
A Guide to DB2 Locking - Part 2
Welcome back to our discussion of locking in DB2 for z/OS. In this second part of three (adapted from my book, DB2 Developer’s Guide), we will dive into more detailed coverage of DB2 locking.
Let’s start by looking at the different types of locks that DB2 can take. We briefly mentioned the types of locks supported by DB2 in the first part of this article, but here, we offer more in-depth coverage of the topic.
Tablespace Locks
The first type of lock we need to understand is the tablespace lock. A tablespace lock is acquired when a DB2 table or index is accessed. Note that I said accessed, not updated. The tablespace is locked even when simple read-only access is occurring.
Refer to Table 1 for a listing of the types of tablespace locks that can be acquired during the execution of an SQL statement. Every tablespace lock implies two types of access: the access acquired by the lock requester and the access allowed to other subsequent, concurrent processes.
| Lock | Access Meaning | Access Allowed Acquired | to Others |
| S | SHARE | Read only | Read only |
| U | UPDATE | Read with intent to update | Read only |
| X | EXCLUSIVE | Update | No access |
| IS | INTENT SHARE | Read only | Update |
| IX | INTENT EXCLUSIVE | Update | Update |
| SIX | SHARE/INTENT EXCLUSIVE | Read or Update | Read only |
Table 1: Tablespace locks.
When an SQL statement is issued and first accesses data, it takes an intent lock on the tablespace. Later in the process, actual S-, U-, or X-locks are taken. The intent locks (IS, IX, and SIX) enable programs to wait for the required S-, U-, or X-lock that needs to be taken until other processes have released competing locks.
The type of tablespace lock used by DB2 during processing is contingent on several factors, including the tablespace LOCKSIZE specified in the DDL, the bind parameters chosen for the plan being run, and the type of processing requested. Table 2 provides a synopsis of the initial tablespace locks acquired under certain conditions:
| Type of Processing | LOCKSIZE | Isolation | Initial Lock Acquired |
| MODIFY | ANY | CS | IX |
| MODIFY | PAGE/ROW | CS | IX |
| MODIFY | TABLESPACE | CS | X |
| MODIFY | ANY | RR | X |
| MODIFY | PAGE/ROW | RR | X |
| MODIFY | TABLESPACE | RR | X |
| SELECT | ANY | CS | IS |
| SELECT | PAGE/ROW | CS | IS |
| SELECT | TABLESPACE | CS | S |
| SELECT | ANY | RR | S |
| SELECT | PAGE/ROW | RR | S |
| SELECT | TABLESPACE | RR | S |
Table 2: How tablespace locks are acquired.
A tablespace U-lock indicates intent to update, but an update has not occurred. This is caused by using a cursor with the FOR UPDATE OF clause. A U-lock is non-exclusive because it can be taken while tasks have S-locks on the same tablespace. More information on tablespace lock compatibility follows in table 3.
An additional consideration is that tablespace locks are usually taken in combination with table and page locks, but they can be used on their own. When you specify the LOCKSIZE TABLESPACE DDL parameter, tablespace locks alone are used as the locking mechanism for the data in that tablespace. This way, concurrent access is limited and concurrent update processing is eliminated.
Similar in function to the LOCKSIZE DDL parameter is the LOCK TABLE statement. The LOCK TABLE statement requests an immediate lock on the specified table. The LOCK TABLE statement has two forms -- one to request a share lock and one to request an exclusive lock.
LOCK TABLE table_name IN SHARE MODE; LOCK TABLE table_name IN EXCLUSIVE MODE;
Caution: The LOCK TABLE statement locks all tables in a simple tablespace even though only one table is specified.
A locking scheme is not effective unless multiple processes can secure different types of locks on the same resource concurrently. With DB2 locking, some types of tablespace locks can be acquired concurrently by discrete processes. Two locks that can be acquired concurrently on the same resource are said to be compatible with one another.
Refer to table 3 for a breakdown of DB2 tablespace lock compatibility. A “Yes” in the matrix indicates that the two locks are compatible and can be acquired by distinct processes on the same tablespace concurrently. A “No” indicates that the two locks are incompatible. In general, two locks cannot be taken concurrently if they allow concurrent processes to negatively affect the integrity of data in the tablespace.
| Locks for PGM2 | Locks for | PGM1 | ||||
| S | U | X | IS | IX | SIX | |
| S | Yes | Yes | No | Yes | No | No |
| U | Yes | No | No | Yes | No | No |
| X | No | No | No | No | No | No |
| IS | Yes | Yes | No | Yes | Yes | Yes |
| IX | No | No | No | Yes | Yes | No |
| SIX | No | No | No | Yes | No | No |
| LOCKSIZE Parameter | Options |
Table 3: Tablespace lock compatibility matrix.
Let’s back up a moment and examine the LOCKSIZE parameter. The LOCKSIZE parameter is specified when we create a tablespace using CREATE TABLESPACE. It indicates the type of locking DB2 will perform for the given tablespace. The choices are:
| ROW | Row-level locking |
| PAGE | Page-level locking |
| TABLE | Table-level locking (for segmented tablespaces only) |
| TABLESPACE | Tablespace-level locking |
| LOB | LOB locking; valid only for LOB tablespaces |
| ANY | Lets DB2 decide, starting with PAGE |
A reasonable strategy for locking would be to implement LOCKSIZE ANY, except in the following circumstances:
- A read-only table defined in a single tablespace can be specified as LOCKSIZE TABLESPACE. There rarely is a reason to update the table, so page locks can be avoided.
- A table that does not require shared access should be placed in a single tablespace specified as LOCKSIZE TABLESPACE. Shared access refers to multiple users (or jobs) accessing the table simultaneously.
- A grouping of tables in a segmented tablespace used by a single user (for example, a QMF user) can be specified as LOCKSIZE TABLE. If only one user can access the tables, there is no logical reason to take page-level locks.
- Specify LOCKSIZE PAGE for production systems that cannot tolerate a lock escalation, but for which row locking would be overkill. When many accesses are made consistently to the same data, you must maximize concurrency. If lock escalation can occur (that is, a change from page locks to tablespace locks), concurrency is eliminated. If a particular production system always must support concurrent access, use LOCKSIZE PAGE and set the LOCKMAX parameter for the tablespace to 0.
- For LOB tablespaces, always specify LOCKSIZE LOB.
- Consider specifying LOCKSIZE ROW only when concurrency is of paramount importance. When multiple updates must occur to the same page at absolutely the same time, LOCKSIZE ROW may prove to be beneficial. But row locking can cause performance problems because a row lock requires about the same amount of resources as a page lock. And, because there are usually multiple rows on a page, row locking will typically consume more resources. Do not implement LOCKSIZE ROW, though, unless you are experiencing a locking problem with page locking. Often, at design time, developers believe multiple transactions will be updating the same page simultaneously, but it is not very commonplace in practice. An alternative to LOCKSIZE ROW is LOCKSIZE PAGE with MAXROWS 1, which will achieve the same purpose by forcing one row per page.
Consider using LOCKSIZE ANY in situations other than those just outlined because it allows DB2 to determine the optimal locking strategy based on actual access patterns. Locking begins with PAGE locks and escalates to TABLE or TABLESPACE locks when too many page locks are being held. The LOCKMAX parameter (covered next) controls escalation. LOCKSIZE ANY generally provides an efficient locking pattern because it allows the DBMS to actively monitor and manage the locking strategy.
LOCKMAX Parameter Options
The LOCKMAX parameter specifies the maximum number of page or row locks that any one process can hold at any one time for the tablespace. When the threshold is reached, the page or row locks are escalated to a table or tablespace lock. Three options are available for setting the LOCKMAX parameter:
- The literal SYSTEM can be specified, indicating that LOCKMAX should default to the system-wide value as specified in DSNZPARMs.
- The value 0 can be specified, indicating that lock escalation should never occur for this tablespace.
- An integer value ranging from 1 to 2,147,483,647 can be specified, indicating the actual number of row or page locks to tolerate before lock escalation.
Table Locks
DB2 can use table locks only when segmented tablespaces are involved in the process. Table locks are always associated with a corresponding tablespace lock.
The same types of locks are used for table locks as are used for tablespace locks. S, U, X, IS, IX, and SIX table locks can be acquired by DB2 processes when data in segmented tablespaces is accessed. Table 23.1 describes the options available to DB2 for table locking. The compatibility chart in table 3 applies to table locks as well as tablespace locks.
For a table lock to be acquired, an IS-lock must first be acquired on the segmented tablespace in which the table exists. The type of table lock to be taken depends on the LOCKSIZE specified in the DDL, the bind parameters chosen for the plan being run, and the type of processing requested. Table 4 is a modified version of table 2, showing the initial types of tablespaces and table locks acquired given a certain set of conditions. Table locks are not acquired when the LOCKSIZE TABLESPACE parameter is used.
| Type of Processing | LOCKSIZE | Isolation | Tablespace Lock Acquired | TableLock Acquired |
| MODIFY | ANY | CS | IS | IX |
| MODIFY | PAGE | CS | IS | IX |
| MODIFY | TABLE | CS | IS | X |
| MODIFY | ANY | RR | IS | X |
| MODIFY | PAGE | RR | IS | X |
| MODIFY | TABLE | RR | IS | X |
| SELECT | ANY | CS | IS | IS |
| SELECT | PAGE | CS | IS | IS |
| SELECT | TABLE | CS | IS | S |
| SELECT | ANY | RR | IS | S |
| SELECT | PAGE | RR | IS | S |
| SELECT | TABLE | RR | IS | S |
Table 4. How table locks are acquired
Page Locks
The types of page locks that DB2 can take are outlined in table 5. With S-locks, data can be read concurrently, but not modified. With an X-lock, data on a page can be modified (with INSERT, UPDATE, or DELETE), but concurrent access is not allowed. U-locks enable X-locks to be queued, whereas S-locks exist on data that must be modified.
| Lock | Meaning | Access Acquired | Access Allowed to Others |
| S | SHARE | Read only | Read only |
| U | UPDATE | Read with intent to update | Read only |
| X | EXCLUSIVE | Update | No access |
Table 5: Page locks.
As with tablespace locks, concurrent page locks can be acquired, but only with compatible page locks. The compatibility matrix for page locks is shown in table 6.
| Locks for PGM2 | Locks for | PGM1 | |
| S | U | X | |
| S | Yes | Yes | No |
| U | Yes | No | No |
| X | No | No | No |
Table 6: Page lock compatibility matrix.
When are these page locks taken? Page locks are acquired under the following conditions:
- The DDL for the object requesting a lock specifies LOCKSIZE PAGE or LOCKSIZE ANY.
- If LOCKSIZE ANY was specified, the NUMLKTS threshold or the tablespace LOCKMAX specification must not have been exceeded (more on those later).
- If ISOLATION(RR) was used when the plan was bound, the optimizer might decide not to use page locking.
If all these factors are met, page locking progresses as outlined in table 7. The type of processing in the left column causes the indicated page lock to be acquired for the scope of pages identified in the right column. DB2 holds each page lock until it is released, as specified in the ISOLATION level of the plan requesting the particular lock.
Note: Page locks can be promoted from one type of lock to another based on the type of processing that is occurring. A program can FETCH a row using a cursor with the FOR UPDATE OF clause, causing a U-lock to be acquired on that row’s page. Later, the program can modify that row, causing the U-lock to be promoted to an X-lock.
| Type of Processing | Page Lock | AcquiredPages Affected |
| SELECT/FETCH | S | Page by page as they are fetched |
| OPEN CURSOR for SELECT | S | All pages affected |
| SELECT/FETCH FOR UPDATE OF | U | Page by page as they are fetched |
| UPDATE | X | Page by page |
| INSERT | X | Page by page |
| DELETE | X | Page by page |
| Row Locks |
Table 7: How page locks are acquired.
The smallest piece of DB2 data that you can lock is the individual row. The types of row locks that DB2 can take are similar to the types of page locks that it can take. (Refer to table 8.) With S-locks, data can be read concurrently, but not modified. With an X-lock, you can modify data in that row (using INSERT, UPDATE, or DELETE), but concurrent access is not allowed. U-locks enable X-locks to be queued, whereas S-locks exist on data that must be modified.
| Lock | Meaning | Access Acquired | Access Allowed to Others |
| S | SHARE | Read only | Read only |
| U | UPDATE | Read with intent to update | Read only |
| X | EXCLUSIVE | Update | No access |
Table 8: Row locks.
Once again, concurrent row locks can be acquired, but only with compatible row locks. Table 9 shows the compatibility matrix for row locks:
| Locks for PGM2 | Locks for | PGM1 | |
| S | U | X | |
| S | Yes | Yes | No |
| U | Yes | No | No |
| X | No | No | No |
Table 9: Row lock compatibility matrix.
When are these row locks taken? Row locks can be acquired when the DDL for the object requesting a lock specifies LOCKSIZE ROW. (Although it is theoretically possible for LOCKSIZE ANY to choose row locks, in practice I have yet to see this happen.) Row locking progresses as outlined in table 10. The type of processing in the left column causes the indicated row lock to be acquired for the scope of rows identified in the right column. A row lock is held until it is released as specified by the ISOLATION level of the plan requesting the particular lock.
| Type of Processing | Row Lock Acquired | Rows Affected |
| SELECT/FETCH | S | Row by row as they are fetched |
| OPEN CURSOR for SELECT | S | All rows affected |
| SELECT/FETCH FOR UPDATE OF | U | Row by row as they are fetched |
| UPDATE | X | Row by row |
| INSERT | X | Row by row |
| DELETE | X | Row by row |
Table 10: How row locks are acquired.
Page Locks Versus Row Locks
The answer to the question of whether to use page locks or row locks is, of course, “It depends!” The nature of your specific data and applications determine whether page, or row, locks are most applicable.
The resources required to acquire, maintain, and release a row lock are just about the same as the resources required for a page lock. Therefore, the number of rows per page must be factored into the row-versus-page locking decision. The more rows per page, the more resources row locking will consume. For example, a tablespace with a single table that houses 25 rows per page can consume as much as 25 times more resources for locking if row locks are chosen over page locks. Of course, this estimate is very rough, and other factors (such as lock avoidance) can reduce the number of locks acquired, and thereby reduce the overhead associated with row locking.
But row locking almost always consumes more resources than page locking. On the other hand, locking a row at a time instead of a page at a time can reduce contention. If two applications running concurrently access the same data in different orders, row locking might actually decrease concurrent data access.
You must therefore ask these questions:
- What is the nature of the applications that access the objects in question? Of course, the answer to this question differs not only from organization to organization, but also from application to application within the same organization.
- Which is more important, reducing the resources required to execute an application, or increasing data availability? The answer to this question will depend upon the priorities set by your organization and any application teams accessing the data.
As a general rule of thumb, favor specifying LOCKSIZE PAGE, as page locking is generally the most practical locking strategy for most applications. If you’re experiencing severe contention problems on a tablespace that is currently using LOCKSIZE PAGE, consider changing to LOCKSIZE ROW and gauging the impact on performance, resource consumption, and concurrent data access. Alternately, you might choose to specify LOCKSIZE ANY, and let DB2 choose the type of locking to be performed.
Keep in mind, too, that a possible alternative to row locking is to specify MAXROWS 1 for the tablespace and use LOCKSIZE PAGE (or LOCKSIZE ANY), instead of LOCKSIZE ROW. Doing so will cause only one row to exist on any one tablespace page. The downside is that you most likely will be wasting space on each page.
Partition Independence
To fully understand DB2 locking, you also need to understand claims and drains. DB2 augments resource serialization using claims and drains in addition to transaction locking. The claim and drain process enables DB2 to perform concurrent operations on multiple partitions of the same tablespace.
Claims and drains provide another “locking” mechanism to control concurrency for resources between SQL statements, utilities, and commands. Do not confuse the issue: DB2 continues to use transaction locking, as well as claims and drains.
As with transaction locks, claims and drains can time out while waiting for a resource.
Claims
DB2 uses a claim to register that a resource is being accessed. The following resources can be claimed:
- Simple tablespaces
- Segmented tablespaces
- A single data partition of a partitioned tablespace
- A non-partitioned index space
- A single index partition of a partitioned index (of either the partitioning index or a DPSI)
Think of claims as usage indicators. A process stakes a claim on a resource, telling DB2, in effect, “Hey, I’m using this!”
Claims prevent drains from acquiring a resource. A claim is acquired when a resource is first accessed. This is true regardless of the ACQUIRE parameter specified (USE or ALLOCATE). Claims are released at commit time, except for cursors declared using the WITH HOLD clause or when the claimer is a utility.
Multiple agents can claim a single resource. Claims on objects are acquired by the following:
- SQL statements (SELECT, INSERT, UPDATE, DELETE)
- DB2 restart on INDOUBT objects
- Some utilities (for example, COPY SHRLEVEL CHANGE, RUNSTATS SHRLEVEL CHANGE, and REPORT)
Every claim has a claim class associated with it. The claim class is based on the type of access being requested, as follows:
- A CS claim is acquired when data is read from a package or plan bound specifying ISOLATION(CS).
- An RR claim is acquired when data is read from a package or plan bound specifying ISOLATION(RR).
- A write claim is acquired when data is deleted, inserted, or updated.
Drains
Like claims, drains also are acquired when a resource is first accessed. A drain acquires a resource by making quiescent claims against that resource. Drains can be requested by commands and utilities.
Multiple drainers can access a single resource. However, a process that drains all claim classes cannot drain an object concurrently with any other process.
To more fully understand the concept of draining, think back to the last time that you went to a movie theater. Before anyone is permitted into the movie, the prior attendees must first be cleared out. In essence, this example illustrates the concept of draining. DB2 drains make sure that all other users of a resource are cleared out before allowing any subsequent access.
The following resources can be drained:
- Simple tablespaces
- Segmented tablespaces
- A single data partition of a partitioned tablespace
- A non-partitioned index space
- A single index partition of a partitioned index (of either the partitioning index or a DPSI)
A drain places drain locks on a resource. A drain lock is acquired for each claim class that must be released. Drain locks prohibit processes from attempting to drain the same object at the same time.
The process of quiescing a claim class and prohibiting new claims from being acquired for the resource is called draining. Draining allows DB2 utilities and commands to acquire partial or full control of a specific object with a minimal impact on concurrent access.
Three types of drain locks can be acquired:
- A cursor stability drain lock
- A repeatable read drain lock
- A write drain lock
A drain requires either partial control of a resource, in which case a write drain lock is taken, or complete control of a resource, accomplished by placing a CS drain lock, an RR drain lock, and a write drain lock on an object.
You can think of drains as the mechanism for telling new claimers, “Hey, you can’t use this in that way!” The specific action being prevented by the drain is based on the claim class being drained. Draining write claims enables concurrent access to the resource, but the resource cannot be modified. Draining read (CS and/or RR) and write claims prevents any and all concurrent access.
Drain locks are released when the utility or command completes. When the resource has been drained of all appropriate claim classes, the drainer acquires sole access to the resource.
Claim and Drain Lock Compatibility
As with transaction locks, concurrent claims and drains can be taken, but only if they are compatible with one another. Table 11 shows which drains are compatible with existing claims; and table 12 shows which drains are compatible with existing drains.
| Existing Claim for PGM2 | Drain required by | PGM1 | |
| Write | CS | RR | |
| Write | No | No | No |
| RR | Yes | No | No |
| CS | Yes | No | No |
Table 11: Claim/Drain compatibility matrix.
| Existing Drain for PGM2 | Drain required | by PGM1 | |
| Write | CS | RR | |
| Write | Yes | No | No |
| RR | No | No | No |
| CS | No | No | No |
Table 12: Drain/Drain compatibility matrix.
Transaction Locking Versus Claims and Drains
DB2 uses transaction locks to serialize access to a resource between multiple claimers, such as two SQL statements or an SQL statement and a utility that takes claims, such as RUNSTATS SHRLEVEL(CHANGE).
Claims and drains serialize access between a claimer and a drainer. For example, an INSERT statement is a claimer that must be dealt with by the LOAD utility, which is a drainer.
Drain locks are used to control concurrency when both a command and a utility try to access the same resource.
Lock Avoidance
Lock avoidance is a mechanism employed by DB2 to access data without locking while maintaining data integrity. It prohibits access to uncommitted data and serializes access to pages. Lock avoidance improves performance by reducing the overall volume of lock requests. Let’s face it, the most efficient lock is the one never taken.
In general, DB2 avoids locking data pages if it can determine that the data to be accessed is committed and that no semantics are violated by not acquiring the lock. DB2 avoids locks by examining the log to verify the committed state of the data.
When determining if lock avoidance techniques will be practical, DB2 first scans the page to be accessed to determine whether any rows qualify. If none qualify, a lock is not required.
For each data page to be accessed, the RBA of the last page update (stored in the data page header) is compared with the log RBA for the oldest active unit of recovery. This RBA is called the Commit Log Sequence Number, or CLSN. If the CLSN is greater than the last page update RBA, the data on the page has been committed and the page lock can be avoided.
Additionally, a bit is stored in the record header for each row on the page. The bit is called the Possibly UNCommitted, or PUNC, bit. (Refer to figure 4.) The PUNC bit indicates whether update activity has been performed on the row. For each qualifying row on the page, the PUNC bit is checked to see whether it is off. This indicates that the row has not been updated since the last time the bit was turned off. Therefore, locking can be avoided.
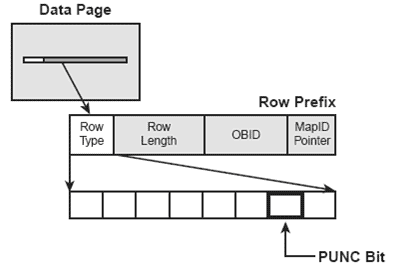
Figure 4: The PUNC bit.
Note: IBM provides no external method for you to determine whether the PUNC bit is on or off for each row. Therefore, you should ensure that any table that can be modified should be reorganized on a regularly scheduled basis.
If neither CLSN nor PUNC bit testing indicates that a lock can be avoided, DB2 acquires the requisite lock.
In addition to enhancing performance, lock avoidance increases data availability. Data that in previous releases would have been considered locked, and therefore unavailable, is now considered accessible.
When Lock Avoidance Can Occur
Lock avoidance can be used only for data pages. Further, DB2 Catalog and DB2 Directory access does not use lock avoidance techniques. You can avoid locks under the following circumstances:
- For any pages accessed by read-only or ambiguous queries bound with ISOLATION(CS) and CURRENTDATA NO
- For any unqualified rows accessed by queries bound with ISOLATION(CS) or ISOLATION(RS)
- When DB2 system-managed referential integrity checks for dependent rows caused by either the primary key being updated, or the parent row being deleted and the DELETE RESTRICT rule is in effect
- For both COPY and RUNSTATS when SHRLEVEL(CHANGE) is specified
Summary
In this second part of a three part article, we extended our understanding of DB2 locking by examining the types of locks, claims and drains, and lock avoidance. In the final installment of this series we will take a look at locking in a data sharing environment and finally provide some tips and guidelines for implementing efficient locking strategies.
--
Craig Mullins is an independent consultant and president of Mullins Consulting, Inc. Craig has extensive experience in the field of database management having worked as an application developer, a DBA, and an instructor with multiple database management systems including DB2, Sybase, and SQL Server. Craig is also the author of the DB2 Developer’s Guide, the industry-leading book on DB2 for z/OS, and Database Administration: Practices and Procedures, the industry’s only book on heterogeneous DBA procedures. You can contact Craig via his web site at http://www.craigsmullins.com.
Contributors : Craig S. Mullins
Last modified 2006-04-03 12:17 PM