the Business Intelligence practice at EDS.
Contributors : Brenda Castiel, Geoffrey Daw, Chris Wood
Last modified 2005-04-12 06:21 AM