
eDBA: Online Database Reorganization
The beauty of relational databases is the way they make it easy for us to access and change data. Just issue some simple SQL -- select, insert, update, or delete -- and the DBMS takes care of the actual data navigation and modification. To make this level of abstraction, a lot of complexity is built into the DBMS; it must provide in-depth optimization routines, leverage powerful performance enhancing techniques, and handle the physical placement and movement of data on disk. Theoretically, this makes everyone happy. The programmer's interface is simplified and the DBMS takes care of the hard part -- manipulating the data and coordinating its actual storage. But in reality, things are not quite that simple. The way the DBMS physically manages data can cause performance problems.
Every DBA has experienced a situation in which an application slows down after it has been in production for awhile. But why this happens is not always evident. Perhaps the number of transactions issued has increased or maybe the volume of data has increased. But for some problem, these factors alone will not cause large performance degradation. In fact, the problem might be with disorganized data in the database. Database disorganization occurs when a database's logical and physical storage allocations contain many scattered areas of storage that are too small, not physically contiguous, or too disorganized to be used productively.
To understand how performance can be impacted by database disorganization, let's examine a "sample" database as modifications are made to data. Assume that a tablespace exists that consists of three tables across multiple blocks. As we begin our experiment, each table is contained in contiguous blocks on disk as shown in Figure 1. No table shares a block with any other. Of course, the actual operational specifics will depend on the DBMS being used as well as the type of tablespace, but the scenario is generally applicable to any database at a high level -- the only difference will be in terminology (for example, Oracle block versus DB2 page).

Figure 1: An organized tablespace containing three tables
Now let's make some changes to the tables in this tablespace. First, let's add six rows to the second table. But no free space exists into which these new rows can be stored. How can the rows be added? The DBMS takes another extent into which the new rows can be placed.
For the second change, let's update a row in the first table to change a variable character column; for example, let's change the LASTNAME column from "DOE" to "BEAUCHAMP." This update results in an expanded row size because the value for LASTNAME is longer in the new row: "BEAUCHAMP" consists of 9 characters whereas "DOE" only consists of 3.
Let's make a third change, this time to table three. In this case we are modifying the value of every clustering column such that the DBMS cannot maintain the data in clustering sequence.
After these changes the resultant tablespace most likely will be disorganized (refer to Figure 2). The type of data changes that were made can result in fragmentation, row chaining, and declustering.
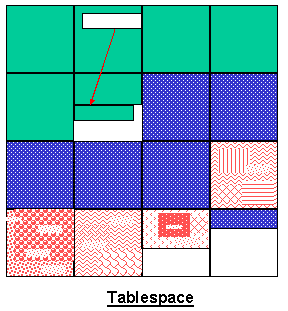
Figure 2: The same tablespace, now disorganized
Fragmentation is a condition in which there are many scattered areas of storage in a database that are too small to be used productively. It results in wasted space, which can hinder performance.
When updated data does not fit in the space it currently occupies, the DBMS must find space for the row using techniques like row chaining and row migration. With row chaining, the DBMS moves a part of the new, larger row to a location within the tablespace where free space exists. With row migrations the full row is placed elsewhere in the segment. In each case a block-resident pointer is used to locate either the rest of the row or the full row. Both row chaining and row migration will result in multiple I/Os being issued to read a single row. This will cause performance to suffer because multiple I/Os are more expensive than a single I/O.
Finally, declustering occurs when there is no room to maintain the order of the data on disk. When clustering is used, a clustering key is specified composed of one or more columns. When data is inserted to the table, the DBMS attempts to insert the data in sequence by the values of the clustering key. If no room is available, the DBMS will insert the data where it can find room. Of course, this declusters the data and that can significantly impact the performance of sequential I/O operations.
Reorganizing Tablespaces
To minimize fragmentation and row chaining, as well as to re-establish clustering, database objects need to be restructured on a regular basis. This process is known as reorganization. The primary benefit is the resulting speed and efficiency of database functions because the data is organized in a more optimal fashion on disk. The net result of reorganization is to make Figure 2 look like Figure 1 again. In short, reorganization is useful for any database because data inevitably becomes disorganized as it is used and modified.
DBAs can reorganize "manually" by completely rebuilding databases. But to conduct a manual reorganization requires a complex series of steps to accomplish, for example:
- Backup the database
- Export the data
- Delete the database object(s)
- Re-create the database object(s)
- Sort the exported data (by the clustering key)
- Import the data
Reorganization usually requires the database to be down. The high cost of downtime creates pressures both to perform and to delay preventive maintenance -- a familiar quandary for DBAs. Third party tools are available that automate the manual process of reorganizing tables, indexes, and entire tablespaces -- eliminating the need for time- and resource-consuming database rebuilds. In addition to automation, this type of tool typically can analyze whether reorganization is needed at all. Furthermore, ISV reorg tools operate at very high speeds to reduce the duration of outages.
Online Reorganization
Modern reorganization tools enable database structures to be reorganized while the data is up and available. To accomplish an online reorganization, the database structures to be reorganized must be copied. Then this "shadow" copy is reorganized. When the shadow reorganization is complete, the reorg tool "catches up" by reading the log to apply any changes that were made during the online reorganization process. Some vendors offer leading-edge technology that enables the reorg to catch up without having to read the log. This is accomplished by caching data modifications as they are made. The reorg can read the cached information much quicker than trying to catch up by reading the log.
Sometimes the reorganization process requires the DBA to create special tables to track and map internal identifiers and pointers as they are changed by the reorg. More sophisticated solutions keep track of such changes internally without requiring these mapping tables to be created.
Running reorganization and maintenance tasks while the database is online enhances availability -- which is the number one goal of the eDBA. The more availability that can be achieved for databases that are hooked up to the Internet, the better the service that your online customers will receive. And that is the name of the game for the web-enabled business.
When evaluating the online capabilities of a reorganization utility, the standard benchmarking goals are not useful. For example, the speed of the utility is not as important because the database remains online while the reorg executes. Instead, the more interesting benchmark is what else can run at the same time. The online reorg should be tested against multiple different types of concurrent workload -- including heavy update jobs where the modifications are both sequential and random. The true benefit of the online reorg should be based on how much concurrent activity can run while the reorg is running -- and still result in a completely reorganized database. Some online reorg products will struggle to operate as the concurrent workload increases -- sometimes requiring the reorg to be cancelled.
Synopsis
Reorganizations can be costly in terms of downtime and computing resources. And it can be difficult to determine when reorganization will actually create performance gains. However, the performance gains that can be accrued are tremendous when fragmentation and disorganization exist. The wise DBA will plan for regular database reorganization based on an examination of the data to determine if the above types of disorganization exist within their corporate databases.
Moreover, if your company relies on databases to service its Web-based customers, you should purchase the most advanced online reorganization tools available because every minute of downtime translates into lost business. An online reorganization product can pay for itself very quickly if you can keep your web-based applications up and running instead of bringing them down every time you need to run a database reorg.
--
Craig Mullins is an independent consultant and president of Mullins Consulting, Inc. Craig has extensive experience in the field of database management having worked as an application developer, a DBA, and an instructor with multiple database management systems including DB2, Sybase, and SQL Server. Craig is also the author of the DB2 Developer’s Guide, the industry-leading book on DB2 for z/OS, and Database Administration: Practices and Procedures, the industry’s only book on heterogeneous DBA procedures. You can contact Craig via his web site at http://www.craigsmullins.com.
Contributors : Craig S. Mullins
Last modified 2006-01-16 06:58 AM