
Have It Your Way: Conformed Dimensions and Alternate Hierarchies
“Simplify, simplify, simplify.”
- Henry David Thoreau
Developing a set of shared, conformed dimensions is a challenge faced by any organization attempting to evolve an enterprise data warehouse environment from a collection of disparate data marts. Computer technologies can be both enablers and inhibiters to such an effort, but the fundamental issue is actually one of corporate diplomacy: how to reconcile the needs of the many — the enterprise as a whole — with the needs of the few — the individual, semi-autonomous business units.
In this article we’ll look closely into some of the issues that may be encountered within and around an effort to develop enterprise-wide conformed dimensions. We’ll also offer some suggestions on how these issues can be resolved in ways that can provide an enterprise with even greater benefits as a result of these challenging efforts.
Some Context: Dimensions and Master Data
Those with a data-oriented inclination will agree that corporate data should not be defined and segregated based largely on function; to the contrary, good data is widely-sharable data.
Master data management is an increasingly prevalent topic in IT, especially within the manufacturing industry. Master data typically includes, specifically, data on products and customers. The topic of master data is somewhat less prevalent in service industries such as finance, at least by that name, but it is just as relevant there nonetheless. Products are less concrete in such industries.
Dimensional data is nothing more or less than master data used for analytic functions; master data, conversely, is nothing more or less than dimensional data applied to operational functions. A master data record is equivalent to a dimension member.
From a business standpoint, reaching widespread agreement within an enterprise on a set of standard dimension members is identical to agreeing on a standard set of master data. There is no need for separate, redundant standardization efforts; one focused on master data and another on conformed dimensions.
Nodes and Hierarchies
Hierarchies add a level of complexity to dimension standardization efforts, over and above the already daunting tasks faced in master data standardization. For example, the set of customers, products, or geographic regions managed by business unit 1 (BU1) can be very similar to those managed by business unit 2 (BU2), but their hierarchical arrangements can be quite dissimilar.
A guaranteed career-limiting move for a naïve analyst would be to suggest that BU1 adopts the hierarchies of BU2, or vice versa. A diplomatic analyst would look for similarities rather than dwelling on the differences; that is, looking at the nodes rather than dwelling on the hierarchies. If BU1 has needs to analyze its performance across a different geographical hierarchy than BU2, accommodating both just requires two hierarchies, not two different sets of countries.
A dimension hierarchy may also change over time, and these changes may be dependent on or independent to the members of the dimension. Business unit reorganizations and product line re-categorizations are common examples where time-dependent hierarchies are needed. How disruptive do these re-configurations need to be? Should they affect dimension members, their inter-relationships, or both? And what do the before and after pictures look like? Let’s look at just one more complicating factor before addressing these questions.
Dimensions and Hierarchies
Sometimes the perception of a hierarchy agreed upon within a business analyst team actually includes sets of nodes from multiple dimensions. For example, an analytic hierarchy commonly used in reporting may contain enterprise business units as well as geopolitical areas such as regions or countries. Another common example is a hierarchy that combines general ledger accounts into higher-level report lines.
Fundamental data modeling principles should not be abandoned when crossing an arbitrary line into dimensional analysis. Only dimension nodes that are instances of the same entity class should be grouped together. It’s also important to understand that the concept of functional dependence is just as applicable to dimension members as it is to columns in a relation. The existence of the country of Switzerland is by no means dependent on the existence of Company A’s headquarters in Geneva, and no such arbitrary dependency should be imposed.
The proliferation of “overloaded” hierarchies such as this can be counteracted through increased awareness of the capabilities of multidimensional analysis. A fundamental function of multidimensional analysis is the superimposition of one dimension upon another within the same axis, dynamically at query time, resulting in a large potential number of overlapping hierarchies. There is no need to persist these in the database; in fact, their persistence prevents the combinatorial flexibility supported by dimensional software interfaces. Normalizing dimension node sets out of such mishmashes into separate, appropriate relations allows such flexibility, and is a prerequisite to arriving at a standard set of conformed dimensions.
Conformed Dimensions, Step-by-Step
The first step in arriving at enterprise-wide (or at least semi-enterprise-wide, for starters) conformed dimensions is achieving agreement on a basic set of dimensions across as many business units as is practical. (Two business units are even likely to be a challenge in most cases!)
Dimensions such as Time, Geography and Industry, being much more standard across organizations, are likely to be less controversial, to the point of triviality. The essence of any ambitious dimension conformance effort is likely to include Customer, Product and Organization Unit. These dimensions are much more subjective, and will vary much more from one enterprise to another. This variance is deeply tied to the unique identity and competitive position of the business itself.
After achieving consensus on a starter set of conformed dimensions, the next step is to separate dimension form from content, and dispatch with form as rapidly as possible.
Dimensional implementations can take many physical forms, and there are many resources on this topic; but, from a general, logical modeling perspective, there are three entity types per dimension, the first two being:
- Domain: contains each dimension member, entity instance, or node
- Linkage: contains each relationship between any two instances
Keep in mind that, for the purposes of this discussion, we have assumed a generalized, logical perspective. There may be differences between members’ attributes within a given dimension that could possibly justify subtype/supertyping or “snowflaking,” and there may be performance issues that require denormalization (e.g., flattening) hierarchies. But addressing these issues early on in business data analysis is a premature distraction, more appropriately addressed later in the effort.
The primary objective of the early generalized business data modeling is to prepare the way for:
- compiling a combined, de-duplicated, complete set of members for each dimension across all participating business units,
- and then, and only then, compiling all the valid linkages between members within each dimension — by hierarchy.
Aha, so … back to hierarchies again. Let’s see how we can be successful analyst-diplomats, accommodate multiple hierarchies owned by multiple business units, and satisfy the goals of multiple constituents — the “few” — as well as the enterprise as a whole.
Alternate Hierarchies
Let’s assume now that we have arrived at a combined and comprehensive set of members for a given dimension, say, “Product.” (Easy to say!) While this combined set is the intellectual property of the enterprise as a whole, each hierarchical arrangement of any subset of the members could be originated by, and the property of, the enterprise, a business unit, or perhaps even some ad hoc constituency. How do we distinguish each hierarchy from all others, and identify its owner? (Hello, data modelers!?) We do this by establishing our third entity type — a hierarchy entity type — along with primary-key and non-primary-key attributes for this entity type.
So now, to our domain and linkage entity types for each dimension, we add a hierarchy entity type. The hierarchy entity type is identified by a hierarchy primary key, and described by a non-primary-key attribute identifying the owner of the hierarchy. We then reference the hierarchy entity from each linkage from which it is built, allowing selections to be constrained to a single hierarchy.
To deal with those circumstances where the composition of a hierarchy changes over time, we can add effective and end date attributes to the linkage entity. Attributing this time interval to the linkage is the most appropriate representation of the real world, since adding, deleting or moving a node within a hierarchy does not logically create an entirely new hierarchy, just as a tree growing a new branch does not create a new tree. However, some hierarchy-management software operates with the notion of hierarchy “versions,” and physically appending an entirely new version may be acceptable in these cases, since an equivalent end-result can be achieved.
Figure 1 below illustrates the resulting logical model. (For those interested in gory details on alternative hierarchical designs, I recommend Joe Celko’s book Trees and Hierarchies in SQL for Smarties.
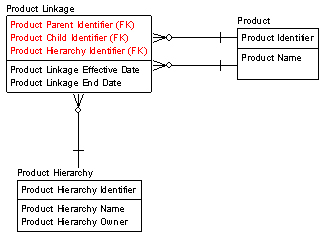
Figure 1: Example Hierarchy model fragment.
Now, we’ve achieved the goal of any good diplomat: keeping all the parties in the negotiations happy. The enterprise has achieved its goal of a standard dimension member list, and one or more enterprise-standard related hierarchies as well. At the same time each business unit (or any other constituency) can retain its favorite hierarchy or hierarchies, from which it can select when creating and executing dimensional reports and queries.
Sound too easy? Of course it does; we’ve conveniently time-compressed the hardest part: compiling a combined, de-duplicated, complete set of members for each dimension across all participating business units. The time-consuming aspects of achieving this objective lie in doing a comprehensive job of gathering all dimension members, and in resolving synonyms to de-duplicate the set of members. We know of analysts who have literally criss-crossed the globe in gathering dimension members to create a complete member list. And once the gathering is done, the work begins to assure that, for example, BU1’s Product A is truly the same as BU2’s Product A. But without taking these steps, actionable enterprise-wide analytics, or even cross-BU analytics, remains a worthy but unachieved goal.
And Yet One More Thing …
The context we’ve assumed for this article, up to this point, is the world of “structured” data — or what I prefer to call repetitive data. We’ve talked about leveraging and combining complementary standardization efforts for master data with similar efforts to develop conformed dimensions.
Another type of standardization effort is underway in many organizations, with the objective of developing standard “taxonomies” for classifying the content of “unstructured” data (which I prefer to call “narrative” data) such as documents, emails, and HTML pages. In the world of narrative data, taxonomies are hierarchically arranged classification schemes that are equivalent, for all practical purposes, to master data and dimensions. Our data-oriented colleagues should recognize another opportunity for sharing, as opposed to segregating, data across disparate functions. Methods and technologies are now available that support the integration of taxonomic and dimensional data to help achieve an analytic environment that spans the worlds of narrative and repetitive data. Interested readers are referred to “Meta Data & Knowledge Management: Iterative and Narrative Data: Common Ground?”, DM Review, and “Integrating Meta Data for Iterative and Narrative Data,” in Real-World Decision Support, for more details.
And the bottom line, as we data professionals have learned by experience, is that the primary requirements for achieving a quality, shared data resource are a clear vision and the sustained commitment to bring it to fruition. In the words of one well-known corporate diplomat named Lou Gerstner: “Strategy is Execution.”
--
Bill Lewis is a Principal Consultant with Enterprise Warehousing Solutions. Bill’s 20-plus years of information technology experience span the financial services, energy, health care, software and consulting industries. In addition to his current specializations in data management, meta data management and business intelligence, he has been a leading-edge practitioner and thought leader on topics ranging from software development tools to IT architecture. He has contributed to several online and print journals, and is the author of Data Warehousing and E-Commerce.
Contributors : William H. Lewis
Last modified 2005-04-27 11:05 AM