
Implementing an Archiving Strategy for Data Warehousing in SQL Server - Part 1
Part 1 | Part 2
Introduction
Once an enterprise has constructed a data warehouse, the Extraction Transformation and Loading (ETL) routines will begin to populate the warehouse structures and entities with historical data. This can manifest itself in the form of ongoing loads (i.e., the warehouse will have only up-to-date data from the current date on) or the requirement will be to load the warehouse for a period of past transactional history. Regardless of the requirement, at some point in the future, the warehouse management team will be faced with the challenge of managing query performance, ETL performance, and storage. To ensure that this balance is maintained between providing users with the information they need from the warehouse, versus ensuring that historical information is accessible, warehouse managers must establish an archive strategy.
An archive strategy will take into account the entire storage requirements for the data in the data warehouse and balance that with the needs of the end users. Warehouse managers must take into account the totality of the types of trending and analytics that business users need and what those needs translate into as storage requirements. Based on the analysis of these needs, the warehouse team can begin devising an archive strategy. Having a sound strategy for aging out data that is no longer required for immediate access by the data warehouse user population will ensure that performance for relevant data remains constant.
There are several approaches to archiving depending on the business situation. These can range from physically removing the data from the active database and persisting it to an offline server or storage medium (i.e., DVDs, tape). The second approach is to take a more proactive stance in archiving data using SQL Server’s capabilities to combine sets of data together in distributed partitioned views. By actively archiving data into separate entities on a periodic basis, history can be maintained online, but performance can be maintained on current and historical data simultaneously by using the distributed partitioned view’s capability to direct reads to the correct underlying table. The third approach is to combine these two methods. In this approach, archiving to separate entities occurs on a frequent basis, bound together by distributed partitioned views, and the older archived entities are removed from the warehouse and persisted to physical or offline storage media.
The following sections describe an approach to ensuring that warehouse archiving operations can be implemented in an automated fashion for any entity. The approach will ensure that these functions happen in a scheduled manner and report failure or success depending on the outcome.
Designing Archiving Entities
In many data warehouse environments, a star or snowflake schema contains one or more fact tables. The fact tables are entities that store business transaction details that are journalized or additive in nature. These tables house the measures for a data warehouse, which are then analyzed by the dimensions housed in separate entities related to the fact table. Because the occurrence of transactions is traditionally more numerous than those of dimension records (i.e., dimensions members have multiple transactions), these are the tables that are primary candidates for active archiving.
Date Segregated Fact Table Mirrors
The most popular strategy for archiving data is to create separate entities for a specified unit of time and then migrate data from the primary or current fact table to these structurally identical entities at a given interval. The separation of the data into physically separate entities has several advantages as well as disadvantages.
Advantages of Historical Fact Table Mirrors
The first advantage of these time segregated fact table mirrors is that the primary fact table that contains the most actively queried data remains slim and efficient. In other words, by eliminating data that is entirely out of scope for active or the most popular queries, the workload to retrieve data from these tables are optimized. SQL Server will not have to consider and sort through unnecessarily large amounts of rows to retrieve a small subset requested by users.
The second advantage is similar to the first in that those queries that do require information from the historical archive data on a semi-frequent basis now have the ability to execute solely against that information and they do not have to consider or sort through current data, or other historical data outside of the desired timeframe.
In addition to ensuring that the appropriate queries now are focused at specific entities that hold information targeted to them, this modularization of the data also enables warehouse administrators to easily persist the archived data to physical storage media. This effectively allows the warehouse team to “age out” old or stale data in order to make room for new data flowing into the warehouse.
Disadvantages of Historical Fact Table Mirrors
The drawback of implementing strategies of this nature is that the management of scripts and procedures required to ensure that the history tables are created on a scheduled basis and populated with historical data can be arduous and laborious. Additionally, to create these tables, the reporting application and users must have knowledge of the archiving table structures to properly shift their queries to these entities. This means that, as time progresses, the data that a user is interested in moves from the current fact table to an archived one with a different name. As a result, a report designer will have to change the physical table name to the new table name, depending on the scope of the data. Using traditional views to address the issue might be challenging as these views will incur a search across all entities, but the overhead associated with them will search all tables, and not the specific one the user is interested in.
Mitigation Strategy
The benefit of the historical fact table mirror approach to archiving follows best practices and ensures that the data warehouse information scope is preserved and remains available to users, while ensuring that all parts of the warehouse are operating efficiently to answer all queries. The goal is to mitigate the management process surrounding this table creation and automate it in such a fashion that it is flexible. The following sections describe how to engineer a system that can archive any table in the data warehouse using an automated process.
Archiving Solution Overview
The archiving solution will achieve the goals set forth in the mitigation strategy. The following diagram outlines the environment that will be used to discuss the implementation of the automated archive process.
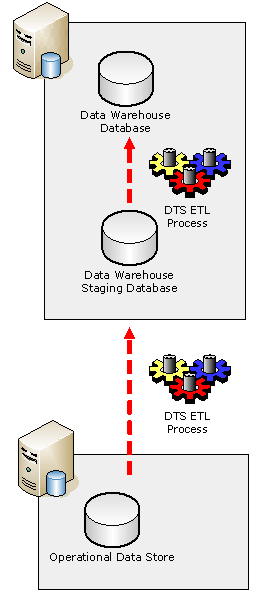
Figure 1.1: Data warehouse sample environment
As depicted in figure 1.1, the data warehouse resides on a single server that contains an active data warehouse database and a staging database. The data warehouse database contains all of the entities and relationships that comprise the star/snowflake schema. This database is complimented by a staging database, which serves as a working environment for data imports into the data warehouse. This staging environment allows for enriching data, applying any custom logic to massage the data, and to filter it to make it presentable for warehouse format. Additionally, the data originates from an operational data store (ODS), which contains a more normalized, less-enriched version of the data that it collects from a vast array of enterprise resources. The entire process of migrating data is facilitated by SQL Server Data Transformation Services packages, which are run from the SQL Agent on the data warehouse server.
Archiving Process Architecture
As discussed above, the primary archiving activities will take place in the data warehouse database. The approach is to create mirrored tables identical in structure to those of the primary fact table. Once these tables are created, data must be moved directly from the source fact table. Once the data is migrated, users will need to be able to query it in a method that is transparent to the user/reporting application, while simultaneously ensuring that the queries overhead is directed to the appropriate entity. The following diagram outlines the archive application architecture.
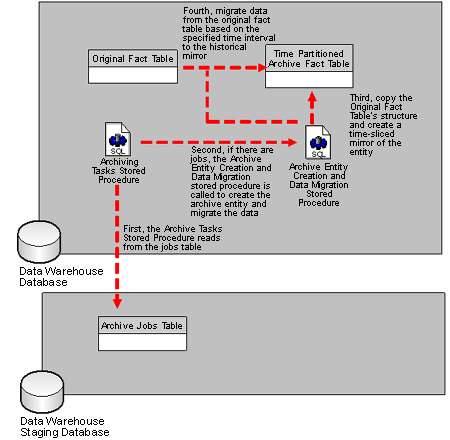
Figure 1.2: Archiving Process Architecture
Staging Database Architecture
As discussed in figure 1.2, the staging database serves the warehouse during the load process as a place for the ETL application to enrich, sort, filter and arrange for surrogate key lookups for the data warehouse. Once the data is in an appropriate format, the ETL application finally migrates the data into the data warehouse database.
The nature of the staging database makes it an excellent candidate to contain configuration and lookup tables. Because it is a tactical loading and preparation area, many of the automated processes that enable the ETL application to conduct its activities are here. Additionally, control tables and configuration tables exist here; these also provide warehouse administrators with the capability to activate or deactivate elements of the ETL application, or to change its behavior.
Because of the configuration and operational characteristics of the staging database, the archive control table will be stored in the staging database as well. The archive table contains a listing of archive tasks or jobs that the archive process will undertake at specified intervals.
ArchiveJobs Table
The ArchiveJobs table contains key columns and data that will provide adequate data to facilitate entity creation and data migration for the archive process. This archive process was designed to fit into multiple instances of a data warehouse, as well as other data warehouses, assuming they were constructed in a similar fashion as the environment depicted in figure 1.1. Additionally, this entity is designed to support other processes, such as an archiving solution for Analysis Services. Figure 1.3 depicts the ArchiveJobs table structure.
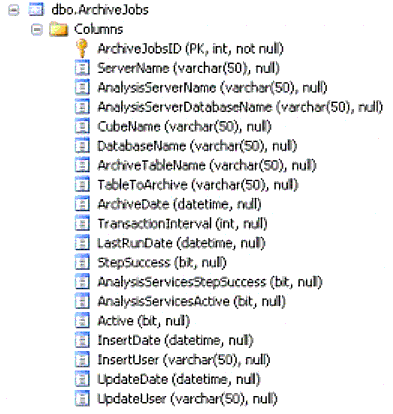
Figure 1.3: ArchiveJobs table
The archive jobs table will provide the associated stored procedures with database information, table information, and date settings to ensure that the correct historical mirror table is created from the correct entity being archived. Additionally, the archive table houses the results of each archive task. The process is designed to check for archive success prior to execution to determine if there were any failed archive attempts. If there were, the archive process will not run, and will alert administrators of an issue.
Similarly, warehouse administrators can turn archive jobs on or off based on the [Active] bit field. Doing so ensures that the specified archive job will not be included in the current run of the archive process.
Data Warehouse Database Architecture
The data warehouse database, as discussed above, contains the entire reporting star or snowflake schema for the warehouse. This database is the primary reporting and querying container and hosts all reporting and user queries. It also serves as the basis for compiling Analysis Services cubes. Because this database is the natural home for the fact and dimension tables, it is the best place for the procedures that will conduct the archiving entity creation, and for the data migration to reside.
The two stored procedures receive values from the archive jobs table and conduct the DDL and DML to move the data to a new historical entity. For the purposes of this article, the archive process is conducted monthly. As such, the data will be migrated into a new historical entity on a monthly basis. The historical archive tables will be named the same as their source entity, but will contain a date suffix inclusive of month and year.
In addition, the stored procedures will be responsible for creating a distributed partitioned view that will union together all historical and current data for a specified fact table and present them as a single entity available for end user querying. The value of the distributed partitioned view is that the overhead for querying a specific slice of historical or current data will only occur in the specified entity. The distributed partitioned view is also refactored by the process each time the archive process is run. This is to ensure that the distributed partitioned view becomes “aware” of any new historical fact table additions. There will be a distributed partitioned view for each fact table that is archived. The focus then shifts from using the fact table and its historical mirrors directly, to using the distributed partitioned view for all reports and queries.
Stored Procedures
The stored procedures are the primary drivers for the archive process. These stored procedures contain all the logic to interpret the jobs defined in the ArchiveJobs table in the staging database and conduct the archive operations in the data warehouse database. The following table outlines the function of each stored procedure:
| Procedure Name | Purpose |
| LoadArchiveTables | Wrapper procedure which consumes active, successful jobs from the ArchiveJobs table in the staging database and passes information to the AddFactArchive stored procedure for each job to create archive entities and to migrate the data from the source entity to its historical mirror |
| AddFactArchive | Procedure called from the LoadArchiveTables stored procedure which will create the mirror historical table and populate it with data using settings passed from the ArchiveJob table |
| ChgFactArchiveDPV | Procedure called from the LoadArchiveTables procedure which refactors the distributed partitioned view to ensure that all new historical entities and the current entity are contained within the distributed partitioned view |
Table 1.1: Stored procedures and functionality.
In part two of this two-part series, the architecture and components of the individual stored procedures will be covered in detail. I will discuss in detail the TSQL techniques that provide the capability to create and archive historical entities and to refactor and provide new tables into the distributed partitioned views. I’ll also detail the process surrounding the stored procedures interactions. By implementing these components into a data warehousing architecture, administrators can easily ensure that archiving is a manageable and reliable process that is transparent to end users. This will permit the team to manage the performance of the warehouse along with its storage requirements in a flexible manner that will meet the analysis needs of the organization.
--
Eric Charran is currently working as a Technical Architect and Web Developer, in Horsham, PA. Eric holds Microsoft Certifications in SQL Server and has significant experience in planning, designing, and modeling n-tier applications using SQL Server 2000, as well as architecting and implementing .NET framework based applications, solutions and Web services. Eric’s other professional skills encompass Database Administration, Data Warehousing and Application Architecture, Modeling and Design, as well as Data Warehouse Transformation and Population using DTS. Eric is also skilled in developing and implementing ASP.NET and Windows forms applications, using technologies such as COM+, the .NET framework, VB.NET and other .NET languages.
Contributors : Eric Charran
Last modified 2006-01-04 11:14 AM