
Replicating to Tables of Different Schemas
Introduction
The scope of this article is how to replicate to tables of different schemas using SQL Server 2000. There are four cases we will be looking at in this article:
- Replicating to a table where the subscriber table has less columns than the publisher table. This is illustrated in figure 1.
- Replicating to a table where the subscriber table has more columns than the publisher table. This is illustrated in figure 2.
- Replicating one table on the publisher to two or more tables on the subscriber. This is illustrated in figure 3:
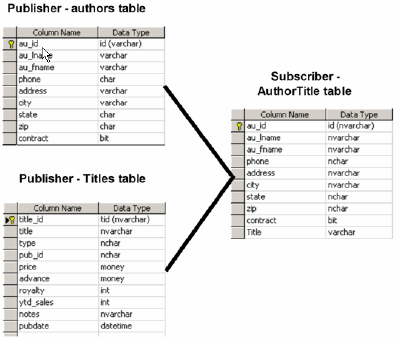
- Replicating two tables or more tables on the publisher to one table on the subscriber. This is illustrated in figure 4:
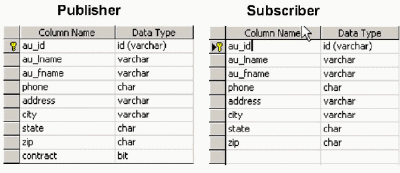
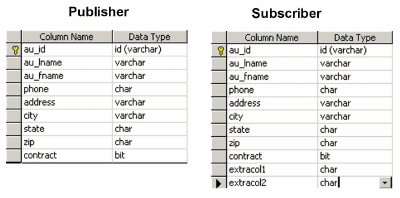

Case 1 — Replicating to a Table Where the Subscriber's Table has Less Columns Than the Publisher's Table
This case is the most trivial of cases and is most easily accomplished using the Create Publication Wizard. Create your publication as you normally do, and then when you get to the dialog box titled Customize the properties of the Publication, select Yes, I will define data filters, enable anonymous subscriptions, or customize other properties. Then, select Vertical Filtering, and uncheck the column you do not wish to be replicated to the subscriber.
You can also accomplish this by using the replication stored procedures. Click here for a brief code sample illustrating how you could accomplish this.
Notice how in this code sample, we add all columns (by not supplying a value for the @column parameter) in the first sp_articlecolumn call, and then drop the phone column in the second sp_articlecolumn call.
Case 2 — Replicating to a Subscriber Table Where the Subscriber Table has More Columns Than the Publisher table
This case is considerably more interesting than Case 1. Re-examine figure 2 again. Notice how the authors table on the subscriber has an additional column called address1. You will have to either provide a default value for this column on the authors table, on the subscriber, if you choose to pre-create it; or, supply a value for it in the replication stored procedures used to apply the transactions that originate on your publisher to your subscriber. The trivial solution for this is to create an indexed view on your publisher, which contains all the columns you wish to be present on the authors table on the subscriber. This indexed view will be replicated, by default, to your subscriber as a table. SQL Server 2000 does, however, allow you to replicate indexed views as either indexed views or a table. You could also use transformable subscriptions; however, these are highly scalable and do not support heterogeneous subscribers.
For example, click here for the indexed view you would create on your publisher to create the authors table on the subscriber that corresponds to the example illustrated in figure 2.
Notice that I am assigning 20 blank spaces as the value of address1. If I assign this column a value of NULL, it will be replicated as an integer.
When you replicate an indexed view using the Create Publication Wizard and get to the Specify Articles dialog box, click on the browse button to the right of your indexed view. And in the General tab of the Article properties dialog box, select A table as defined by the source indexed view in Destination object section. Again, this is the default option and will replicate the indexed view on the publisher to a table on the subscriber.
The problems with replicating an indexed view are:
- Indexed views do not support schema modifications using sp_repladdcolumn or sp_repldropcolumn.
- Some DBAs don't like using indexed views as there is a perception that indexed view take up space in your database, and there is a performance impact with using them.
The other option is to create a custom sync object which is merely a view. A custom sync object is merely a view which the replication subsystem uses to generate the bcp and schema files necessary to create the table's schema and data on the subscriber. You can't create custom sync objects using the Create Publication Wizard; you can accomplish this only by using the replication stored procedures. The stored procedures which are used to replicate the transactions from the publisher to the subscriber will be built based on this custom sync object as well.
To get this to work, you must set the schema options, create a schema script which will pre-create the table on the subscriber, and specify the name of your custom sync object in the sp_addarticle procedure.
Click here for our schema script.
Click here for an example illustrating how to do this.
Case 3 — Replicating One Table on the Publisher to Two or More Tables on the Subscriber
There will be occasions when you need to replicate a table on the publisher to more than one table on the subscriber. For instance, a friend of mine who works at an investment bank was replicating to a table on the subscriber. Triggers on the subscriber table would write to a second table on the publisher. These triggers were causing latency problems as the transactions were being replicated to the subscriber. The solution I proposed was to replicate the publisher table to both tables, and use the strategies discussed above to handle the differing schemas.
You can't do this through the Create Publication Wizard. Instead, you have to do it through the replication stored procedures, specifically the sp_addarticle procedure's parameters @article and @destination_table. The @article parameter is a name for the table or object you are replicating, and the @destination_table parameter is the name you wish to call the table to which you are replicating.
For instance, click here for a short code sample of how you would replicate the authors table to two different tables on the subscriber; the first table is called authors, and the second called authors1. Notice, also, that each article we add has a different name; the name does not necessarily have to be the name of the underlying object.
Case 4 — Replicating Two tables or More Tables on the Publisher to One Table on the Subscriber
Of all the cases we have looked at above, case 4 is the most complex case. The trivial solution is to use an indexed view again. If you can't use an indexed view, your options are more complex. The problem is that when the replication subcomponents create the stored procedures used to replicate the transactions occurring on the publisher to the subscriber, they can only replicate the transactions occurring on one of the base tables at a time; in other words, there is a per-table boundary which the replication components can't overstep.
Consider the tables in figure 4. If a transaction is applied to the authors table, and then the titleauthor table, the log reader will first read the transaction that was applied on the authors table on the publisher, and replicate it. This transaction will be represented as a series of singletons and passed to stored procedures to apply the transaction on the subscriber. The log reader will then read the transaction that occurs in the titleauthor table and replicate it.
So, how do you include in the transactions from the other table in your replicated stored procedure?
When you replicate two tables as one, there has to be some relationship between them (i.e. the tables are joined by a junction or intersection table, or a parent/child relationship). When you have a relationship, rows in one table will always define a complete record. For instance in a parent/child relationship, the child table will determine a complete parent/child row. Entries in the intersection or junction table will determine a complete row. Without the child or intersection row, you do not have a complete relationship.
Once you recognize this, it becomes a simple matter of keying off one table, and replicating all the tables that form part of this relationship. Then create custom stored procedures that will fill in the complete row on the subscriber using the member tables on the subscriber.
Let's have a look at an example to see how this works. We will be using a custom sync object and a creation script to perform this.
Click here for our creation script. We are going to be combining the titleauthors table and the authors table to get a count of all books written by the author:
Save this as c:\test.sql.
Click here for our custom sync object.
And, click here for our publication script.
You then have to create your replication stored procedures which are not presented here for space reasons.
Conclusion
This completes our tour of the options you have to replicate to tables with differing schemas. The easy ways out (indexed view or transformable subscriptions) are not always the optimal choice, and with a bit more work and thought you can come up with highly scalable solutions.
--
Hilary Cotter has been involved in IT for more than 20 years as a Web and database consultant in the tri-state area of New York, New Jersey and Connecticut. He was first recognized by Microsoft in 2001 with the Microsoft SQL Server MVP award. After receiving his Bachelor of Applied Science degree in Mechanical Engineering from the University of Toronto, he studied both economics at the University of Calgary and Computer Science at UC Berkeley. Hilary has worked for Microsoft, Merrill Lynch, UBS-Paine Webber, MetLife, VoiceStream, Tiffany & Co., Pacific Bell, Cahners, Novartis, Petro-Canada, and Johnson and Johnson. He has just completed A Guide to SQL Server 2000 Transactional and Snapshot Replication and has a companion volume on merge replication in the works for 2005.
Contributors : Hilary Cotter
Last modified 2005-04-18 02:06 PM