
Implementing Real-Time Data Warehousing Using Oracle 10g
An interesting new aspect of Oracle’s recent data warehousing product announcements has been an emphasis on real-time, and near-real-time, data warehousing. So what is real-time and near-real-time data warehousing all about, why might your business users start asking for it, and how would you implement them using the Oracle 10g database and Oracle Warehouse Builder?
Introduction
Traditionally, most data warehouses use a staging approach to loading data into the warehouse fact and dimension tables. Data that needs to be loaded into the warehouse is first extracted from source tables, files, and transactional systems, and is then loaded in batches into interface tables within the staging area.
Then, the data within these interface tables is transformed, cleansed, and checked for errors, often with temporary staging tables being created on the way to hold the versions of the source data as it is being processed. This cleansed and transformed data is then loaded into the presentation area of the data warehouse, which can either be set up as a Kimball-style collection of fact and dimension tables, or as a more regular set of third-normal-form warehouse tables.
Once this loading has taken place, aggregates and summaries are either recreated or refreshed, and in some cases, separate OLAP databases must then be updated with data from the data warehouse.

The process of loading warehouse data, usually referred to as the Extraction, Transformation, and Load (ETL) process, can take anywhere from a few hours to several days to complete, and can require many gigabytes of storage to hold the many versions of staging and interface tables. Because of the time taken by this traditional form of ETL, it’s usually the case that the data in warehouses and data marts is at least a day or two out of date; in fact, usually it is between a week and a month behind their source systems.
This “latency,” as the situation is known, has in the past however not usually been seen as too much of an issue, as data warehouses were not considered operational, business-critical applications, but rather more as a way for a small group of head-office analysts to do trend analysis.
Real-time, and Near-real-time, Data Warehousing
The very popularity and success of data warehousing has, however, lead to changes in the way warehouse data is being used. Firstly, organizations have noticed that their data warehouse gives them an unparalleled complete view of their business, allowing them for the first time to bring together an integrated view of all their customer data, all their product details and transactions, and all customer interactions, in a readily available and understandable form and recorded back for many years.
On top of this “perfect record of the organization,” it is now possible to run advanced analytics, market and customer segmentation, data mining, and customer analysis that help the organization obtain a very detailed understanding of its market and of its customers.
What would therefore be ideal would be to put this information in the hands of salespeople, shop assistants, call centre staff, and anyone else who deals directly with customers, giving them the ability to spot a customer who is likely to defect to a competitor, to know when a better price could be obtained for a product or service, or at least to know that a customer has repeatedly experienced the problem that they’re calling about today.
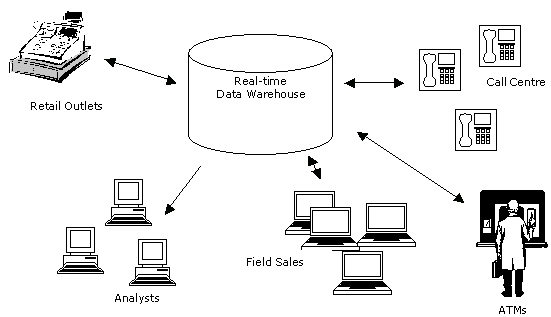
All this information is held in the data warehouse; the problem is, unlike trend analysis, for this kind of customer-facing work, you need access to the very latest customer and transaction data, and data that is, at best, a day or, at worst, a month or more out of date doesn’t meet the requirement.
Data warehousing professionals have historically resisted the use of their warehouse data within operational systems. This resistance is partly from a philosophical point of view in that their systems were principally designed for offline trend analysis and OLAP analysis, but also because, until recently, it wasn’t practical to have “zero-latency” data warehouses — the process of extracting data had too much of an impact on the source systems concerned, and the various steps that you needed to go through to cleanse and transform the data required multiple temporary tables and took several hours to run. However, the increased visibility of (the value of) warehouse data, and the take-up by a wider audience within the organization, has lead to a number of product developments by Oracle and other vendors make real-time data warehousing now possible.
Support Within The Oracle RDBMS
In real-time data warehousing, your warehouse contains completely up-to-date data and is synchronized with the source systems that provide the source data. In near-real-time data warehousing, there is a minimal delay between source data being generated and being available in the data warehouse. Therefore, if you want to achieve real-time or near-real-time updates to your data warehouse, you’ll need to do three things:
-
Reduce or eliminate the time taken to get new and changed data out of your source systems.
-
Eliminate, or reduce as much as possible, the time required to cleanse, transform and load your data.
-
Reduce as much as possible the time required to update your aggregates.
Starting with version 9i, and continuing with the latest 10g release, Oracle has gradually introduced features into the database to support real-time, and near-real-time, data warehousing. These features include:
- Change Data Capture
- External tables, table functions, pipelining, and the MERGE command, and
- Fast refresh materialized views
Change Data Capture
With versions of Oracle prior to Oracle 9i, to bring changed data across from source systems into your data warehouse (instead of loading in all of the source data and doing a complete refresh), you would normally look for columns in your source data or source files to indicate the creation and modified date of a row of data. Your process would then load in only those rows of data that were new or modified since your last load date.
From Oracle 9i onwards, however, the smart way to do this is to use “Change Data Capture.” This mechanism enabled automatic feeds of new or changed database records through to your data warehouse. Oracle 9i Change Data Capture worked under the covers by placing triggers on the source tables (that had to be on an Oracle database). These triggers fed changes resulting from inserts, deletes, or updates into change tables, which could then be used as the source for updates to your warehouse.
In actual fact, take up of Oracle 9i change data capture was limited, partly because it was a new feature, but mostly because of its invasiveness: DBAs were reluctant to allow triggers to be placed on their OTLP applications for fear of affecting application performance. To address this, Oracle 10g includes a new form of Change Data Capture, referred to by Oracle as “asynchronous” (as opposed to “synchronous”), because it uses the redo logs, together with the streams feature, to detect and transport data in an asynchronous fashion.
Oracle 10g Change Data Capture uses the advanced queue feature of the Oracle RDBMS to send data via message. In theory, this has no impact on the source system, but the drawback is that it requires both source and target databases to be Oracle 10g.
Oracle 9i Change Data Capture, which picks up changed data through triggers, is considered “real-time” data capture with little or no delay from the time when data is generated in the source system and when it appears in the change tables. Asynchronous change data capture, because it uses messaging and advanced queues, has an inherent small delay between data being generated and appearing in the change sets. Therefore, it should be considered near-real-time data capture. Regardless of whether change data capture is implemented synchronously or asynchronously, it is based on a publisher/subscriber model, in which the publisher (either triggers on tables, or a process mining the redo logs) captures the change data, and one or more subscribers read all or some of the change data from change sets.
If you’re interested in reading about an example of change data capture in use, a good place to start is Sanjay Mishra’s Oracle Magazine article, “Capturing Change,” which looks at Oracle 9i change data capture. You can also read Hermann Baer’s Oracle whitepaper, “On-Time Data Warehousing with Oracle10g — Information at the Speed of your Business,” and Mike Schmitz’s, “Experiences with Real-Time Data Warehousing Using Oracle Database 10G” Open World presentation.
External tables, Table Functions, Pipelining, and the MERGE Command
Most DBAs who are responsible for Oracle data warehouses will be familiar with external tables, table functions, and the MERGE command, three new features introduced with Oracle 9i to support the ETL process.
The external tables feature allows you to embed the SQL*Loader control file into a table DDL script; the file can then take advantage of parallelism, can be joined to, and can be used as an input to the new MERGE command, allowing you to insert and update data into another table in a single atomic DML statement. Apart from the convenience of not having to run separate SQL*Loader processes, external tables avoids the need to load data into interface tables within your staging area, since the external table is the interface table.
Table functions are useful as a way of taking PL/SQL or Java procedural routines used for cleansing and transforming data, and turning them into PL/SQL functions. These functions can then take either scalar data or tables of data as inputs, process the data, and return tables of data as output. What makes table functions particularly interesting is that the input tables can in fact be external tables or change tables, allowing us to apply transformations to data arriving in real time.
In addition, it is possible to “pipeline” these table functions; pipelining makes Oracle start returning rows from the function before processing has finished. By pipelining table functions, you can string a number of them together and require them to “pass off” rows to the next process as soon as a batch of rows are transformed, rather than each staging process waiting until the previous one has completed before starting its processing.
Once our source data is cleansed and transformed, it would normally be used to update our dimension and fact tables. In the past, we’d have accomplished this by using a combination of insert and update statements. With Oracle 9i, we’ve now got the MERGE command, which does this in one step. What’s more, we can wrap up the whole transformation process into this one MERGE command, referencing the external table and the table function in the one command as the source for the MERGEd data.
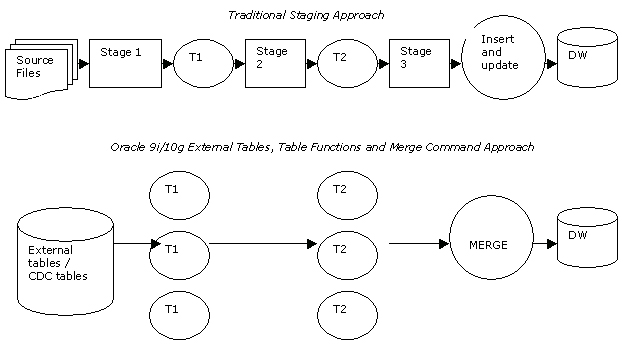
For more details on external tables, table functions, and the MERGE command, take a look at my article, “Streamlining Oracle 9i ETL With Pipelined Table Functions,” or Bert Scalzo’s book, Oracle DBA’s Guide to Data Warehousing and Star Schemas, which has some excellent examples of these three new features in use.
These three Oracle 9i features give us a way of significantly reducing the amount of time it takes to load our data warehouse, and the opportunity to reduce the latency between receiving our source file extracts or changed data, and loading data into the warehouse fact and dimension tables.
Fast-Refresh Materialized Views
One final feature of Oracle 9i and Oracle 10g that supports real-time and right-time data warehousing is the fast-refresh materialized views feature. In the past, DBAs created standalone summary tables that contained commonly used aggregated data, to speed up the response time of end user queries. When new data was loaded into the warehouse, these summary tables had to be dropped and recreated, so users had no access to them whilst the rebuild took place.
With materialized views, introduced with Oracle 9i, the DBA can create snapshot tables based on SQL queries against warehouse detail tables, with an inbuilt mechanism to refresh the snapshots when the underlying data has changed. When these materialized views meet a number of conditions, you can update the snapshots with incremental, changed data rather than completely rebuilding. This dramatically reduces the time needed to refresh your summaries and makes them available to your end-users far earlier.
By combining all of these new database ETL features, it now possible to reduce or even eliminate the time required to source, transform, and load data. But how is this all to be synchronized and orchestrated, and what if our cleaning and transformation needs are more complex? Enter the next version of Oracle Warehouse Builder, codenamed “Paris,” which is designed from the ground up to support real-time data warehousing.
Oracle Warehouse Builder 10gR2, Codenamed “Paris”
Oracle Warehouse Builder is Oracle’s ETL tool and was featured in my recent article entitled, “An Introduction to Oracle Warehouse Builder 10g.” Previous and current versions of Oracle Warehouse Builder were excellent tools for building data warehouse batch load processes, managing the full project lifecycle, and propagating data and metadata to other Oracle business intelligence products. However, individual Oracle Warehouse Builder jobs are run in batch mode, and what Oracle Warehouse Builder lacked, particularly in comparison to high-end ETL tools such as Informatica PowerCenter, was the ability to transform and load data as it was generated (i.e., not in a batch, but as a stream of new and updated data). This is an essential prerequisite for real-time data warehousing.
This issue is being addressed with the forthcoming release of Oracle Warehouse Builder, known as version 10g Release 2 or by its development codename, Paris. Previous versions of Oracle Warehouse Builder provided access to the external table, table function, and MERGE commands introduced with Oracle 9i. Oracle Warehouse Builder Paris provides, for the first time, a graphical front-end to Change Data Capture, both synchronous and asynchronous, and comes with additional features unique to Oracle Warehouse Builder for building real-time data transformations.
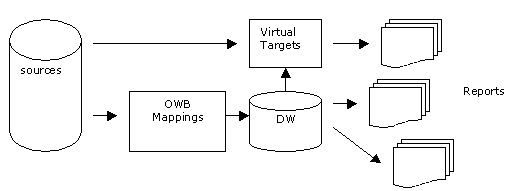
Oracle Warehouse Builder Paris uses the familiar mapping approach to transforming data, allowing you to graphically map source data to target tables, facts, or dimensions, and incorporates any number of individual column and table transformations to cleanse and manipulate the source data. Like all Oracle Warehouse Builder mappings, they are fully documented with metadata being stored in the Warehouse Builder design repository, allowing the full impact of changes to be managed through the project lifecycle.
To implement these real-time data warehousing features, Oracle Warehouse Builder uses Oracle 9i and 10g features such as asynchronous Change Data Capture and streams when near-real time data integration is required. By using these features, and the new ability for Oracle Warehouse Builder Paris to deploy mapping so that it can “listen” for messages containing changed data, the DBA can set up “push-based,” message-orientated data processing, processing data as and when it arrives and feeding it directly into the data warehouse. Then, because Warehouse Builder mappings are deployed as PL/SQL code, and PL/SQL can be exposed as a Web service, it is possible to publish Oracle Warehouse Builder mappings and enable them to be called as a data source for any application that communicates via HTTP.
Another way to use Warehouse Builder Paris mappings in a real-time situation is to use “virtual targets.” By using mapping, not to load a table, but to publish data into an API (this can be a table function for example), then publish it as a Web service, you can use the advanced data cleansing capabilities in any application, whether in real-time data cleansing or in a real-time data warehouse scenario.
Lastly, as mentioned before, the current release of Oracle Warehouse Builder already supports the use of table functions for transforming data; however, this was an incomplete implementation. Table functions could only be used as the input to another table or transformation, but could not themselves take a table of data as their input; this removed their ability to be used as part of an external table–table function– MERGE-statement combination. However, the Paris release completes the implementation of table functions, with either scalar values or tables of data now being allowed as the function input, providing the capability to design mappings that extract, transform, and load data at execution time without the need for intermediate staging tables.
For more details on the forthcoming Paris release of Oracle Warehouse Builder, take a look at Paul Narth’s recent Oracle Open World presentation, “An Introduction To Oracle Warehouse Builder ‘Paris’” and this recent weblog article.
Conclusions
In the past, there wasn’t a real requirement to make data warehouses “real-time” or even “near-real-time.” Users of the data warehouse were mainly carrying out trend analysis and ad-hoc analysis, and had no real need for up-to-the-minute data. However, the broadening of the user base for data warehouses, together with a requirement within organizations for business intelligence that contains up-to-date information, has lead to database vendors to build real-, and right-time data warehousing features into their database and developer tool products. Oracle has been incrementally adding such features to the Oracle database and to Oracle Warehouse Builder; with these new features, it is possible to reduce, and in some cases even eliminate, the time require to source, transform, and load data into the data warehouse, and implement real-time data warehousing.
--
Mark Rittman is a Certified Oracle Professional DBA and works as a Consulting Manager at SolStonePlus, specializing in developing BI and DW applications using the Oracle Database, Application Server, Discoverer, Warehouse Builder, and Oracle OLAP. Outside of Plus Consultancy, Mark chairs the UKOUG BI and Reporting Tools SIG, and runs a Weblog dedicated to Oracle BI and Data Warehousing technology. Mark recently was awarded an OTN Community Award for contributions to the Oracle developer community, and is a regular speaker at Oracle User events in both the UK and Europe.
Contributors : Mark Rittman
Last modified 2006-02-08 02:54 PM
Thanks for the interesting article. How do you cope with the following tension between real-time, bitmap indexes and materialized view refresh:
BMIs (bitmap indexes) can/do grow under DML. However I need them for enabling a successfull star transformation. Disabling them before the MV refresh can confront my users with a message 'BMI in unusable state' and if I allow that in their session (alter session set skip_unusable_indexes=true), they might stumble in far from optimal data access pathes. Keeping them in place however during the refresh can obstruct my parallel executed refresh (due to locking issues).
See the problem?
I consider accepting the size growth, and daily rebuilding them during the night.
What do/would you do?
Thanks, Erik