
IMS Concepts and Database Administration
Part 1 in a series (Part 2 | Part 3)
IMS Concepts
This article provides a high-level overview of IMS database concepts, terminology, and database design considerations. It covers the following topics:
Overview
The term database means a collection of related data organized in a way that can be processed by application programs. A database management system (DBMS) consists of a set of licensed programs that define and maintain the structure of the database and provide support for certain types of application programs. The types of database structures are network, relational, and hierarchical. This manual presents information on IMS, a hierarchical database management system from IBM*.
The IMS software environment can be divided into five main parts:
- database
- Data Language I (DL/I)
- DL/I control blocks
- data communications component (IMS TM)
- application programs
Figure 1-1 shows the relationships of the IMS components. We discuss each of these components in greater detail in this and subsequent chapters.
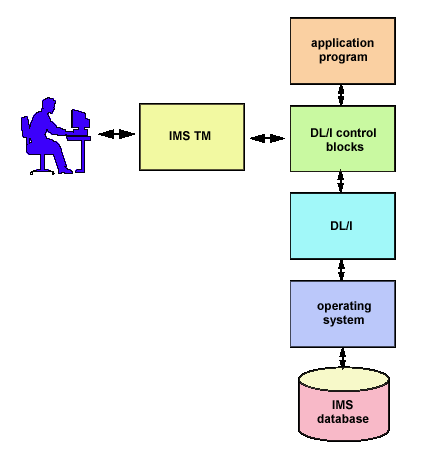
Figure 1-1: IMS environment components.
IMS Database
Before the development of DBMSs, data was stored in individual files, or as flat files. With this system, each file was stored in a separate data set in sequential or indexed format. To retrieve data from the file, an application had to open the file and read through it to the location of the desired data. If the data was scattered through a large number of files, data access required a lot of opening and closing of files, creating additional I/O and processing overhead. To reduce the number of files accessed by an application, programmers often stored the same data in many files. This practice created redundant data and the related problems of ensuring update consistency across multiple files. To ensure data consistency, special cross-file update programs had to be scheduled following the original file update.
The concept of a database system resolved many data integrity and data duplication issues encountered in a file system. A database stores the data only once in one place and makes it available to all application programs and users. At the same time, databases provide security by limiting access to data. The user's ability to read, write, update, insert, or delete data can be restricted. Data can also be backed up and recovered more easily in a single database than in a collection of flat files.
Database structures offer multiple strategies for data retrieval. Application programs can retrieve data sequentially or (with certain access methods) go directly to the desired data, reducing I/O and speeding data retrieval. Finally, an update performed on part of the database is immediately available to other applications. Because the data exists in only one place, data integrity is more easily ensured.
The IMS database management system as it exists today represents the evolution of the hierarchical database over many years of development and improvement. IMS is in use at a large number of business and government installations throughout the world. IMS is recognized for providing excellent performance for a wide variety of applications and for performing well with databases of moderate to very large volumes of data and transactions.
DL/I
Because they are implemented and accessed through use of the Data Language I (DL/I), IMS databases are sometimes referred to as DL/I databases. DL/I is a command-level language, not a database management system. DL/I is used in batch and online programs to access data stored in databases. Application programs use DL/I calls to request data. DL/I then uses system access methods, such as Virtual Storage Access Method (VSAM), to handle the physical transfer of data to and from the database.
IMS databases are often referred to by the access method they are designed for, such as HDAM, PHDAM, HISAM, HIDAM, and PHIDAM. IMS makes provisions for nine types of access methods, and you can design a database for any one of them. We discuss each of them in greater detail in Chapter 2, "IMS Structures and Functions." The point to remember is that they are all IMS databases, even though they are referred to by access type.
Control Blocks
When you create an IMS database, you must define the database structure and how the data can be accessed and used by application programs. These specifications are defined within the parameters provided in two control blocks, also called DL/I control blocks:
- database description (DBD)
- program specification block (PSB)
In general, the DBD describes the physical structure of the database, and the PSB describes the database as it will be seen by a particular application program. The PSB tells the application which parts of the database it can access and the functions it can perform on the data.
Information from the DBD and PSB is merged into a third control block, the application control block (ACB). The ACB is required for online processing but is optional for batch processing.
Data Communications
The IMS Transaction Manager (IMS TM) is a separate set of licensed programs that provide access to the database in an online, real-time environment. Without the TM component, you would be able to process data in the IMS database in a batch mode only. With the IMS TM component, you can access the data and can perform update, delete, and insert functions online. As Figure 1-1 shows, the IMS TM component provides the online communication between the user and DL/I, which, in turn, communicates with the application programs and the operating system to access and process data stored in the database.
Application Programs
The data in a database is of no practical use to you if it sits in the database untouched. Its value comes in its use by application programs in the performance of business or organizational functions. With IMS databases, application programs use DL/I calls embedded in the host language to access the database. IMS supports batch and online application programs. IMS supports programs written in ADA, assembler, C, COBOL, PL/I, VS PASCAL, and REXX.
Hierarchical versus Relational Databases
There are several types of database management systems, categorized generally by how they logically store and retrieve data. The two most common types in use today are relational and hierarchical. Each type has its advantages and disadvantages, and in many organizations both types are used. Whether you choose a relational or hierarchical database management system depends largely on how you intend to use the data being stored.
Relational Database
In a relational database, data is stored in a table made up of rows and columns. A separate table is created for logically related data, and a relational database may consist of hundreds or thousands of tables.
Within a table, each row is a unique entity (or record) and each column is an attribute common to the entities being stored. In the example database described in Table 1-1 on page 1-9, Course No. has been selected as the key for each row. It was chosen because each course number is unique and will be listed only once in the table. Because it is unique for each row, it is chosen as the key field for that row. For each row, a series of columns describe the attributes of each course. The columns include data on title, description, instructor, and department, some of which may not be unique to the course. An instructor, for instance, might teach more than one course, and a department may have any number of courses. It is important early in design of a database to determine what will be the unique, or key, data element.
Hierarchical Databases
Now let's look at the same data stored in a hierarchical format. This time the data is arranged logically in a top-down format. In a hierarchical database, data is grouped in records, which are subdivided into a series of segments. In the example Department database on Figure 1-2 on page 1-8, a record consists of the segments Dept, Course, and Enroll.
In a hierarchical database, the structure of the database is designed to reflect logical dependencies-certain data is dependent on the existence of certain other data. Enrollment is dependent on the existence of a course, and, in this case, a course is dependent on the existence of a department. In a hierarchical database, the data relationships are defined. The rules for queries are highly structured. It is these fixed relationships that give IMS extremely fast access to data when compared to a relational database. Speed of access and query flexibility are factors to consider when selecting a DBMS.
Strengths and Weaknesses
Hierarchical and relational systems have their strengths and weaknesses. The relational structure makes it relatively easy to code requests for data. For that reason, relational databases are frequently used for data searches that may be run only once or a few times and then changed. But the query-like nature of the data request often makes the relational database search through an entire table or series of tables and perform logical comparisons before retrieving the data. This makes searches slower and more processing-intensive. In addition, because the row and column structure must be maintained throughout the database, an entry must be made under each column for every row in every table, even if the entry is only a place holder-a null entry. This requirement places additional storage and processing burdens on the relational system.
With the hierarchical structure, data requests or segment search arguments (SSAs) may be more complex to construct. Once written, however, they can be very efficient, allowing direct retrieval of the data requested. The result is an extremely fast database system that can handle huge volumes of data transactions and large numbers of simultaneous users. Likewise, there is no need to enter place holders where data is not being stored. If a segment occurrence isn't needed, it isn't inserted.
The choice of which type of DBMS to use often revolves around how the data will be used and how quickly it should be processed. In large databases containing millions of rows or segments and high rates of access by users, the difference becomes important. A very active database, for example, may experience 50 million updates in a single day. For this reason, many organizations use relational and hierarchical DBMSs to support their data management goals.
Sample Hierarchical Database
To illustrate how the hierarchical structure looks, we'll design two very simple databases to store information for the courses and students in a college. One database will store information on each department in the college, and the second will contain information on each college student.
In a hierarchical database, an attempt is made to group data in a one-to-many relationship. An attempt is also made to design the database so that data that is logically dependent on other data is stored in segments that are hierarchically dependent on the data. For that reason, we have designated Dept as the key, or root, segment for our record, because the other data would not exist without the existence of a department. We list each department only once. We provide data on each course in each department. We have a segment type Course, with an occurrence of that type of segment for each course in the department. Data on the course title, description, and instructor is stored as fields within the Course segment. Finally, we have added another segment type, Enroll, which will include the student IDs of the students enrolled in each course.
In Figure 1-2, we also created a second database called Student. This database contains information on all the students enrolled in the college. This database duplicates some of the data stored in the Enroll segment of the Department database. Later, we will construct a larger database that eliminates the duplicated data. The design we choose for our database depends on a number of factors; in this case, we will focus on which data we will need to access most frequently,
The two sample databases, Department and Student, are shown in Figure 1-2. The two databases are shown as they might be structured in relational form in Table 1-1, Table 1-2, and Table 1-3 on page 1-9.
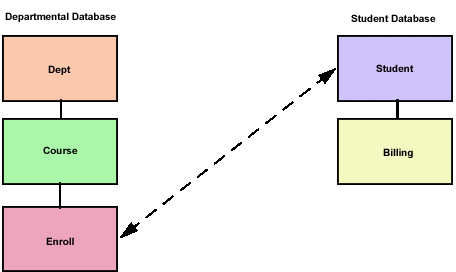
Figure 1-2: Sample hierarchical databases for department and student.
Department Database
The segments in the Department database are as follows:
| Dept | Information on each department. This segment includes fields for the department ID (the key field), department name, chairman's name, number of faculty, and number of students registered in departmental courses. |
| Course | This segment includes fields for the course number (a unique identifier), course title, course description, and instructor's name. |
| Enroll | The students enrolled in the course. This segment includes fields for student ID (the key field), student name, and grade. |
Student Database
The segments in the Student database are as follows:
| Student | Student information. It includes fields for student ID (key field), student name, address, major, and courses completed. |
| Billing | Billing information for courses taken. It includes fields for semester, tuition due, tuition paid, and scholarship funds applied. |
The dotted line between the root (Student) segment of the Student database and the Enroll segment of the Department database represents a logical relationship based on data residing in one segment and needed in the other. Logical relationships are explained in detail in "The Role of Logical Relationships" on page 2-55.
Example Relational Structure
Tables 1-1, 1-2 and 1-3 show how the two hierarchical Department and Student databases might be structured in a relational database management system. We have broken them down into three tables-Course, Student, and Department. Notice that we have had to change the way some data is stored to accommodate the relational format.
| Course No. | Course Title | Description | Instructor | Dept ID |
| HI-445566 | History 321 | Survey course | J. R. Jenkins | HIST |
| MH-778899 | Algebra 301 | Freshman-level | A.L. Watson | MATH |
| BI-112233 | Biology 340 | Advanced course | B.R. Sinclair | BIOL |
Table 1-1: Course database in relational table format.
| Student ID | Student Name | Address | Major |
| 123456777 | Jones, Bill | 1212 N. Main | History |
| 123456888 | Smith, Jill | 225B Baker St | Physics |
| 123456999 | Brown, Joe | 77 Sunset St | Zoology |
Table 1-2: Student database in relational table format.
| Dept ID | Dept. Name | Chairman | Budget Code |
| HIST | History | J. B. Hunt | L72 |
| MATH | Mathematics | R. K. Turner | A54 |
| BIOL | Biology | E. M. Kale | A25 |
Table 1-3: Department database in relational table format.
Design Considerations
Before implementing a hierarchical structure for your database, you should analyze the end user's processing requirements, because they will determine how you structure the database. To help you understand the business processing needs of the user, you can construct a local view consisting of the following:
- list of required data elements
- controlling keys of the data elements
- data groupings for each process, reflecting how the data is used in business practice
- mapping of the data groups that shows their relationships
In particular, you must consider how the data elements are related and how they will be accessed. The topics that follow should help you in that process.
Normalization of Data
Even though you have a collection of data that you want to store in a database, you may have a hard time deciding how the data should be organized. Normalization of data refers to the process of breaking data into affinity groups and defining the most logical, or normal, relationships between them. There are accepted rules for the process of data normalization. Normalization usually is discussed in terms of form. Although there are five levels of normalization form, it is usually considered sufficient to take data to the third normalization form. For most uses, you can think of levels of normalization as the following:
- First normal form. The data in this form is grouped under a primary key-a unique identifier. In other words, the data occurs only once for each key value.
- Second normal form. In this form, you remove any data that was only dependent on part of the key. For example, in Table 1-1 on page 1-9, Dept ID could be part of the key, but the data is really only dependent on the Course No.
- Third normal form. In this form, you remove anything from the table that is not dependent on the primary key. In Table 1-3, the Department table, if we included the name of the University President, it would occur only once for each Dept ID, but it is in no way dependent on Dept ID. So that information is not stored here. The other columns, Dept. Name, Chairman, and Budget Code, are totally dependent on the Dept ID.
Example Database Expanded
At this point we have learned enough about database design to expand our original example database. We decide that we can make better use of our college data by combining the Department and Student databases. Our new College database is shown in Figure 1-3.
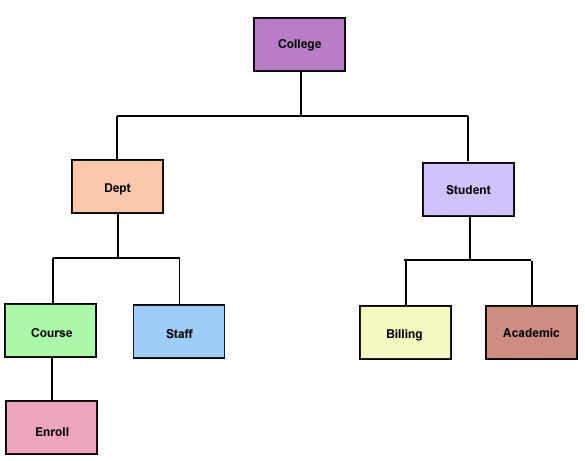
Figure 1-3: College database (combining department and student databases).
The following segments are in the expanded College database:
| College | The root segment. One record will exist for each college in the university. The key field is the College ID, such as ARTS, ENGR, BUSADM, and FINEARTS. |
| Dept | Information on each department within the college. It includes fields for the department ID (the key field), department name, chairman's name, number of faculty, and number of students registered in departmental courses. |
| Course | Includes fields for the course number (the key field), course title, course description, and instructor's name. |
| Enroll | A list of students enrolled in the course. There are fields for student ID (key field), student name, current grade, and number of absences. |
| Staff | A list of staff members, including professors, instructors, teaching assistants, and clerical personnel. The key field is employee number. There are fields for name, address, phone number, office number, and work schedule. |
| Student | Student information. It includes fields for student ID (key field), student name, address, major, and courses being taken currently. |
| Billing | Billing and payment information. It includes fields for billing date (key field), semester, amount billed, amount paid, scholarship funds applied, and scholarship funds available. |
| Academic | The key field is a combination of the year and the semester. Fields include grade point average per semester, cumulative GPA, and enough fields to list courses completed and grades per semester. |
Data Relationships
The process of data normalization helps you break data into naturally associated groupings that can be stored collectively in segments in a hierarchical database. In designing your database, break the individual data elements into groups based on the processing functions they will serve. At the same time, group data based on inherent relationships between data elements.
For example, the College database (Figure 1-3) contains a segment called Student. Certain data is naturally associated with a student, such as student ID number, student name, address, and courses taken, Other data that we will want in our College database-such as a list of courses taught or administrative information on faculty members-would not work well in the Student segment.
Two important data relationship concepts are one-to-many and many-to-many. In the College database, there are many departments for each college (Figure 1-3 shows only one example), but only one college for each department. Likewise, many courses are taught by each department, but a specific course (in this case) can be offered by only one department. The relationship between courses and students is one of many-to-many, as there are many students in any course and each student will take a number of courses. A one-to-many relationship is structured as a dependent relationship in a hierarchical database: the many are dependent upon the one. Without a department, there would be no courses taught: without a college, there would be no departments.
Parent and child relationships are based solely on the relative positions of the segments in the hierarchy, and a segment can be a parent of other segments while serving as the child of a segment above it. In Figure 1-3, Enroll is a child of Course, and Course, although the parent of Enroll, is also the child of Dept. Billing and Academic are both children of Student, which is a child of College. (Technically, all of the segments except College are dependents.)
When you have analyzed the data elements, grouped them into segments, selected a key field for each segment, and designed a database structure, you have completed most of your database design. You may find, however, that the design you have chosen does not work well for every application program. Some programs may need to access a segment by a field other than the one you have chosen as the key. Or another application may need to associate segments that are located in two different databases or hierarchies. IMS has provided two very useful tools that you can use to resolve these data requirements: secondary indexes and logical relationships.
Secondary indexes let you create an index based on a field other than the root segment key field. That field can be used as if it were the key to access segments based on a data element other than the root key. Logical relationships let you relate segments in separate hierarchies and, in effect, create a hierarchic structure that does not actually exist in storage. The logical structure can be processed as if it physically exists, allowing you to create logical hierarchies without creating physical ones. We discuss both of these concepts in greater detail in Chapter 2, "IMS Structures and Functions."
Hierarchical Sequence
Because segments are accessed according to their sequence in the hierarchy, it is important to understand how the hierarchy is arranged. In IMS, segments are stored in a top-down, left-to-right sequence (see Figure 1-4). The sequence flows from the top to the bottom of the leftmost path or leg. When the bottom of that path is reached, the sequence continues at the top of the next leg to the right.
Understanding the sequence of segments within a record is important to understanding movement and position within the hierarchy. Movement can be forward or backward and always follows the hierarchical sequence. Forward means from top to bottom, and backward means bottom to top. Position within the database means the current location at a specific segment.
Hierarchical Data Paths
In Figure 1-4, the numbers inside the segments show the hierarchy as a search path would follow it. The numbers to the left of each segment show the segment types as they would be numbered by type, not occurrence. That is, there may be any number of occurrences of segment type 04, but there will be only one type of segment 04. The segment type is referred to as the segment code.
To retrieve a segment, count every occurrence of every segment type in the path and proceed through the hierarchy according to the rules of navigation:
- top to bottom
- front to back (counting twins)
- left to right
For example, if an application program issues a GET-UNIQUE (GU) call for segment 6 in Figure 1-4, the current position in the hierarchy is immediately following segment 6 (not 06). If the program then issued a GET-NEXT (GN) call, IMS would return segment 7.
As shown in Figure 1-4, the College database can be separated into four search paths:
- The first path includes segment types 01, 02, 03, and 04.
- The second path includes segment types 01, 02, and 05.
- The third path includes segment types 01, 06, and 07.
- The fourth path includes segment types 01, 06, and 08.
The search path always starts at 01, the root segment.

Figure 1-4: Sequence and data paths in a hierarchy.
Database Records
Whereas a database consists of one or more database records, a database record consists of one or more segments. In the College database, a record consists of the root segment College and its dependent segments. It is possible to define a database record as only a root segment. A database can contain only the record structure defined for it, and a database record can contain only the types of segments defined for it.
The term record can also be used to refer to a data set record (or block), which is not the same thing as a database record. IMS uses standard data system management methods to store its databases in data sets. The smallest entity of a data set is also referred to as a record (or block). Two distinctions are important:
- A database record may be stored in several data set blocks.
- A block may contain several whole records or pieces of several records.
In this article, we try to distinguish between database record and data set record where the meaning may be ambiguous.
Segment Format
A segment is the smallest structure of the database in the sense that IMS cannot retrieve data in an amount less than a segment. Segments can be broken down into smaller increments called fields, which can be addressed individually by application programs.
A database record can contain a maximum of 255 types of segments. The number of segment occurrences of any type is limited only by the amount of space you allocate for the database. Segment types can be of fixed length or variable length. You must define the size of each segment type.
It is important to distinguish the difference between segment types and segment occurrences. Course is a type of segment defined in the DBD for the College database. There can be any number of occurrences for the Course segment type. Each occurrence of the Course segment type will be exactly as defined in the DBD. The only differences in occurrences of segment types is the data contained in them (and the length, if the segment is defined as variable length).
Segments consist of two major parts, a prefix and the data being stored. (SHSAM and SHISAM database segments consist only of the data, and GSAM databases have no segments.) The prefix portion of a segment is used to store information that IMS uses in managing the database.
| Prefix | Data | ||||
segment code 1 byte |
delete byte 1 byte |
counters and pointers 4 bytes per element |
size field 2 bytes |
seq. (key) field |
data length varies, based on a minimum and maximum size |
Figure 1-5: Format of a variable-length segment.
Figure 1-6 shows the format of a fixed length segment. In the fixed-length segment, there is no size field.
| Prefix | Data | ||||
segment code 1 byte |
delete byte 1 byte |
counters and pointers 4 bytes per element |
size field 2 bytes |
seq. (key) field |
data length is whatever is specified for the segment |
Figure 1-6: Format of a fixed-length segment.
The fields contained in an IMS database segment are described below. In the data portion, you can define the following types of fields: a sequence field, data fields.
| Segment Code | IMS uses the segment code field to identify each segment type stored in a database. A unique identifier consisting of a number from 1 to 255 is assigned to each segment type when IMS loads the database. Segment types are numbered in ascending sequence, beginning with the root segment as 1 and continuing through all dependent segment types in hierarchic order. |
| Delete Byte | IMS uses this byte to track the status of a deleted segment. The space it occupied may (or may not) be available for use. |
Counters and Pointers
This area exists in hierarchic direct access method (HDAM) and hierarchic indexed direct access method (HIDAM) databases and, in some cases, hierarchic indexed sequential access method (HISAM) databases. It can contain information on the following elements:
- Counters - Counter information is used when logical relationships are defined. Logical relationships are discussed in detail in "The Role of Logical Relationships" on page 2-55.
- Pointers - Pointers consist of one or more addresses of segments pointed to by this segment. Pointers are discussed in detail in "Pointer Types" on page 2-37.
Size Field
For variable-length segments, this field states the size of the segment, including the size field (2 bytes).
Sequence (Key) Field
The sequence field is often referred to as the key field. It can be used to keep occurrences of a segment type in sequence under a common parent, based on the data or value entered in this field. A key field can be defined in the root segment of a HISAM, HDAM, or HIDAM database to give an application program direct access to a specific root segment. A key field can be used in HISAM and HIDAM databases to allow database records to be retrieved sequentially. Key fields are used for logical relationships and secondary indexes.
The key field not only can contain data but also can be used in special ways that help you organize your database. With the key field, you can keep occurrences of a segment type in some kind of key sequence, which you design. For instance, in our example database you might want to store the student records in ascending sequence, based on student ID number. To do this, you define the student ID field as a unique key field. IMS will store the records in ascending numerical order. You could also store them in alphabetical order by defining the name field as a unique key field.
Three factors of key fields are important to remember:
- The data or value in the key field is called the key of the segment.
- The key field can be defined as unique or non-unique.
- You do not have to define a key field in every segment type
Data
You define data fields to contain the actual data being stored in the database. (Remember that the sequence field is a data field.) Data fields, including sequence fields, can be defined to IMS for use by applications programs. Field names are used in SSAs to qualify calls. See "Segment Search Argument" on page 3-22 for more information.
Segment Definitions
In IMS, segments are defined by the order in which they occur and by their relationship with other segments:
| Root segment | The first, or highest segment in the record. There can be only one root segment for each record. There can be many records in a database. |
| Dependent segment | All segments in a database record except the root segment. |
| Parent segment | A segment that has one or more dependent segments beneath it in the hierarchy. |
| Child segment | A segment that is a dependent of another segment above it in the hierarchy. |
| Twin segment | A segment occurrence that exists with one or more segments of the same type under a single parent. |
Segment Edit/Compression
IMS provides a Segment Edit/Compression Facility that lets you encode, edit, or compress the data portion of a segment in full-function or Fast Path DEDB databases. You can use the Edit/Compression Facility to perform the following tasks:
- encode data-make data unreadable to programs that do not have the edit routine to see it in decoded form
- edit data-allow an application program to receive data in a format or sequence other than that in which it is stored
- compress data-use various compression routines, such as removing blanks or repeating characters, to reduce the amount of DASD required to store the data
The Segment Edit/Compression Facility allows two types of data compression:
- data compression-compression that does not change the content or relative position of the key field. For variable-length segments, the size field must be updated to show the length of the compressed segment. For segments defined to the application as fixed-length, a 2-byte field must be added at the beginning of the data portion by the compression routine to allow IMS to determine storage requirements.
- key compression-compression of data within a segment that can change the relative position, value, or length of the key field and any other fields except the size field. In the case of a variable-length segment, the segment size field must be updated by the compression routine to indicate the length of the compressed segment.
Pointers
IMS uses pointers to locate related segments in a database. Pointers are physically stored in the prefix portion of a segment. Each pointer contains the relative byte address (RBA) of another segment. When the database is loaded, IMS creates pointers according to the DBD you specified. During subsequent processing, IMS uses pointers to traverse the database (navigate from segment to segment). IMS automatically maintains the contents of pointers when segments are added, deleted, and updated.
Last modified 2005-05-19 11:26 AM