
Oracle Database 10g OLAP Performance Tips & Techniques - Part 1
Part 1 | Part 2
Related Podcast: Podcast: Mark Rittman - Oracle Openworld in Retrospect
The OLAP Option to Oracle 10g gives you the ability to store multidimensional cubes of data in your Oracle database, and perform OLAP queries on them using OLAP DML, regular SQL or query tools such as Oracle Discoverer Plus OLAP. Part 1 and 2 of this article provides tips and best practices for designing, loading, aggregating and querying Oracle OLAP cubes and in addition takes a look at some of the new features coming with 10g Release 2.
Introduction
The OLAP Option for Oracle Database 10g 10.1 is a recent addition to Oracle’s data warehousing capabilities, and gives you the ability to define multidimensional “cubes” of data and store them in special OLAP datatypes. Derived from Oracle Express Server, the OLAP Option builds in to the Oracle database the capabilities of stand-alone OLAP servers such as Oracle Express Server, Hyperion Essbase, and Microsoft Analysis Services. When you copy your data into an OLAP cube and then run a routine to aggregate the data, you can provide fast, flexible reporting for your users that frees them from the constraints of traditional relational reporting.
Just as with regular relational data warehousing, though, you need to give some thought as to the best way to design your OLAP cube, and how you should go about configuring the database, specifying storage, loading the cube, aggregating it, and then providing fast, predictable query responses for your users. Parts 1 and 2 of this article look at some tips and techniques for obtaining the best performance from the OLAP Option to Oracle Database 10g Release 1, and looks forward to some of the new features coming in 10g Release 2.
Sample dataset
The techniques and examples within this article use sample data and analytic workspace definition that you can download and install into a suitably configured Oracle database. To use this dataset and follow along with the examples, you will need to ensure that the following software is installed:
- Oracle Database 10g Enterprise Edition 10.1.0.2 or higher, with the data warehousing configuration
- RDBMS 10.1.0.4 patchset
- Analytic Workspace Manager 10g 10.1.0.4 or higher
The sample data and AWM10g template files can be downloaded from here:
and are based on the Global Widgets sample OLAP dataset used in the forthcoming Oracle Press book, Oracle Discoverer 10g Handbook, authored by Michael and Darlene Armstrong-Smith, and with contributions from the author of this article.
Instructions on how to install the sample data are provided in the readme.htm document that accompanies the sample data. The sample data download includes scripts to create user accounts and load them with source data, together with a number of Analytic Workspace Manager 10g template files that will be referred to later in the article. When using these template files, you should ensure that you connect to the GSW_AW account so that the source data and the analytic workspace are kept separate.
The following tables are created and populated in the GSW schema:
| Table Name | Description |
GS_CUSTOMER_DIM |
Denormalized dimension table for Customer data |
GS_PRODUCT_DIM |
Denormalized dimension table for Product data |
GS_CHANNEL_DIM |
Denormalized dimension table for Channel data |
GS_TIME_DIM |
Denormalized dimension table for Time data |
GS_PROMOTION_DIM |
Denormalized dimension table for Promotion data |
GS_SALES |
Fact table for sales data |
GS_SALES_LOAD_1 |
A subset of the sales data to represent an initial load |
GS_SALES_LOAD_2 |
A subset of the sales data to represent an incremental load |
The Global Widgets logical model contains the following elements:
| Dimension | Type | Hierarchy | Levels |
| Customer | User | Standard | Customer > City > District > Region > All Customers |
| Product | User | Standard | Product > Product Line > All Products |
| Channel | User | Standard | Channel > All Channels |
| Promotion | User | Standard | Promotion > Category > All Promotions |
| Time | Time | Standard | Day > Month > Quarter > Year |
| Cube | Measures | Dimensions Used |
| Sales | Order Quantity, Ship Quantity | Customer, Product, Channel, Promotion, Time |
The sample data setup scripts create two users:
- GSW, the schema that holds the tables containing the source data for the Global Widgets analytic workspace, and
- GSW_AW, the schema that will contain the analytic workspace.
All timings within this article were taken using the following hardware and Oracle versions:
- Dell Precision M60 laptop
- 2GB RAM
- Pentium M 1.7Ghz processor
- Windows XP SP2
- Oracle 10g 10.1.0.4 Enterprise Edition, with the partitioning, data mining and OLAP Options.
This article will now take you through the steps that need to be considered when building an efficient Oracle Database 10g OLAP analytic workspace.
Initial Design Considerations
How you design your cube, allocate space for it, and initialise the database can have a major impact on your cube performance. This section of the article will look at the things you should consider when designing your cube and configuring the Oracle database and looks at how changes you can make can affect the size and performance of your cube.
Estimating the size of the analytic workspace
The logical model for the Global Widgets analytic workspace contains five dimensions, and a single cube with two measures that implement these five dimensions. When you implement this model within Oracle Database 10g, a certain amount of disk space will be taken up by the dimensions, measures, summary data and OLAP metadata. Depending on how you store your data and the choices you make over summarisation, the disk space taken up by your cube could be quite considerable. The first question you will therefore need to answer is how much space will your cube likely take up?
To estimate the potential size of your analytic workspace, you need to first identify the number of dimension members within each dimension, counting not only the base-level dimension members but also those at higher levels of aggregation. With these figures it is possible to create the Cartesian product, which reflects all possible combinations.
To take the Global Widgets Customer dimension as an example, this dimension has a single hierarchy that has five levels, with the data for each level being sourced from columns in the GS_CUSTOMER_DIM table, like this:
| Level | Source Table and Column |
| Customer | GS_CUSTOMER_DIM.CUST_ID |
| City | GS_CUSTOMER_DIM.CITY_NAME |
| District | GS_CUSTOMER_DIM.DISTRICT_NAME |
| Region | GS_CUSTOMER_DIM.REGION_NAME |
| All Customers | GS_CUSTOMER_DIM.ALL_CUSTOMERS |
The total number of dimension members for this dimension will therefore be the sum of the distinct values in each of the source columns. The number of distinct values can be determined using a simple SELECT statement:
SQL> select count(distinct(custid)) from gs_customer_dim;
COUNT(DISTINCT(CUSTID))
-----------------------
39
These counts are then added together to give you the number of members for this dimension.
39 (customer level) + 27 (city) + 7 (district) + 4 (region) + 1 (all customers) = 78
The same calculation is then carried out for all of the remaining dimensions. The totals for the sample dataset are therefore:
| Dimension | Number of dimension members |
| Customer | 39 customers + 27 cities + 7 districts + 4 regions + 1 all = 78 members |
| Product | 22 products + 4 product lines + 1 all = 27 members |
| Channel | 2 channels + 1 all = 3 members |
| Promotion | 10 promotions + 3 categories = 13 members |
| Time | 2929 days + 96 months + 32 quarters + 8 years = 3062 members |
Next, these totals need to be multiplied together to give the total number of possible cells for each measure:
78 x 27 x 3 x 13 x 3062 = 251,494,308 cells
Then, multiply this number by the 8, the number of bytes that each cell will take up when using a decimal datatype:
251,494,308 x 8 = 2,011,954,464 bytes
Now add on 10-20 percent for the accompanying OLAP metadata (see metalink note 263833.1):
2,011,954,464 x 110% = 2,213,149,910 bytes
Finally, multiply this figure by the number of measures in the cube:
2,213,149,910 x 2 = 4,426,299,820 bytes or 4.32Gb
It is worth noting, at this point, how adding additional dimensions and measures can quickly increase the size of your analytic workspace. For example, if you added an additional dimension - Salesman, for example, with a total of 50 members - this would increase the potential size of the analytic workspace to around 230Gb, whereas if you were to remove one of the dimensions - promotion, for example, which has 10 members - the potential size of the analytic workspace would go down to 0.3Gb. You can also further reduce the space taken up by your analytic workspace by defining numeric measures with the Small Decimal datatype.
Dealing with sparsity
The figures that you have just calculated assume that every dimension combination has a measure value associated with it, and we will therefore need to find a place for each and everyone one of these values in our cube. However, in many situations there is only data for a small subset of all dimension combinations, e.g. not all products would be bought by each customer on each day, and therefore there are features in Oracle OLAP that allow us to significantly reduce the disk space taken up by these missing values.
In the example data, there are 251,494,308 possible dimension member combinations and ordinarily Oracle OLAP would assign a measure cell for each set of dimension member combinations. However, if you produce a count of all the distinct dimension member combinations in the source table for the two measures, you will find that the actual number of dimension member combinations is much smaller.
SQL> select count(distinct(to_char(custid)||
to_char(prodid)||to_char(channelid)||to_char(orderdate)|
|to_char(promoid))) distinct_cells from gs_sales;
DISTINCT_CELLS
--------------
11401
You can therefore calculate how sparse or dense the cube is likely to be by dividing the number of actual dimension combinations by the number of possible combinations in the source data. (Note: This does not consider any pre-summarisation that you might build into your cube.)
(11,401 actual / 251,494,308 potential) * 100 = 0.005% dense
There is no “set rule” for when a cube is considered sparse or dense, but I usually consider 30 percent to be a good cut-off point and with a cube with this degree of sparsity, you would want to use one of the sparsity-handling features in Oracle 10g OLAP to reduce the amount of space used to store null (or NA, as it’s termed in Oracle OLAP) data.
The template file GSW_AW_SPARSE.XML contains a logical dimensional model for the Global Widgets cube where certain of the dimensions are marked as being sparse.
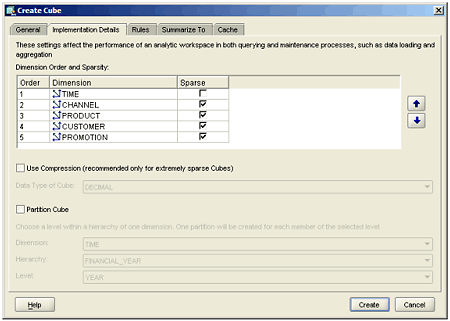
Figure 1: The Create Cube dialog, Implementation Details tab.
(Note: When you view these settings after loading the template file, all of the options for this tab will be greyed out, as it is not possible to change cube sparsity settings once the cube has been designed.)
On the “Implementation Details” tab of the Create Cube dialog, you will notice that it is, in fact, some of the dimensions that are marked as sparse, rather than the cube itself. This is because, for a particular cube, the source data may well have values for most of one dimension, but very few for all the others, and nine times out of ten, it is the Time dimension that is considered dense, with all the other dimensions considered sparse.
Analytic Workspace Manager generates a composite, a structure that holds just the dimension member combinations for the dimensions you designate as sparse, together with an index between the composite and the base dimension values, and dimensions measured within your cube by this composite rather than the individual, sparse dimensions. This will then considerably reduce the amount of disk space that your measures will take up. Note that Analytic Workspace Manager 10.1 creates one composite per measure in your cube, but Analytic Workspace Manager 10.2 gives you the additional option to create a global composite, a single composite that covers all measures in a cube. Creating a global composite reduces build time and storage space required, but is only suitable when your measures share the same sparsity characteristics, the aggregated composite will not be too large (less than 50m values), multi-writer support is not being used, and compression (detailed as follows) is not being used.
For cubes that are particularly sparse (the Global Widgets cube would fall into this category), you can also make use of a new feature introduced with version 10g of Oracle OLAP, known as compression, or “Compressed Composites”. Choosing to use compression will tell Analytic Workspace Manager to create the composite with the compression option, and this will, for certain types of sparse data, again significantly reduce the amount of storage required for the cube. With Oracle Database 10g Release 1, there are a number of restrictions on using compression, such that you cannot partially summarise your cube, and the only allowed aggregation method is SUM; however, these restrictions have largely been lifted in Oracle Database 10g Release 2.
An additional benefit of marking cubes as sparse and using compression where appropriate is that the amount of time required to load and aggregate your cube can be significantly decreased.
To give you an idea of the space and maintenance time savings that sparsity handling can produce, using the Global Widgets sample data and with all dimension levels presummarised, the final size of the cubes after loading with a full set of data was as follows:
| Cube Description | Template Name | Size in MB | Time to Maintain |
| Dense cube | GSW_AW_DENSE.XML |
1.386 Gb | 46 minutes |
| Sparse Cube | GSW_AW_SPARSE.XML |
1.074 Gb | 16 minutes |
| Compressed Cube | GSW_AW_COMPRESS.XML |
0.42 Gb | 3 minutes |
As you can see, handling sparsity effectively can significantly reduce the amount of disk space and time that is required to maintain your cubes, and if you are able to take advantage of the new compression feature in Oracle Database 10g, this can again bring your disk and time requirements down to just a fraction of that originally planned.
You should not, however, define all cubes as sparse regardless of the degree to which data is sparse. The composites that Oracle OLAP uses to handle sparsity combine members from the dimensions that you mark as sparse and require “unravelling” when used in queries. Although Oracle OLAP handles this process transparently, it still takes up some time, and the denser your cube is, the longer the process will take. Therefore, if you have a cube which is for example 80 percent dense, adding an unnecessary composite will decrease both maintenance and query performance.
The accepted, good practice is usually to leave the Time dimension as dense, and, therefore, outside the composite, as this ensures that all time values are clustered together, improving the runtime performance of time-series analysis. However, this can lead to a big increase in the size of the analytic workspace if daily data is used. And, from speaking to contacts within Oracle OLAP development, their current practice is to define all dimensions as sparse, including Time, which involves a small increase in query time, but a big decrease in build time and required disk space.
Ordering of dimensions
You might have noticed that the Implementation Details tab of the Create Cube dialog (Figure 1, above) that you can specify the order of dimensions within a cube. The order of dimensions is important as this can have a significant impact on the time it takes to load, and query, your cube.
You should put the dimension with the most members (the “fastest varying dimension”) at the top of your dimension list, followed in order by the next fastest varying, such that the last dimension in the list has the least amount of members (the “slowest varying dimension”); note however that compressed composites will automatically reorder dimensions to get optimal build performance. This operation is not possible with all types of aggregation, as it would sometimes change results (for example with the LAST aggregation operator).
When Oracle OLAP comes to store values for the measures in your cube, it clusters together in “pages” at the start of the available storage area those values relating to the first dimension in your list - the fastest varying one, the dimension with the most members - and then gradually fills out the rest of the storage space with measure values corresponding to the other, progressively slower varying dimensions. Typically, you chose the Time dimension as your fastest varying dimension, and by ordering it at the start of your dimension list you ensure that measure values corresponding to all the different time dimension members - days of the week, or months in a year, for example - are physically stored close together, making data retrieval faster.
It also makes sense to try and ensure that the order in which your source data is held and then loaded corresponds to the order in which your cube dimensions have been listed. If you have control over the order of records in the source data file, then you can create the data file to match the cubes in your analytic workspace. Alternatively, you can create a view over your source tables and then use an ORDER BY clause in the SELECT statement to reorder the source data; otherwise, you may need to choose between optimizing for loads and optimizing for queries when defining the dimension order of cubes in your analytic workspace
Storage considerations
Analytic Workspaces are held in LOBs within regular relational tables which can be identified through their AW$ prefix. Like any other tables, they are created within a tablespace which has one or more datafiles associated with it. Operations on Analytic Workspaces also make use of temporary tablespaces to store changes to multidimensional objects before the changes are committed, and therefore you will need to factor the use of regular and temporary tablespaces into your physical database implementation plans.
It is good practice to create separate tablespaces for each analytic workspace, and to specify an initial size for the datafile corresponding to the likely size of your Analytic Workspace, taking into account how you will handle sparsity. By pre-creating your datafile to the likely size for your Analytic Workspace, you will avoid the overhead associated with extending the datafile when your Analytic Workspace is loaded and maintained.
For the Global Widgets sample data, a suitable tablespace definition would be as follows:
CREATE TABLESPACE gsw_aw_data nologging
DATAFILE 'gsw_aw_data.dbf'
SIZE 2000M REUSE
AUTOEXTEND ON
NEXT 8M
MAXSIZE UNLIMITED
EXTENT MANAGEMENT LOCAL
SEGMENT SPACE MANAGEMENT AUTO
autoallocate;
Note the following clauses to the CREATE TABLESPACE statement:
- nologging minimises the amount of redo generated during a load, at the expense of recoverability. If your tablespace is created using the nologging clause, you will need to ensure your tablespace is backed up after the load has taken place. For the Global Widgets cube, specifying nologging meant that cube maintenance took around 85 percent of the time it would normally take.
- autoextend on ensures that the datafile associated with the tablespace will extend from the initial size you specified to accommodate new data
- maxsize unlimited allows the datafile to grow to the limits of the available disk space; note that you may wish to specify a limit, rather than UNLIMITED, in order that the datafile doesn’t eventually consume all the available disk space.
- extent management local specifies that the tablespace is locally managed (the default with Oracle Database 10g)
- segment space management auto tells Oracle to use bitmaps to automatically manage the free space within segments.
- autoallocate specifies that additional extents are sizes using a formula that increases the next extent size at regular intervals
The schema that will contain your analytic workspace can either use the default temporary tablespace, or you can create a new one for use with analytic workspace operations. This can be an individual temporary tablespace for each schema that contains analytic workspaces, or you can create one that is used by all schemas that hold analytic workspaces. The advantage of separating this usage out is that if the temporary tablespace becomes very big (during an EIF file import, for example) you can create a replacement one, alter the relevant users to make this their new default temporary tablespace, then drop the old one, without affecting all the other non-OLAP using users in the database.
A typical temporary tablespace definition for use with analytic workspaces would be as follows:
CREATE TEMPORARY TABLESPACE gsw_aw_temp
TEMPFILE 'gsw_aw_temp.tmp'
SIZE 5000M REUSE
AUTOEXTEND ON
NEXT 5M
MAXSIZE UNLIMITED
EXTENT MANAGEMENT LOCAL
UNIFORM SIZE 1m;
Oracle OLAP uses the default temporary tablespace for the user to store all changes to the data in an analytic workspace, whether the changes are the result of a data load, what-if analysis, forecasting, aggregation, or some other analysis. An OLAP DML UPDATE command moves the changes into the permanent tablespace and clears the temporary tablespace. Oracle OLAP also uses temporary tablespace to maintain a private session view of the analytic workspace to accommodate multiple users running queries and changing dimension status at the same time. Note that you can minimize the amount of temporary tablespace used by connecting to your Analytic Workspace in read-only mode, rather than read-write or read-write exclusive mode.
Note that you should specify a uniform extent size for the temporary tablespace, rather than have Oracle increase the size of the next extent automatically. In version 9i of Oracle OLAP, as each analytic workspace was held in a small number of LOBs, the recommendation was to make the uniform extent size between 1MB and 8MB; however, with Oracle Database 10g, each OLAP object is held in it’s own LOB, and as AW/XML templates can create thousands of objects per analytic workspace, each of which now requires its own TEMP segment, the uniform size of each extent should now be sized between 512K and 2MB.
To illustrate the benefits of preallocating disk space to datafiles, the following maintenance times were observed for the Global Widgets cube. Note that these timings are not directly comparable to other sets of timings and should only be compared to each other.
| Template File | Initial datafile size | Initial tempfile size | Tablespace creation time | Maintenance Time |
GSW_AW_SPARSE |
50 Mb | 50Mb | 4 seconds | 23 minutes |
GSW_AW_SPARSE |
1000 Mb | 900 Mb | 41 seconds | 14 minutes |
The conclusion from this is that although the preallocation of space can take a small additional amount of time, it is faster to allocate disk space at this stage than to do so incrementally as the cube is maintained.
Database initialisation parameters
There are a number of database parameter settings that you will need to be aware of when working with Oracle OLAP. These parameters define the amount of memory that is available to Oracle OLAP and other database processes, and determine to what extend parallel query can be used, what filesystem directories can be accessed, and overall limits to the amount of sessions that can be active at any one time.
When determining how memory is made available to your OLAP applications, there are two main things that you need to consider:
- The size of the System Global Area, and
- The size of the Program Global Area
The System Global Area (SGA) is a shared memory region that contains data and control information for your Oracle instance. The most important components within the SGA are the Buffer cache, the Shared pool, the Java pool and the Large pool, and from Oracle Database 10g onwards you can have Oracle automatically manage and tune the sizes of these components using Automatic Shared Memory Management, which is enabled via the SGA_TARGET parameter (below).
The Program Global Area (PGA) again contains data and control information, but for a single server process. It is private memory created when a server process is started, and when you use Oracle OLAP in relational mode it is used by sorts, order bys, hash joins and so on. Like ASMM, PGA memory can also be managed automatically for you by the PGA Advisor when the WORK_AREA_SIZE_POLICY database parameter is set to AUTO, which is the default with Oracle Database 10g.
When you are using Oracle OLAP in multidimensional mode (i.e. working with analytic workspaces) you will need to be aware of an area of memory called the OLAP Page Pool that is used as the paging cache; generally you will want this paging cache to be sized such that as much of your OLAP work is done in memory as possible, rather than being paged to disk.
When you are running your instance in dedicated server mode the OLAP Page Pool is part of the User Global Area (UGA) which is in turn part of the PGA. If WORKAREA_SIZE_POLICY is set to AUTO, the PGA Advisor will automatically size the OLAP Page Pool Size up to 50 percent of the PGA_AGGREGATE_TARGET value, and once this limit is reached, every subsequent user will acquire the bare operating minimum of around 4MB. For large OLAP applications (i.e. 8GB and above) you may want to monitor V$AW_CALC (detailed later) to ensure that users do not exceed 200MB to 500MB, depending on OS, hardware and database configuration; if they do exceed this figure, you may wish to manually set the OLAP_PAGE_POOL_SIZE parameter for a session, defining the minimum size for this area, if performance has degraded.
When are running in shared server mode however, the UGA is part of the SGA and any changes to its default size have to be made by you manually by setting OLAP_PAGE_POOL_SIZE. In addition, regardless of whether you are operating in dedicated or shared server mode, when the OLAP Page Pool is full, Oracle will use the Buffer Cache (part of the SGA) as swap space, which at a certain point can in fact improve the performance for large batch jobs (tip from Oracle development, untested by the author). Once the Buffer Cache is full however, as with any process data will start to be swapped to disk and therefore, it is good practice to size the SGA and PGA appropriately if you are looking to optimise the performance of your OLAP application.
To specify values for the PGA, SGA and (for when you are in Shared Server mode, the OLAP Page Pool), you can use the following database parameters:
SGA_TARGET
SGA_MAX_SIZE
PGA_AGGREGATE_TARGET
WORKAREA_SIZE_POLICY
OLAP_PAGE_POOL_SIZE
When this is set to any value > 0, it defines the target amount of memory that should be available to ASMM to assign to the Buffer Cache, Shared pool and other automatically tuned SGA components. This parameter should be set to between 50 percent and 60 percent of the total available memory on your server when working with OLAP data.
This parameter sets the upper boundary for SGA_TARGET. Ensure that you increase this accordingly to accommodate any increases to SGA_TARGET
This parameter sets a target for all PGA memory that Oracle will try and keep within. PGA_AGGREGATE_TARGET is important to OLAP developers as it defines (via the PGA Advisor) the size of the OLAP Page Pool when working in dedicated server mode, therefore you will want to increase it (to say 200MB - 400MB, higher up to 40 percent of total memory if necessary) when working with analytic workspaces in this scenario. Note that the initial setting for PGA_AGGREGATE_TARGET is set at 20 percent of the SGA_TARGET when you first enabled ASMM.
Used in conjunction with PGA_AGGREGATE_TARGET, enables the PGA advisor which automatically sizes areas such the OLAP Page Pool Size within the PGA (when in dedicated server mode)
As noted above, the OLAP Page Pool size is managed for you automatically by the PGA Advisor when running in dedicated server mode, but is set manually when running in shared server mode.
When tuning the size of the SGA_TARGET and PGA_AGGREGATE_TARGET, remember that if you are working in dedicated server mode (the default, and usually most appropriate for OLAP applications) most of the work is being done in the PGA - this is where the UGA is, which contains the OLAP Page Pool that caches your analytic workspace data. Only if the OLAP Page Pool is exceeded will the SGA be used (through the overflow into the Buffer cache), so any additional memory should be directed towards the PGA (via PGA_AGGREGATE_TARGET) rather than SGA if you want to do more OLAP work in memory. If you are working in shared server mode however, it is the SGA that will contain the UGA and the OLAP Page Pool, and therefore it is the SGA (via the SGA_TARGET parameter) that should be increased.
You can monitor usage of the PGA and OLAP Page Pool through the V$PGASTAT and V$AW_CALC fixed views. As an example, you can connect to the GSW_AW user and then display the values of SGA_TARGET, PGA_AGGREGATE_TARGET and OLAP_PAGE_POOL_SIZE using these SQL commands:
SQL> conn gsw_aw/password@markr10g
Connected.
SQL> show parameter sga_target
NAME TYPE VALUE
------------------------------------ ----------- ---------
---------------------
sga_target big integer 1G
SQL> show parameter pga_aggregate_target
NAME TYPE VALUE
------------------------------------ ----------- ---------
---------------------
pga_aggregate_target big integer 400M
SQL> show parameter olap_page_pool_size
NAME TYPE VALUE
------------------------------------ ----------- ---------
---------------------
olap_page_pool_size big integer 0
SQL> SELECT 'OLAP Pages Occupying: '
2 || ROUND (( ((SELECT SUM (NVL (pool_size, 1))
3 FROM v$aw_calc))
4 / (SELECT VALUE
5 FROM v$pgastat
6 WHERE NAME = 'total PGA inuse')
7 ),
8 2
9 )
10 * 100
11 || '%' info
12 FROM DUAL
13 UNION
14 SELECT 'Total PGA Inuse Size: ' || VALUE / 1024 || ' KB'
info
15 FROM v$pgastat
16 WHERE NAME = 'total PGA inuse'
17 UNION
18 SELECT 'Total OLAP Page Size: '
19 || ROUND (SUM (NVL (pool_size, 1)) / 1024, 0)
20 || ' KB' info
21 FROM v$aw_calc
22 ORDER BY info DESC;
INFO
-----------------------------------------------------------------
Total PGA Inuse Size: 11462 KB
Total OLAP Page Size: KB
OLAP Pages Occupying: %
SQL> SELECT vs.username, vs.SID,
2 ROUND (pga_used_mem / 1024 / 1024, 2) || ' MB'
pga_used_mb,
3 ROUND (pga_max_mem / 1024 / 1024, 2) || ' MB'
pga_max_mb,
4 ROUND (pool_size / 1024 / 1024, 2) || ' MB' olap_mb,
5 ROUND (100 * (pool_hits - pool_misses) /
pool_hits, 2)
6 || ' %' olap_ratio
7 FROM v$process vp, v$session vs, v$aw_calc va
8 WHERE session_id = vs.SID AND addr = paddr;
no rows selected
Now attached the GSW_AW analytic workspace.
SQL> exec dbms_aw.execute('aw attach gsw_aw.gsw_aw');
Now run the above statements again. You can see from the statement output how much space is taken up by the OLAP Page Pool as a whole for the instance.
PL/SQL procedure successfully completed.
SQL> SELECT 'OLAP Pages Occupying: '
2 || ROUND (( ((SELECT SUM (NVL (pool_size, 1))
3 FROM v$aw_calc))
4 / (SELECT VALUE
5 FROM v$pgastat
6 WHERE NAME = 'total PGA inuse')
7 ),
8 2
9 )
10 * 100
11 || '%' info
12 FROM DUAL
13 UNION
14 SELECT 'Total PGA Inuse Size: ' || VALUE / 1024 || ' KB'
info
15 FROM v$pgastat
16 WHERE NAME = 'total PGA inuse'
17 UNION
18 SELECT 'Total OLAP Page Size: '
19 || ROUND (SUM (NVL (pool_size, 1)) / 1024, 0)
20 || ' KB' info
21 FROM v$aw_calc
22 ORDER BY info DESC;
INFO
-----------------------------------------------------------------
Total PGA Inuse Size: 21107 KB
Total OLAP Page Size: 5271 KB
OLAP Pages Occupying: 25%
You can also run the following query to view PGA and OLAP Page Pool usage for a particular user:
SQL> SELECT vs.username, vs.SID,
2 ROUND (pga_used_mem / 1024 / 1024, 2) || ' MB'
pga_used_mb,
3 ROUND (pga_max_mem / 1024 / 1024, 2) || ' MB'
pga_max_mb,
4 ROUND (pool_size / 1024 / 1024, 2) || ' MB' olap_mb,
5 ROUND (100 * (pool_hits - pool_misses) /
pool_hits, 2)
6 || ' %' olap_ratio
7 FROM v$process vp, v$session vs, v$aw_calc va
8 WHERE session_id = vs.SID AND addr = paddr;
USERNAME SID PGA_USED_M PGA_MAX_MB OLAP_MB OLAP_RATIO
---------- ---------- ---------- ---------- ---------- ----------
--------------------------------
GSW_AW 141 9.72 MB 10.37 MB 5.15 MB 98.53 %
When sizing the SGA_TARGET and PGA_AGGREGATE_TARGET, ensure that you leave enough spare memory for the rest of the processes on your server (OS, other applications etc.). If you increase the size of the SGA_TARGET or PGA_AGGREGATE_TARGET beyond the amount of RAM that is available to you, the operating system will use virtual memory and start paging to disk, which will significantly slow down your application.
Other parameters, not related to memory management, that Oracle recommends that you set are:
PARALLEL_MAX_SERVERS = number of available processors, minus 1
SESSIONS = number of OLAP sessions * 2.5 + PARALLEL_
MAX_SERVERS
UTL_FILE_DIR = any directories that OLAP will access
UNDO_MANAGEMENT = AUTO
UNDO_TABLESPACE = name of the undo tablespace you define
JOB_QUEUE_PROCESSES = number of parallel update processes you
will use
Note that PARALLEL_MAX_SERVERS will almost certainly need to be adjusted by you as the default value of 20 is likely to be too high for most OLAP applications. This is because the parallel update feature in OLAP 10g is really the scheduling of concurrent jobs, and each of these jobs can use as many parallel query slaves as are available, and in addition, if you are working with RAC in a 10.1 environment, turning off OLAP Parallel Update is a workaround for a known bug. If using Parallel Update, you should also ensure that JOB_QUEUE_PROCESSES is set to an appropriate value.
As an alternative to adjusting the value of PARALLEL_MAX_SERVERS, you can also disable the parallel update feature for OLAP through the use of the _OLAP_PARALLEL_UPDATE_THRESHOLD hidden parameter:
SQL> alter system set "_olap_parallel_update_threshold" =
2147483647 scope = spfile;
System altered.
SQL> shutdown immediate
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> startup
Note also that the UTL_FILE_DIR parameter has now been superseded by the CREATE DIRECTORY command / CREATE ANY DIRECTORY role when exporting and importing EIF files, and this parameter only now needs to be set when using certain OLAP API procedures (metadata validation, use of DBMS_ODM and so forth). You may however wish to limit the CREATE ANY DIRECTORY role to just the DBA or OLAP administrator, as users may otherwise inadvertently grant themselves access to directories that contain vital system and log files.
Finally, note that the value for SESSIONS assumes that parallel update is enabled for OLAP (the default), and therefore has to be higher than normal to accommodate the additional parallel update PQ slaves sessions.
Conclusion
Oracle OLAP, though based on Express Server technology, is new as an option to the Oracle RDBMS and as time progresses techniques and approaches are being developed to optimise data loads, aggregation and user queries. This article sets out some tips and best practices for designing your cube. In part 2 of this article, we will cover loading, aggregating, and querying Oracle OLAP cubes, and highlight some of the new features coming with 10g Release 2. As adoption of Oracle OLAP continues, more techniques and best practices will be documented and I would be more than interested in hearing any feedback or approaches that readers have used.
--
Mark Rittman is a Certified Oracle Professional DBA and works as a consultant on Oracle BI and Data Warehousing projects. Mark also chairs the UK Oracle User Group BI & Reporting Tools SIG and is an Oracle ACE.
Mark would also like to thank Heiko Becker, Chris Chiappa, Jameson White, and Anthony Waite for their contributions to and technical review of this article.
Contributors : Mark Rittman
Last modified 2006-02-08 02:44 PM