
Online Processing
Part 3 in a series (Part 1 | Part 2)
This chapter discusses the IMS online environment, online application programs, backup, and recovery. It covers the following topics:
IMS Online Environment
The IMS/ESA product is made up of two major components-IMS DB and IMS TM. IMS dB supports the creation and maintenance of the database and processes database calls. IMS TM is a data communication system that supports online transaction processing for IMS dB This section discusses the components of the IMS online environment, the facilities available, and the types of programs that can be used.
There are major differences between batch processing and online processing. When you initiate a program in batch mode, a region in memory, sometimes called an address space, is assigned to it. The region will be loaded with the application program itself and the IMS modules it needs for execution. The batch application program will process independently of other jobs being run in the system. The batch application program begins with the first JCL statement, executes serially through the job, and (assuming it is coded properly and all systems are functioning correctly) completes successfully. It needs no intervention from a user or another program.
In the online environment, an application program can be started and stopped intermittently. It can be launched by a user or by another program. You don't have to submit JCL to initiate it. Instead, you can enter a transaction code from a remote terminal. When IMS receives the message with the correct transaction code, it will initiate the application program for you. In fact, any user with the proper authorization can initiate an online application program. Users can use the program in interactive mode from their terminals. These capabilities, and others, make online programs indispensable for most business computing environments.
Application Programming Environments
IMS supports five application processing environments that provide a wide range of processing options:
- dB/DC (database/data communications)
- Database Control (DBCTL)
- Data Communications Control (DCCTL)
- dB batch
- TM batch
dB/DC
In previous chapters we have discussed IMS databases and use of the DL/I command language in writing batch application programs. These application programs use the services of DL/I only. The IMS dB/DC environment provides a full implementation of DL/I and the data communications interface to allow online processing.
There are a number of differences between batch and online applications.
With online applications:
- Many users can access information in the databases simultaneously.
- The application can communicate with users at terminals and with other applications.
- Users can invoke the application from terminals.
- Users get the results of the application processing immediately.
- The database can be updated immediately.
Database Control
The DBCTL environment allows a transaction management subsystem other than IMS TM to have online access to DL/I databases and data entry databases (DEDBs). This means users of the Customer Information Control System (CICS) transaction manager, for example, can use DBCTL to access DL/I databases.
DC Control
DCCTL lets you use IMS TM to access non-IMS databases, such as DATABASE 2 (DB2*). DCCTL uses the IMS External Subsystem (ESS) Attach Facility to access other databases. When using DCCTL, you must define the subsystems that DCCTL can access in an IMS.PROCLIB member. DCCTL provides access to the following subsystems: online change
- MFS
- MSC
- DBRC
- device support
- IMS commands
Online Configuration
The IMS online processing environment consists of a central control region and a number of designated address spaces within the MVS environment. Figure 3-1 shows the configuration of the online processing environment.
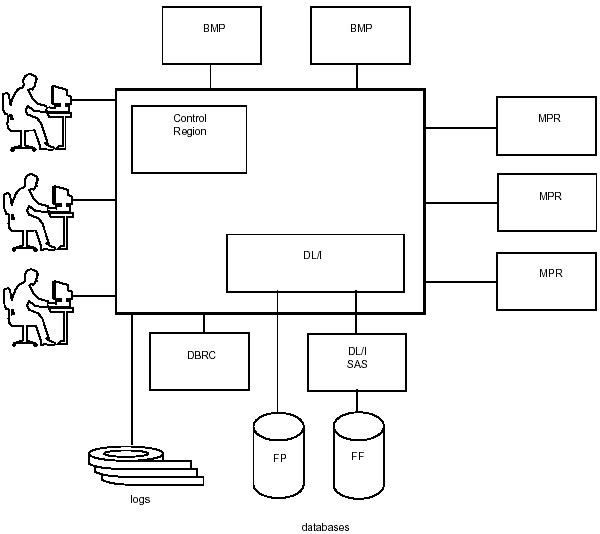
Figure 3-1: IMS Online Configuration.
Each box in Figure 3-1 represents an address space in an MVS environment. The online operating environment is controlled through the following specialized processing regions:
- control region (CTL)
- message processing regions (MPRs)
- batch message processing regions (BMPs)
- DL/I separate address space (DL/I SAS)
- Database Recovery Control (DBRC)
These regions provide the following functions:
Control Region: The CTL region is the address space that holds the control program that runs continuously in the dB/DC environment. It is responsible for a number of online functions. It holds the IMS control program, which services all communications DL/I calls. It is responsible for Fast Path databases that are accessed by an online program and for Fast Path I/O. It performs all IMS command processing. The control region also:
- supervises processing for message queues
- supervises communication traffic for all connected terminals
- is responsible for restart and recovery information
- is responsible for the operation of the system log
DL/I Separate Address Space: The DL/I SAS controls full-function databases accessed by an online program. It handles full-function database physical I/O for programs. It also is responsible for full-function program isolation (PI) locking.
Database Recovery Control: DBRC extends the capabilities of utilities for database recovery to allow easier recovery of full-function databases, Fast Path DEDBs, and databases accessed through CICS. DBRC has three levels of control:
- log control
- recovery control
- share control
See "Database Recovery Control" for more information. Address spaces that contain application programs are referred to as dependent regions. Each of the regions discussed below is a dependent region.
Message Processing Region: The MPR loads the application program and holds it to wait for messages. The control program controls scheduling of processing in the MPR. Output can be to a terminal or to another program.
Batch Message Processing Region: The BMP region contains application programs for processing against databases in a batch processing operation. The BMP has access to non-IMS DL/I databases such as flat files, as well as to IMS databases and online IMS message queues. Scheduling is done by OS/VS messaging.
Online Resource Allocation
Most examples of online programming discussed in this chapter deal with the dB/DC environment. Because most dB/DC systems handle a number of application programs and respond to messages originating from a variety of sources, IMS must have a broad-ranging control of resources. When you define the IMS system for dB/DC, you must provide IMS with certain information about the application programs and databases that IMS will be processing and about the communications resources that IMS will use.
Defining Application Resources
To use the resources available to application programs, you must define those resources to IMS for use with the application. This section discusses the resources available and how to define them to IMS.
Databases
To access databases through MPPs or BMPs, you must first define each database to IMS by entering a DATABASE macro that lists the DBD name of the database. The following DATABASE macro accesses a database whose DBD name is COLLEGE:
DATABASE COLLEGE
APPLCTN Macro
The dB/DC environment processes two kinds of online application programs: MPPs (see "Message Processing Programs" on page 3-18) and BMPs (see "Batch Message Processing Programs" on page 3-18). The main difference between the two is that IMS processes an MPP dynamically when it receives a message with an MPP as a destination. IMS processes a BMP when it is scheduled by a system operator. BMPs are typically used to process messages that are held in a message queue for that purpose. You must define MPPs or BMPs to IMS in the APPLCTN system definition macros during system definition. Here is an example of an APPLCTN system definition macro for an MPP:
APPLCTN PSB=PROGRAM1
Here is an example of an APPLCTN system definition macro for a BMP:
APPLCTN PSB=BMPPGM2,PGMTYPE=BATCH
Transaction Codes
Messages are associated with application programs through the use of transaction codes. You can assign more than one transaction code to an application program, but you can assign each application code to only one application. Transaction codes are defined through a TRANSACT macro, which follows the APPLCTN macro for the program it is assign to. You define a transaction code as a unique combination of one to eight characters. IMS creates a message queue for each transaction code. As messages are generated for the transaction code, messages are stored in the appropriate message queue pending processing. Here is an example of a TRANSACT macro for transaction code TRANS1:
TRANSACT CODE=TRANS1
Defining Communications Resources
In using the dB/DC environment, you must also define communications resources such as communications lines and terminals to IMS. When you define these resources to IMS, you are creating a communications network that IMS will use in routing messages to and from terminals and the central processor. Control of the hardware is managed by a type of subsystem called a teleprocessing access method. An example of a TP access method is Virtual Telecommunications Access Method (VTAM). The three major types of hardware defined to IMS are communications lines, physical terminals, and logical terminals.
Communications Lines
There are two major types of communications lines: switched and non-switched. With switched lines, users dial a number to gain access to the network. Switched lines allow the attachment of only one remote terminal at a time. With non-switched lines, terminals are connected directly to a dedicated line. Non-switched lines can be contention lines or polled lines. Contention lines allow only one contention-type terminal on the line at a time. Polled lines allow one or more terminals to use the line at a time. You must use a LINE macro to assign one or more remote terminals to a communications line and the LINEGRP macro to create line groups of lines that connect terminals of a similar type. Use separate line groups to group terminals with the same communication mode, polling technique, or transmission code.
Physical Terminals
Physical terminals are connected to a communications line and defined to IMS. Each terminal device in a line group is assigned a numeric identifier or address called a PTERM. A major distinction of terminal attachments is whether they are local or remote. Local refers to attachments made through a channel; remote attachments are made through a communications control unit. Because remote terminals are connected through one or more levels of communications control units, you must use a CTLUNIT macro to define the control unit to IMS when configuring the network.
Logical Terminals
Although the physical terminal is defined to the system, IMS uses logical terminal (LTERM) names to communicate with the terminals connected to the system. An LTERM name can be assigned to a physical terminal and later moved to a different physical terminal. You can associate many LTERM names with a single physical terminal to allow multiple users of the same terminal. When you define a TERMINAL macro, you can follow it with one or more NAME macros that list the LTERM names associated with that terminal.
In IMS online processing, LTERM names are used as message destinations in much the same way that transaction codes are used. IMS creates a message queue for each LTERM name. Messages addressed to that LTERM are held in the LTERM message queue. LTERM messages can be sent by MPPs, BMPs, or another logical terminal. The use of message queues allows the application program to be independent of the time of transmission or arrival of messages.
An application program interacts with a logical terminal in much the same way it does with a database. A GU call, for instance, retrieves a message segment from a queue, and an ISRT call inserts a message segment into a queue.
Here is an example of IMS data communications macros defining the line groups, lines, control units, physical terminals, and logical terminals on a network:
LINEGRP DDNAME=LINEDD,UNITTYPE=3270
LINE ADDR=L03
CTLUNIT ADDR=CT4,MODEL=1
TERMINAL ADDR=65
NAME LTERM5
TERMINAL ADDR=66
NAME LTERM11
NAME LTERM15
NAME LTERM22
Message Types
Units of communication that flow between terminals and the host computer in an online environment are referred to as messages. Most of our discussion of online processing revolves around the format and processing of messages. In IMS online processing there are three message types, based on their destination:
- transaction code messages
- logical terminal messages
- IMS terminal commands
Transaction Code Messages
Transaction code messages are used to communicate with application programs. Transaction code messages can originate from a terminal or from another program. Transaction codes are used to link transactions to the program that will execute them. A transaction can be assigned to only one program, but a single program can be assigned many types of transactions. The code is recognized by the system and is used to route the message to the transaction's message queue for processing by the application program.
Logical Terminal Messages
During IMS TM system definition, physical terminals are assigned logical names. A physical terminal can have more than one logical name, and a logical name can be changed, removed, or assigned to another physical terminal. The logical terminal name plays a similar role to the transaction code. The logical terminal name is used by the system to place the message in the right message queue for further processing. Logical terminal name messages are those messages addressed to a logical terminal. They can be sent by the host processing unit or by another terminal.
IMS Terminal Commands
Certain commands are reserved for specified IMS operating functions. They are used for operations such as starting, stopping, restarting, controlling, or changing IMS online. They are also used to run IMS utilities. Most of these commands are used by the master terminal operator (MTO) only. Their format is a slash followed by the command. The command /STOP, for example, prevents new IMS transactions from scheduling.
Message Segments
Although messages are transmitted as a single unit, they can be divided into one or more message segments. MPP and BMP programs actually retrieve messages one segment at a time, in much the same way that database records are retrieved one segment at a time. Input and output messages have segments reserved for IMS control information. Figure 3-2 shows the structure of a message segment.

Figure 3-2: Sample Message Segment
A message segment includes the following fields:
Length: A binary number that expresses the total length of the segment, including LL and ZZ bytes.
ZZ: Two bytes of control information used by IMS.
DEST-CODE: A 1- to 8-character destination code. For input messages, the destination code is normally a transaction code, but it can be an IMS command or LTERM name. For outgoing messages, the destination is normally the originating LTERM name as specified in the I/O PCB or a different LTERM specified by an alternate PCB.
b: A trailing blank.
Text: The text of the message. Length may vary, but each text segment has a maximum size of 132 bytes.
The message may consist of only one segment; the application program may require more information for processing than can be contained in one segment. If so, a sequence of several segments will be sent. When IMS receives an input message, it examines each segment for the end-of-segment indicator. If the message is a single segment, the end-of-segment is also interpreted as the end-of-message.
Message Processing
Application programs can use DL/I calls to retrieve and process messages. A GU function accesses the first message segment and a GN accesses subsequent message segments. The application program inserts the response to the input message into the I/O PCB, where it is retrieved by IMS and returned to the entering terminal. The application program can send output messages to a destination other than the originating terminal by using an alternate I/O PCB. Use of the alternate I/O PCB has the effect of placing the outgoing message in the message queue of a different LTERM name. When the message has been received by a terminal or by another program, IMS dequeues (deletes) it. If the message is not delivered successfully, IMS saves it in the appropriate message queue for future delivery. If you are using the message formatting service (MFS), the outgoing message is processed by MFS before being routed to the LTERM. MFS converts program output format to device output format (DOF).
I/O PCB
IMS has two types of PCB areas, a database PCB and a data communications PCB. The database PCB is defined as part of the PSB and describes the hierarchical structure of the database, the sensitive segments, and the types of DL/I calls that can be used (see "Program Specification Block" on page 2-5). The data communications PCB is used to allow the application program to communicate with remote terminals. This function is performed by a specific type of data communications PCB called an I/O PCB. You do not have to define the I/O PCB in an application program's PSB; IMS automatically generates it for you. You must, however, include an I/O PCB area in the application program's linkage section. In a batch program, you do not have to be concerned with the I/O PCB; only the database PCB is required.
The I/O PCB is generated by IMS and inserted automatically as the first PCB in the PSB parameter list for a BMP or MPP. Application programs use the I/O PCB to receive messages from the input message queue and to transmit messages back to the originating terminal. An application program uses a GU or GN call to retrieve messages from the message queue and an ISRT call to send messages to a terminal.
The I/O PCB generated by IMS resides outside your program. It is not added to the PSB source code. To use the I/O PCB, you must define a mask of the I/O PCB in your program to check the results of IMS calls. Your mask must contain the same number and size of fields as the I/O PCB, and they must be in the same order.
To match the I/O PCB, the mask in your program should have the following fields:
Logical Terminal Name: An 8-byte field containing the name of the LTERM that sent the message or that the output message should be sent to.
Reserved Field: A 2-byte field reserved for IMS.
Status Code: A 2-byte field that describes the results of a DL/I call.
Current Date: A 4-byte field that gives the Julian date the message was originated in a packed, right-aligned YYDDD format.
Current Time: A 4-byte field that gives the time the message was originated in a packed HHMMSST format.
Input Message: Sequence Number
A 4-byte field containing the message sequence number assigned to the message by IMS.
Message Output Desciptor (MOD) Name: An 8-byte field used only with MFS to specify the MOD to be used.
User Identification: An 8-byte field usually associated with RACF sign-on authority to contain the user's ID.
Group Name: An 8-byte field used by DB2 to provide security for SQL calls.
Figure 3-3 shows a sample I/O PCB mask as defined in the Linkage Section of a COBOL application program.
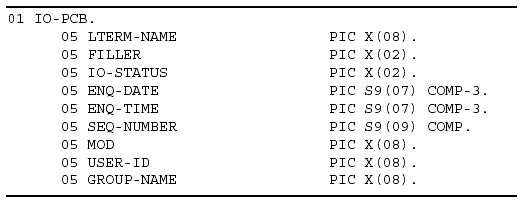
Figure 3-3: Sample I/O PCB Mask.
I/O PCB Status Codes
Here are the most common I/O PCB status codes:
Spaces: The call was completed successfully.
QC: There are no input messages in the application program message queue.
QD: The message contains no more segments.
AD: An invalid call function was used.
A5: This is the format name specified on a second or subsequent message ISRT or PURG call.
QF: The message segment has a length of less than 5 bytes (it contains control characters only, no message text).
Alternate PCBs
You may want to code a program that can send messages to a destination other than the originating terminal. You may want to include logic that will let the program send a message to a different terminal or to another program. You can do this through the use of an alternate PCB that you define in the application program's PSB. You can also make the alternate PCB modifiable, so that logic within the program can decide where to send the message. Make the PCB modifiable by including a MODIFY=YES parameter in the PCB statement.
You must also code an alternate PCB in the Linkage Section of your application program. The alternate PCB follows the I/O PCB mask and precedes the database PCB. Figure 3-4 shows a sample alternate PCB and its position in the Linkage Section of a COBOL program.

Figure 3-4: Sample Alternate PCB.
Message Switching
It is possible for an application to send a message to another application program. To do this, you must use an alternate PCB and use a transaction code rather than an LTERM name as the destination. When your application program issues an ISRT call to the alternate PCB and specifies a transaction code as the destination for the message, the message is placed in the transaction code message queue rather than an LTERM queue. The application program receiving the message will process it as with any other message.
Multiple Systems Coupling
You can communicate with terminals and programs in an IMS TM system other than your own through the use of an IMS facility called Multiple Systems Coupling (MSC). MSC establishes links between the two (or more) IMS TM systems and keeps track of the terminals and transaction codes belonging to each one. You can refer to terminals and transaction codes in your IMS TM system as local and to those in other IMS TM systems as remote.
In most cases, you will not need to make program changes to communicate with programs or terminals in a remote system. You perform an ISRT of the destination against the I/O PCB. MSC handles the message routing. You can determine whether an input message is from your system or a remote system, and you can set an alternate destination in a remote system for the outgoing message. IMS uses bits in the message reserved field to keep track of the origin and destination of messages to and from other IMS TM systems.
Message Scheduling
Message scheduling refers to the process by which an input transaction is united with its associate application program and is processed. All input and output messages are queued in message queues in virtual storage by IMS. Messages that are identified by transaction code or logical terminal can be queued in the order in which they are received. Distinct serial queues are created for each transaction or LTERM.
When a message has been processed or received by its destination, it is removed from the queue (dequeued) and the space in the queue is made available for another message. Figure 3-5 shows the flow of a transaction message.

Figure 3-5: Flow of Transaction Messages.
The scheduling of messages for processing is influenced by a number of factors, including parameters set in the PSB and others that can be grouped under the general heading of workload control.
PSB Scheduling
Each MPR can have from one to four message classes. You can assign messages to these classes by JCL when the PSB is created. Every transaction has a message class, which is assigned at system definition. Within each message class, messages can be assigned a priority that is defined at system definition. The control region uses all of these elements in scheduling messages for processing.
Workload Control
Workload control is based on the combination of a number of parameters that establish the processing schedule for messages:
Processing Limit
A processing limit can be set for each program. It establishes the maximum number of messages for that program that can be processed in one scheduling. It is set at system definition.
Limit Priority
If a transaction gets bumped by higher priorities for a certain length of time, its priority is raised, so that it can be processed eventually. Limit priority is assigned at system definition.
Parallel Processing
A program may be scheduled for serial or parallel message processing. If it is set for parallel processing, a parallel limit count establishes when to schedule an additional region for the program. The limit count is assigned at system definition.
Wait for Input
When an application program is loaded into an MPR, it is left there in a Wait for Input (WFI) status until its PROCLIM (maximum processing time) is reached. This is true even if no messages are in the queue.
Quick Reschedule
If no higher class or priority message is waiting and an application program reaches its PROCLIM, IMS resets the counter to zero without terminating the transaction. This can be disabled by setting the processing limit to 1.
Pseudo Wait for Input
Pseudo WFI (PWFI) allows the application to remain in the MPR until another input message is received, even though its PROCLIM has expired. When the next message is for the PWFI program, this eliminates the unnecessary overhead of terminating the program and then reloading it for the message. If the message is not for the PWFI program, the program is terminated.
Application Programs
The value of a database management system lies in its use by application programs to execute business processes. You can use several types of application programs to access the data stored in the database:
- MPPs
- BMPs
- interactive Fast Path programs (IFPs)
- batch programs
The types of application programs you can use allow you to use the database in batch mode only, in online mode, or in a combination of the two. MPPs, BMPs, and IFPs are online programs that execute in the IMS TM online environment. Batch programs are executed in the IMS batch environment, as discussed in "Online Configuration" on page 3-5. Programs that execute in the IMS TM environment must be defined to IMS before they can be used. This is done at system definition time in APPLCTN definition macros. Application programs can be written in COBOL, PL/1, C, VS Pascal, Ada, REXX, or Assembler language. The databases are accessed through DL/I statements, or calls, embedded within the application program code.
Message Processing Programs
MPPs are online transaction-initiated programs. They run in real time and can be interactive with the user. MPPs are loaded dynamically by IMS when a message for the program is initiated by a user or by another program. Although they are executed differently, they have the same basic structure as batch programs.
Batch Message Processing Programs
BMPs are initiated by JCL and can access operating system files and IMS databases. Messages directed to BMPs are held in a message queue until the BMP is scheduled by the operator. The BMP then reads the messages from its message queue and processes them.
Interactive Fast Path Programs
IFPs are used for applications that are identified with DEDB databases. IFPs process and reply quickly to messages from terminals. IFPs bypass IMS scheduling and are processed by the Fast Path EMH facility. IFPs are used for large transaction volumes that require rapid response.
DL/I Calls
The purpose of a DL/I call is to instruct DL/I to perform a certain action involving the data stored in the IMS database. Although a complete description of how to code DL/I calls is beyond the scope of this manual, you should understand certain concepts regarding the calls and how they are used. A DL/I call includes four parts:
CALL FUNCTION: Tells DL/I what needs to be done (for example, retrieve, update, insert, delete).
PCB: Gives the name of the PCB of the database that will be referenced by the call.
I/O AREA: Specifies the work area for the requested segment.
SSA: Specifies the segment and path of the data to be accessed.
Figure 3-6 shows the format of a DL/I call in a COBOL application program.
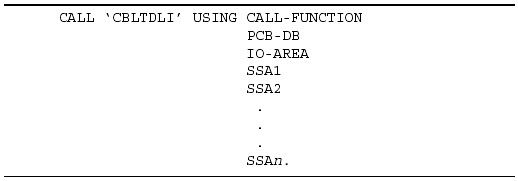
Figure 3-6: Sample DL/I Call Format.
Call Function Codes
Function codes specify the action to be taken by DL/I:
GU (get unique): Retrieves a specific segment. This call command does not depend on the current position within the database. DL/I always returns the segment specified (if it exists), regardless of position.
GN (get next): Retrieves the next segment in the hierarchy that satisfies the qualifications specified. The segment to be retrieved is determined by a combination of the current position in the database and the segment search argument (SSA). To establish position, a GU call often precedes a GN.
GNP (get next within parent): Retrieves segments in the order they are physically stored, just as GN, but limits the call to segments dependent on the established parent. The SSA tells DL/I which dependent to retrieve. A GNP call without an SSA retrieves the next dependent.
ISRT (insert): Inserts a new segment occurrence. Before issuing the call, you must code an I/O area for the new segment. The I/O area must contain the same fields in the same order, length, and data types that exist on the segment being inserted.
DLET (delete): Deletes the segment previously retrieved and all of its dependents, even if the application is not defined as sensitive to them. It must be preceded by a GHU, GHN, or GHNP call (see GET HOLD Calls). Deletes generally do not use SSAs.
REPL (replace): Replaces current data in a selected segment with new data from the I/O area. Like DLET, it must be preceded by a GHU, GHN, or GHNP call and generally does not use an SSA. The segment's key fields cannot be changed.
GET HOLD calls: GET HOLD calls have the same format as GET calls:
- GHU (get hold unique)
- GHN (get hold next)
- GHNP (get hold next within parent)
The calls hold the segment until it is replaced or deleted or until another segment is retrieved using the same PCB. GET HOLD calls must be performed before a DLET or REPL can be issued.
Database PCB Area
The database PCB specifies which database will be referenced by a DL/I call. The database PCB tells IMS which database view to use and provides a place for IMS to return results of the call to the application. Figure 3-7 shows an example of the database PCB entry for a DL/I call in a COBOL application program. The KEY-FEEDBACK field must be large enough to hold the longest possible concatenated key of the sensitive segments involved in the SSA.

Figure 3-7: Sample PCB Statement.
Database I/O Area
You must establish a working storage area where the segment you request with the call can be placed. It can also be used to insert or replace a segment. It is coded in much the same format as that of the PCB example shown in Figure 3-7.
If you are coding an online program, you must include a message I/O area to allow the program to communicate with terminals.
Transaction Codes
Transactions are messages that have a BMP or MPP (or IFP, in the case of Fast Path) as a destination. Each type of transaction must be identified to IMS by a transaction code. Transaction codes must be defined to IMS before they can be used; this is done at system definition time through the use of TRANSACT macros. Transaction codes are associated with a specific application program so that IMS can identify which application program processes the transaction. A transaction can be associated with only one application program, although an application program can process more than one type of transaction.
- Transactions are processed in the following sequence:
- The transaction code is entered at a terminal.
- The application program associated with the transaction is initiated.
- The input message is retrieved from the message queue.
- The input message is processed by the application program.
- An output message is sent by the application program.
- The last three steps are repeated until all messages on the application program's message queue have been processed.
Segment Search Argument
The SSA is used to specify to DL/I the segment and path of the data you want to access with the DL/I call. In most cases, a separate SSA is used for each hierarchical level on the path to the required segment. The SSA may be unqualified or it may be qualified with the key field name and value of the segment being accessed.
Figure 3-8 gives an example of a typical SSA entry in a COBOL application program. The KEY-FIELD-VALUE depends on the length of the key field of the segment being searched.

Figure 3-8: Sample Segment Search Argument.
An SSA contains the following statements:
SEGMENT NAME: This value tells DL/I which segment to access.
COMMAND CODES: IMS command codes can be used here to modify the DL/I call.
LEFT PAREN (OR SPACE): If left blank, the SSA will be an unqualified SSA.
KEY FIELD NAME: The key field, search field, or index field that will be used in the segment search.
OPERATOR: A relational operator (for example, EQ, GT, LT) can be used.
KEY FIELD VALUE: This is the value of the field that will be processed.
RIGHT PAREN: This statement is used to indicate the end of the SSA.
Conversational Programming
The technique of conversational programming was developed to overcome certain inefficiencies in the conventional, or non-conversational, way of processing messages. In many cases, an application program may need to process transactions made up of several steps. Additionally, the program may need a way of referring to the results of the previous iteration of the transaction. Finally, it is inefficient to allow an application to reside in memory during the entire time that may be needed for a user to go through a series of steps that result in a prolonged dialog with the program. Conversational programming overcomes these problems. The way conversational programming is implemented is through the use of a scratch pad area (SPA). The use of an SPA is the major difference between conversational and non-conversational programming.
Scratch Pad Area
The SPA is an area designated in virtual storage to be used store the results of a series of processing transactions. The SPA is similar in format to an input transaction. It includes a transaction code field that identifies the transaction code of the program associated with the conversation. Although the transaction code normally remains unchanged, the application program can be set up to pass the SPA to another application program during processing. To do this, the original application program inserts the transaction code of the program to receive the SPA.
The SPA is read by a GU call to the I/O PCB and message segments are then read with subsequent GN calls to the I/O PCB. You can write to the SPA by issuing an ISRT call to the I/O PCB. After issuing the first ISRT call, subsequent ISRT calls to the I/O PCB send message segments. You can terminate the conversation in two ways. The user can issue the appropriate IMS command to terminate the transaction or the application program can terminate the conversation by placing binary zeros in the transaction code field.
Figure 3-9 shows the format of a scratch pad area.

Figure 3-9: Scratch Pad Area Format.
Length: Two-byte field that gives the length of the SPA, including the variable-length text area.
Reserved: Four-byte field reserved for IMS. This field should not be changed by the
application program.
Trancode: Eight-byte transaction code field. This field is necessary for both input and output messages.
Text: Variable-length field for use by the application program. This field is also
called the user work area.
Expedited Message Handling
The expedited message handling (EMH) facility allows Fast Path transaction messages to circumvent normal IMS message processing. Use of EMH comes with certain restrictions. First, you must identify the transaction as a Fast Path type. Second, the message being processed must meet the criteria of a Fast Path message:
- single segment
- not edited by the MFS
- not an IMS command
- from a VTAM terminal
When you have satisfied these conditions, IMS acquires an EMH buffer and allocates it for use by the originating terminal for all Fast Path message processing until the session ends. You can specify the size of the EMH buffer but, if the buffer proves too small, EMH will return it to the EMH pool and obtain a larger one.
Message Format Service
The MFS facility can be used in formatting messages to and from terminals. MFS removes device-specific characteristics in input and output messages and eliminates the necessity of tying all screen panel formatting information to the application program. This not only makes the program more device-independent but also makes design and modification of panels easier.
MFS uses four control blocks to separate panel formatting information before a message goes to the application program for processing and to return it to the message when it goes to the terminal for display. The four control blocks are as follows:
Device Input Format: Device input formats (DIFs) describe the formats of messages that MFS
receives from devices.
Message Input Descriptor: Message input descriptors (MIDs) describe how MFS formats messages for the MPP application to process.
Message Output Descriptor: Message output descriptors (MODs) describe the layout of the message as it is sent by the MPP application program.
Device Output Format: DOFs describe how MFS formats the message for the device.
Figure 3-10 illustrates the role of the four control blocks in the routing of messages from terminal to program and back.
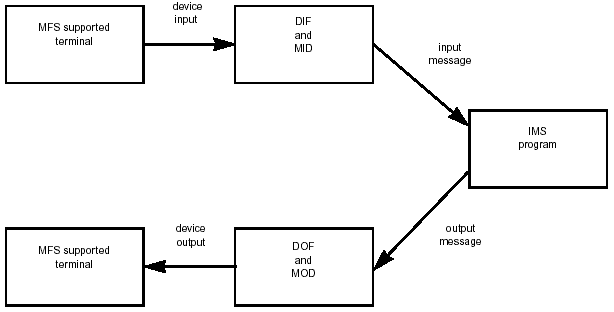
Figure 3-10: Message Reformatting by MFS Control Blocks.
A specific DIF, DOF, MID, and MOD must be defined for each unique message used by an application program. Creating the control blocks can be simplified through the use of SDF II, an interactive tool for use in designing and generating MFS control blocks. SDF II provides a panel editor for you to use in creating and testing panels.
Data Sharing
You can allow more than one IMS online system or batch system to have concurrent access to data stored in a common database. This capability is referred to as data sharing. If you use IMS to control access to the common data, you will be required to use the data sharing support provided by DBRC. See "Share Control" on page 3-41.
The databases that can be accessed by an application program must be defined in the program's PSB. To ensure data integrity, changes to a databases record segment must be fully committed before the segment is released for access by another program. This data integrity protection is provided by IMS lock management.
Lock Management
You can choose one of two methods for controlling access to database segments. A program isolation lock manager can control lock requests for a single IMS system. This is called local locking. An Internal Resources Lock Manager (IRLM) component can control lock requests for multiple IMS systems or a single IMS system. This is called global locking. If you want the dB/DC environment to take part in block-level sharing, you will be required to use IRLM.
When you specify database locking, the entity protected is the database record and the specific item locked is the root segment. (For HDAM databases, the item locked is the anchor point, which means that all records chained from that anchor point are also locked.) Locking occurs when IMS obtains position in the database, and it is held until position is changed to another database record or until a commit occurs. Whether another program can obtain concurrent access to the locked record is determined by the processing option (PROCOPT) defined in the database PCB.
Backup and Recovery
Despite our best efforts and automated procedures, data can sometimes be lost or corrupted because of a variety of causes, including hardware failure, procedural errors, abnormal system termination, or faulty application logic. IMS provides processes that allow data to be recovered to its original state:
- Logging allows IMS to reprocess data from a given point in time.
- Backup utilities create and store valid copies of the database for use in recovery operations.
- Recovery utilities recreate the recovered database.
- DBRC manages the logs and can be used to manage backup, recovery, and data sharing.
Backing up a database is like taking out an insurance policy. If you never need to recover a database, you do not need a backup. However, because most databases are updated and used regularly, they are subject to disasters. If disaster strikes, you need to be prepared to recover from it. A copy of a database, referred to as an image copy, provides a complete backup of the database. When you take an image copy, you create a duplicate of the database as it exists at that moment in time.
After you discover a problem, you must begin the recovery process. The problem may be that IMS or the database validation program found a pointer error. A hardware malfunction may have physically damaged a data set or disabled a disk pack filled with IMS database data sets. Or someone might have discovered a logic error in an IMS application program that has improperly updated several databases.
Whatever the reason, the database must be recovered to its exact state before the failure occurred. Because the database must be taken offline for recovery, it becomes unavailable to IMS users.
You can recover a database to its exact state before the failure occurred, or you can recover it to a particular point in time. In either scenario, you must complete the following steps:
- Apply the most recent image copy or the image copy taken at the time to which you want to recover.
- Apply the changes made after the image copy was taken. These changes may be in logs or change accumulation data sets or both.
- Take an image copy of the recovered database, and verify the pointers. You must have a backup in case you need to recover again in the future, and you must ensure that the recovered database is valid. The following sections describe each of these processes in more detail. Remember that the IMS utilities require you to take the database offline (making it unavailable to users) during some or all of the process, depending on the utilities you choose to use. This unavailability can be a key factor in organizational operations when it affects business-critical applications.
Image Copy
IMS provides two utilities to make copies of a database. The Database Image Copy Utility (DFSUDMP0) creates an as-is image copy of a database. The Online Database Image Copy Utility (DFSUICP0) can be used to create an image copy of a database while it is being updated online. Both utilities operate at the data set level, so if the database consists of multiple data sets or areas, they all must be supplied to the utility. It is generally recommended that you copy all data sets (the entire database) at the same time. The frequency you choose to take image copies depends on the recovery requirements of your organization. You should always create an image copy by using your choice of utilities after a database reorganization, reload, or initial load.
Logging
IMS automatically keeps a running record, a log, of all significant events that occur during processing. The events written to the log include IMS startup and shutdown, program starts and stops, changes to a database, transaction requests received, responses generated and sent, application program checkpoints, and system checkpoints.
The contents of a log record are shown in Figure 3-11.
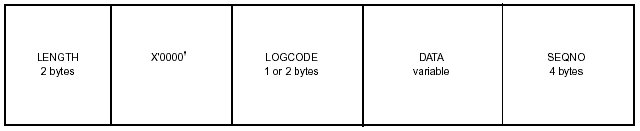
Figure 3-11: Log Record Contents.
The contents of the log record fields are as follows:
LENGTH: The length of the record, including data and sequence number.
LOGCODE: A hexadecimal log code.
DATA: A variable length field to contain the data being logged.
SEQNO: A consecutive sequence number that shows everything was captured as
intended by the log.
Log information is used for processes other than recovery. It is often used for
performance analysis. All log records are kept internal to IMS and can be
stored in one of five types of log data sets:
- online log data set (OLDS)
- write ahead data sets (WADS)
- system log data sets (SLDS)
- recovery log data sets (RLDS)
- restart data set (RDS)
Online Log Data Set
The OLDS collects data from the online environment only. It includes all the log records needed for restart and recovery and for batch and dynamic backout. IMS allows you to specify dual logging, which writes log information on two sets of logs. This provides extra protection in case of damage to one log set. IMS automatically closes the current OLDS and opens a new one when the current OLDS is filled. The filled OLDS is written to the SLDS.
Write Ahead Data Set
WADS contain a copy of committed log records being held in the OLDS buffers before being written to the OLDS. The WADS ensure that log records based on changes to the buffer are logged before a database is changed. If an IMS or system failure occurs, information written to the WADS can be used to complete the content of the OLDS.
System Log Data Set
Logs are archived from the OLDS to the SLDS by the IMS Log Archive utility when the OLDS is full or inactive. Archiving can be automatic or manual. Automatic archiving is usually preferred for large systems with a lot of activity because it eliminates the need to monitor the logging process. You can specify that each OLDS be archived when it is full or that a number of OLDS be filled before archiving. Manual archiving is usually chosen when logging needs to be performed infrequently or at irregular intervals.
Recovery Log Data Set
The RLDS can be created during execution of the Log Archive utility. It contains change records only, which makes it usually much smaller than the OLDS or SLDS. The value of the RLDS in a recovery is that it will process much more quickly.
Restart Data Set
System checkpoint ID information is written to the RDS during logging. This information, stored in the checkpoint ID table, is used during restart to determine a point from which to begin the restart. This data is also stored on the log, but the RDS requires less processing time.
Figure 3-12 shows the relationship of the log data sets.
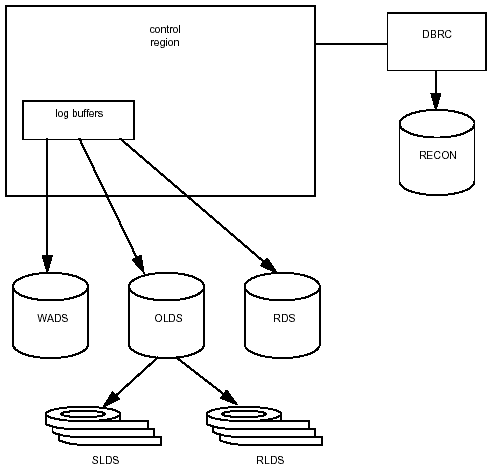
Figure 3-12: Log data set environment.
Log Contents
Table 3-1 lists common log record types and their meanings.
| Log Code | Meaning |
| X'07' | application program terminated |
| X'08' | application program scheduled |
| X'10' | security violation |
| X'20' | database opened |
| X'21' | database closed |
| X'31' | GU issued for message |
| X'41' | basic Checkpoint call issued |
| X'50' | database updated |
| X'52' | ISRT about to be performed |
| X'59' | Fast Path log record |
| X'5F' | DL/I call completed |
Table 3-1: Log Record Types
Change Accumulation
To recover a database by applying log records to an image copy, you must wait while IMS reads and applies each change to every changed segment in the database. You can shorten this procedure significantly if you could skip all the interim changes and read and apply only the most recent change, because that is all you really need to make the database current.
You can consolidate the records in the SLDS and RLDS by running the IMS Change Accumulation utility (or the BMC Software CHANGE ACCUMULATION PLUS product). The Change Accumulation utility reads the log records and summarizes the segment changes. The utility produces a change accumulation data set that includes only the most recent changes organized in sequential order by block number for each data set summarized. Because the change accumulation data set will be much smaller than the log data sets, a database recovery will require much less time.
You can update change accumulation data sets by applying new log records periodically. This creates a new, current change accumulation data set that incorporates any changes since the last change accumulation was done. To perform a recovery, apply the latest change accumulation data set to the most recent image copy of the database, with any log records written since the last change accumulation. Figure 3-13 shows the change accumulation process.
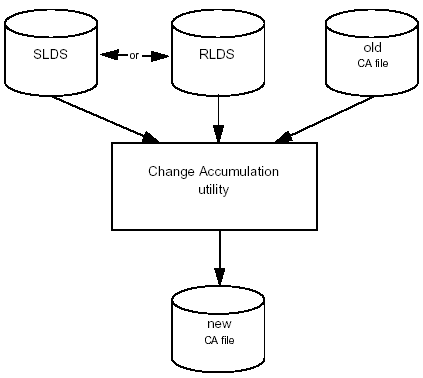
Figure 3-13: Change Accumulation
Commit Points
Although IMS allows multiple application programs to access a database at one time, it allows only one program at a time to update individual segments. While your application has access to a segment, other programs are prevented from accessing the segment until your program has reached a commit point. A commit point is the point in the program processing sequence at which the program has completed a unit of work. IMS issues commit points under the following conditions:
- A program terminates normally. Normal termination always results in a commit point, except that for Fast Path databases a commit point must occur before normal termination.
- A Checkpoint call is issued. A Checkpoint call is a means by which an application program can specifically tell IMS that it has reached a commit point.
- A new input message is retrieved by an MPP processing in single mode. At the commit point, IMS makes the changes to the database permanent and releases the segment for access by other application programs. For example, your program may receive a message to update the data contained in a segment or number of segments located in a database. While the program is retrieving and updating a segment, IMS protects the segment from processing by other programs. When the program completes processing, IMS issues a commit point. Several things happen when the commit point is reached:
- IMS makes the changes to the database permanent.
- IMS releases the segment or segments it has locked since the last commit point.
- The current position in the database (except GSAM) is reset to the beginning of the database.
Checkpoints
Because some programs do not have built-in commit points, IMS provides a means whereby an application program can request a commit point. This is done through a Checkpoint call. A Checkpoint call tells IMS that the program has reached a commit point. A checkpoint provides a point from which the program can be restarted. Checkpoint calls are primarily used in the following programs:
- multiple-mode programs
- batch-oriented BMPs
- batch programs
- programs running in a data sharing environment
Checkpoint calls are not needed in the following programs:
- single-mode programs
- database load programs
- programs that access the database in read-only mode and with PROCOPT=GO that are short enough to be restarted from the beginning
- programs that have exclusive use of the database IMS provides for two types of Checkpoint calls-basic Checkpoint calls and symbolic Checkpoint calls.
Basic check point calls can be used by any type of program, but they are the only type of Checkpoint call allowed for MPPs and IFPs. Basic Checkpoint calls do not support MVS or GSAM files and do not support the Restart call. Symbolic Checkpoint calls can be used by BMPs and batch programs. Symbolic checkpoints allow a program to specify as many as seven data areas to be checkpointed. The Restart call restores these designated areas to the condition they were in when the symbolic Checkpoint call was issued.
A Checkpoint call produces the following results:
- IMS makes the changes to the database permanent.
- IMS releases the segment or segments it has locked since the last commit point.
- The current position in the database (except GSAM) is reset to the beginning of the database.
- IMS writes a log record (containing the checkpoint identification) to the system log.
- IMS sends a message (containing the checkpoint identification) to the system console operator and to the IMS master terminal operator.
- IMS returns the next input message to the program's I/O area.
- If your program also accesses DB2, IMS tells DB2 that the changes your program has made can be made permanent. DB2 makes the changes to the DB2 database permanent.
Backout
IMS will back out changes to a database automatically if a MPP or BMP application program terminates abnormally before reaching a commit point. IMS also performs a backout if an application program issues a Roll backout call (ROLL), Roll Back backout call (ROLB), or Roll Back to SETS (ROLS) call. So that IMS can perform the backout if needed, and so users will not receive information that may prove to be inaccurate, IMS holds output messages until a program reaches a commit point. In an abnormal termination of the program, IMS discards any output messages generated since the last commit point.
If an application program terminates abnormally while processing an input message, IMS may discard the input message, depending on the type of termination. In all cases, IMS backs out uncommitted changes and releases locks on any segments held since the last commit point. You can use DL/I calls to manually back out database updates. The backout calls include
- ROLB
- ROLL
- ROLS
- Set a Backout Point (SETS)
- SET Unconditional (SETU) ROLB, ROLL, and ROLS calls produce three common results:
- All database changes since the last commit are backed out.
- All output messages (except EXPRESS PURG) since the last commit point are discarded.
- All segment locks are released.
ROLB, ROLL, and ROLS calls differ in the following ways:
- ROLB returns control to your program and places the first segment of the first message after the last commit point into the I/O PCB.
- ROLL abends with user code 0778. All messages retrieved since the last commit point are discarded.
- ROLB abends with user code 3303. All messages retrieved since the last commit point are returned to the message queue.
A SETS call can be used to set up to nine intermediate backout points to be used by the ROLS call. It can also be used to cancel all existing backout points. SETS can be combined with a ROLS call to back out pieces of work between the intermediate backout points.
To set the intermediate backout point, issue the SETS call by using the I/O PCB and including an I/O area and a 4-byte token. To back out database changes and message activity that has occurred since a prior SETS call, issue a ROLS call that specifies the token that marks the backout point you have selected. IMS then backs out the database changes made since the SETS token specified. It also discards all non-express messages since the token. A SETU call operates like a SETS call except that it ignores certain conditions under which the SETS call is rejected. A SETS call is not accepted when unsupported PCBs exist in the PSB (PCBs for DEDB, MSDB and GSAM organizations) or an external subsystem is used.
Restart
A Restart call lets you restart a program after an abnormal termination. It must be coded as the first call in the program. When you use the Restart call the following actions occur:
- The last message is returned.
- The database position is reestablished.
- Up to seven specified data areas are returned to their condition at the last checkpoint.
Database Recovery Control
DBRC is a part of IMS that allows easier maintenance and recovery of IMS DL/I databases, including Fast Path DEDBs and databases accessed through CICS. Although originally written to keep track of logs, change accumulation, and other log and tracking information, DBRC now performs a variety of tasks that fall under the general headings of log control, recovery control, and share control. Although it is optional for batch processing, DBRC is required for online transaction processing.
During online processing, DBRC occupies its own MVS address space. IMS communicates with DBRC through the IMS TM control region to supply DBRC with the information it will require to provide the log control, recovery control, or share control services requested. When used in batch processing, or the execution of CICS or IMS utilities, DBRC is loaded as part of the IMS dB code in the batch region.
RECON Data Sets
IMS communication with DBRC is performed through the use of three VSAM KSDS data sets, called Recovery Control (RECON) data sets. The RECON data sets contain all of the recovery information used in recovering registered databases. RECON data sets are used by IMS to record system log and database status information that is used in recovery, image copy, and reorganization operations. RECON data sets are also used in DBRC's control of database sharing and are required for IMS online operation. Because RECON data sets are critical to the functions performed by DBRC, three copies of the data sets are maintained. The primary RECON data set is referred to as RECON1, or Copy1. The second data set is called RECON2, or Copy2. The third is usually referred to as RECON3, or SPARE. The ddnames associated with the RECON data sets are RECON1, RECON2, and RECON3. The RECON data sets may be dynamically allocated by generating MDA members in RESLIB.
RECON data sets contain several types of records, each of which is associated with a particular function of DBRC. A RECON header record is created for each RECON data set to provide information that DBRC uses in managing the system. Other records are created to maintain log control, change accumulation, image copy, database data set, reorganization, and recovery information.
Log Control
DBRC controls the use and availability of OLDS, SLDS, RLDS, and interim log data sets. Information about the logs is stored in a set of RECON data set records called log data set records. If you requested dual logging, they are referred to as PRILOG (the primary log) and SECLOG, (the secondary log). DBRC also creates log allocation (LOGALL) records to identify a database that was changed while its log data set was open.
Figure 3-14 illustrates the relationship between DBRC and the log data sets.
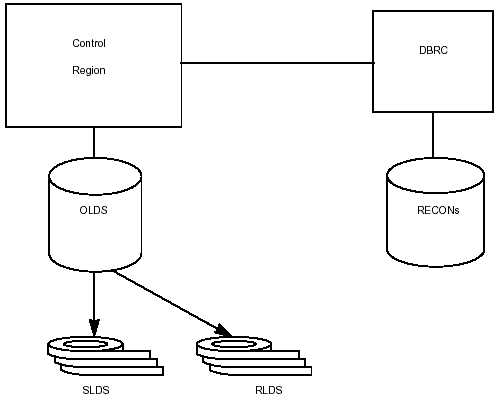
Figure 3-14: DBRC Log Control.
Recovery Control
DBRC controls the recovery of databases by supplying the necessary input for the IMS Recovery utility. To use the recovery control portion of DBRC, you must register your databases with DBRC. Recovery control does not choose the correct utility to be run at the correct time. For example, you must select the correct utility to run in the following circumstances:
- image copy after reorganization
- recovery after database I/O error
- backout after batch failure
- /ERE after online failure
DBRC performs two types of recovery-full recovery and time stamp recovery.
A full recovery means that you have restored all of the database updates that were performed since the image copy was taken. It requires a valid image copy of the database, all log data sets created since the image copy was taken, and any change accumulation data sets.
A time stamp recovery recovers the database to a selected point in time. A time stamp recovery can use any image copy of the database. Then updates (using logs and change accumulation data sets) are applied up to a selected point in time. A time stamp recovery results in an older version of the database. You may need an older version because of application logic that corrupted the most current database. Or the point in time you have selected to recover to may have been the last time the database was valid.
A time stamp recovery is usually used when the database has been corrupted through a processing error such as faulty application logic. A full recovery is most often used when the data has not been corrupted but the database has been lost through something like a hardware or reorganization failure. The data was not corrupted; the database simply crashed.
Share Control
IMS lets you determine the degree to which database records can be shared by application programs or users. When using DBRC in the share control mode, DBRC enforces the share level you have defined. To use DBRC share control, you must register the database to DBRC and define the level of sharing you want. IMS allows four levels of data sharing:
| SHARELEVL 0 | No sharing. The database can be accessed only by the subsystem to which it has been authorized. |
| SHARELEVL 1 | Database-level sharing. The owner subsystem can perform updates, but other subsystems are read only. |
| SHARELEVL 2 | Intra-host block-level sharing. Subsystems executing on the same MVS have full update authority. |
| SHARELEVL 3 | Inter-host block-level sharing. Subsystems operating on the same (or any other) MVS have full update authority. |
Levels 2 and 3 require use of the IRLM. You specify the share level when you register the database with DBRC. Use of share control automatically invokes DBRC log control and recovery control.
Last modified 2005-05-19 11:26 AM