
A Guide to DB2 Locking – Part 1
As with any reliable DBMS, DB2 automatically guarantees the integrity of data it manages by enforcing locking strategies. These strategies permit multiple users from multiple environments to access and modify data concurrently. DB2 deploys the following techniques to implement an overall locking strategy:
- Table and tablespace locking
- IRLM page and row locking
- Internal page and row latching
- Claims and drains to achieve partition independence
- Checking commit log sequence numbers (CLSN) and PUNC bits to achieve lock avoidance
- Global locking through the coupling facility in a data sharing environment
What exactly is locking? How does DB2 utilize these strategies to lock pages and guarantee data integrity? Why does DB2 have to lock data before it can process it? What is the difference between a lock and a latch? How can DB2 provide data integrity while operating on separate partitions concurrently? Finally, how can DB2 avoid locks and still guarantee data integrity?
In this three-part article series (adapted from my book, DB2 Developer’s Guide), I will attempt to answer these questions. In addition, this series of articles will offer practical information on lock compatibilities that can aid you in program development, scheduling, and management.
How DB2 Manages Locking
Anyone accustomed to application programming when access to a database is required understands the potential for concurrency problems. When one application program tries to read data that is in the process of being changed by another, the DBMS must forbid access until the modification is complete to ensure data integrity. Most DBMS products, DB2 included, use a locking mechanism for all data items being changed. Therefore, when one task is updating data on a page, another task cannot access data (read or update) on that same page until the data modification is complete and committed.
When multiple users can access and update the same data at the same time, a locking mechanism is required. This mechanism must be capable of differentiating between stable data and uncertain data. Stable data has been successfully committed and is not involved in being modified in a current unit of work. Uncertain data is currently involved in an operation that could modify its contents. Consider the example in the following listing:
Program #1 Timeline Program #2 .
. T1 .
. .
. .
. .
SQL statement T2 .
accessing EMPNO '000010' .
. .
. .
SQL statement T3 .
updating '000010' .
. .
. .
. T4 SQL statement
. accessing EMPNO '000010'
. .
. .
Commit T5 .
. .
. .
. .
. T6 SQL statement
. updating '000010'
. .
. .
. .
. T7 Commit
If program #1 updates a piece of data on page 1, you must ensure that program #2 cannot access the data until program #1 commits the unit of work. Otherwise, a loss of integrity could result. Without a locking mechanism, the following sequence of events would be possible:
- Program #1 retrieves a row from DSN8810.EMP for EMPNO '000010'.
- Program #1 issues an update statement to change that employee’s salary to 55000.
- Program #2 retrieves the DSN8810.EMP row for EMPNO '000010'. Because the change was not committed, the old value for the salary, 52750, is retrieved.
- Program #1 commits the change, causing the salary to be 55000.
- Program #2 changes a value in a different column and commits the change.
- The value for salary is now back to 52750, negating the change made by program #1.
DB2 avoids this situation through the use of locking. DB2 supports locking at four levels, or granularities:
- tablespace,
- table,
- page, and
- row-level locking.
DB2 also provides LOB locking for large objects (BLOBs, CLOBs, and DBCLOBs). The hierarchy guiding how DB2 locks are enacted is shown in figure 1.
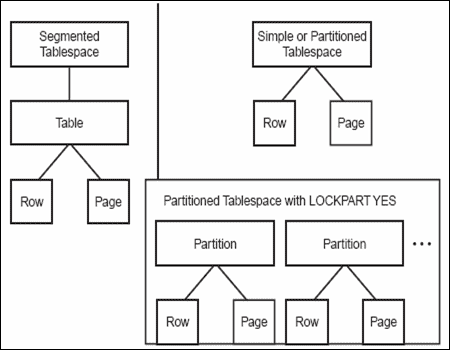
Figure 1: The DB2 locking hierarchy.
Locks can be taken at any level in the locking hierarchy without taking a lock at the lower level. However, locks cannot be taken at the lower levels without a compatible higher-level lock also being taken. For example, you can take a tablespace lock without taking any other lock, but you cannot take a page lock without first securing a tablespace-level lock (and a table lock as well if the page is part of a table in a segmented tablespace containing more than one table).
Additionally, as illustrated in the diagram, a page lock does not have to be taken before a row lock is taken. Your locking strategy requires an “either/or” type of choice by tablespace: either row locking or page locking. We will review an in-depth discussion on the merits of both later in this article.
Both page locks and row locks escalate to a table level and then to a tablespace level for segmented tables or straight to a tablespace level for simple or partitioned tablespaces. A table or tablespace cannot have both page locks and row locks held against it at the same time.
Many modes of locking are supported by DB2, but they can be divided into two types:
- Locks to enable the reading of data
- Locks to enable the updating of data
But this overview is quite simplistic; DB2 uses varieties of these two types to indicate the type of locking required. We will cover them in more depth later.
Locks Versus Latches
A true lock is handled by DB2 using the IRLM. However, whenever doing so is practical, DB2 tries to lock pages without going to the IRLM. This type of lock is called a latch.
In other words, true locks are always set in the IRLM. Latches, by contrast, are set internally by DB2, without going to the IRLM.
When a latch is taken instead of a lock, it is handled in the Buffer Manager by internal DB2 code; so the cross-memory service calls to the IRLM are eliminated. Latches are usually held for a shorter duration than locks. Also, a latch requires about one-third the number of instructions as a lock. Therefore, latches are more efficient than locks because they avoid the overhead associated with calling an external address space. Latches are used when a resource serialization situation is required for a short time. Both latches and locks guarantee data integrity. In subsequent sections, when I use the term lock generically, I am referring to both locks and latches.
Lock Duration
Before we learn about the various types of locks that can be acquired by DB2, you should understand lock duration, which refers to the length of time that a lock is maintained.
The duration of a lock is based on the BIND options chosen for the program requesting locks. Locks can be acquired either immediately when the plan is requested to be run or iteratively as needed during the execution of the program. Locks can be released when the plan is terminated or when they are no longer required for a unit of work.
Let’s review the BIND parameters that affect DB2 locking:
Bind Parameters Affecting Tablespace Locks
ACQUIRE(ALLOCATE) versus ACQUIRE(USE): The ALLOCATE option specifies that locks will be acquired when the program is allocated, which normally occurs when the first SQL statement is issued. The USE option indicates that locks will be acquired only as they are required, SQL statement by SQL statement.
RELEASE(DEALLOCATE) versus RELEASE(COMMIT): When you specify DEALLOCATE for a program, locks are not released until the program is terminated. When you specify COMMIT, tablespace locks are released when a COMMIT is issued.
Bind Parameters Affecting Page and Row Locks
ISOLATION level (CS, RR, RS, UR): There are four choices for isolation level.
- ISOLATION(CS), or Cursor Stability, acquires and releases page locks as pages are read and processed. CS provides the greatest level of concurrency at the expense of potentially different data being returned by the same cursor if it is processed twice during the same unit of work.
- ISOLATION(RR), or Repeatable Read, holds page and row locks until a COMMIT point; no other program can modify the data. If data is accessed twice during the unit of work, the same exact data will be returned.
- ISOLATION(RS), or Read Stability, holds page and row locks until a COMMIT point, but other programs can INSERT new data. If data is accessed twice during the unit of work, new rows may be returned, but old rows will not have changed.
- ISOLATION(UR), or Uncommitted Read, is also known as dirty read processing. UR avoids locking altogether, so data can be read that never actually exists in the database.
Regardless of the ISOLATION level chosen, all page locks are released when a COMMIT is encountered.
A Few Words on Dirty Reads
Programs that read DB2 data typically access numerous rows during their execution and are thus quite susceptible to concurrency problems. Dirty reads, also known as read-through locks, can help to overcome concurrency problems. When using uncommitted reads, an application program can read data that has been changed but is not yet committed.
How does “dirty read” impact data availability and integrity? Consider the following sequence of events:
- At 9:00 a.m., a transaction is executed containing the following SQL to change a specific value:
UPDATE DSN8810.EMP
The transaction, which is a long-running one, continues to execute without issuing a COMMIT.
SET FIRSTNME = "MICHELLE"
WHERE EMPNO = '010020'; - At 9:01 a.m., a second transaction attempts to SELECT the data that was changed but not committed.
If the UR isolation level were specified for the second transaction, it would read the changed data even though it had yet to be committed. Obviously, if the program does not wait to take a lock and merely reads the data in whatever state it happens to be at that moment, the program will execute faster than if it has to wait for locks to be taken and resources to be freed before processing.
However, you must carefully examine the implications of reading uncommitted data before implementing such a plan. Several types of “problems” can occur. A dirty read can cause duplicate rows to be returned where none exist. Also, a dirty read can cause no rows to be returned when one (or more) actually exists. Obviously, you must take these “problems” into consideration before using the UR isolation level.
Keep in mind that the UR isolation level applies to read-only operations: SELECT, SELECT INTO, and FETCH from a read-only result table. Any application plan or package bound with an isolation level of UR uses uncommitted read functionality for read-only SQL. Operations that are contained in the same plan or package that are not read-only use an isolation level of CS.
You can override the isolation level that is defined at the plan or package level for each SQL statement in the program by using the WITH clause, as shown in the following SQL:
SELECT EMPNO, FIRSTNME, LASTNAME
FROM DSN8810.EMP
WITH UR;
The WITH clause allows an isolation level to be specified at the statement level in an application program. However, the restriction that the UR isolation level can be used with read-only SQL statements alone still applies.
OK, then, you are probably asking “when is using UR isolation appropriate?” The general rule of thumb is to avoid UR whenever the results must be 100 percent accurate. Examples would be when
- Calculations that must balance are performed on the selected data
- Data is retrieved from one source to insert into or update another
- Production, mission-critical work that cannot contain or cause data-integrity problems is performed
In general, most current DB2 applications are not candidates for dirty reads. However, in a few specific situations, the dirty read capability can be a major benefit. Consider the following cases in which the UR isolation level could prove to be useful:
- Access is required to a reference, code, or lookup table that is basically static in nature. Due to the non-volatile nature of the data, a dirty read would be no different than a normal read the majority of the time. In the cases in which the code data is being modified, any application reading the data would incur minimum, if any, problems.
- Statistical processing must be performed on a large amount of data. For example, your company may want to determine the average age of female employees within a certain pay range. The impact of an uncommitted read on an average of multiple rows is minimal because a single value changed usually does not have a significant impact on the result.
- Dirty reads can prove invaluable in a DB2 data warehousing environment. A data warehouse is a time-sensitive, subject-oriented store of business data that is used for online analytical processing. Refer to Chapter 45, “Data Warehousing with DB2,” for more information on DB2 data warehouses. Other than periodic data propagation and/or replication, access to a data warehouse is read only. An uncommitted read is perfect in a read-only environment because it can cause little damage because the data is generally not changing. More and more data warehouse projects are being implemented in corporations worldwide, and DB2 with dirty read capability can be a wise choice for data warehouse implementation.
- In the rare cases in which a table, or set of tables, is used by a single user only, UR can make a lot of sense. If only one individual can modify the data, the application programs can be coded so that all (or most) reads are done using UR isolation level, and the data will still be accurate.
- Dirty reads can be useful in pseudo-conversational transactions that use the save-and-compare technique. A program using the save-and-compare technique saves data for later comparison to ensure that the data was not changed by other concurrent transactions.
Consider the following sequence of events: transaction 1 changes customer A on page 100. A page lock will be taken on all rows on page 100. Transaction 2 requests customer C, which is on page 100. Transaction 2 must wait for transaction 1 to finish. This wait is not necessary. Even if these transactions are trying to get the same row, the save then compare technique would catch this.
- Finally, if the data being accessed is already inconsistent, little harm can be done by using a dirty read to access the information.
Lock Suspensions, Timeouts, and Deadlocks
So, what happens if a lock is being held on a piece of data that your program needs to access? Well, DB2 manages this and depending on the exact circumstances will inform you by means of a SQLCODE or SQLSTATE that you cannot access the data as you desire. Let’s examine this in a little more detail.
The longer a lock is held, the greater the potential impact to other applications. When an application requests a lock that is already held by another process, and the lock cannot be shared, that application is suspended. A suspended process temporarily stops running until the lock can be acquired. Lock suspensions can be a significant barrier to acceptable performance and application availability.
When an application has been suspended for a pre-determined period of time, it will be terminated. When a process is terminated because it exceeds this period of time, it is said to timeout. In other words, a timeout is caused by the unavailability of a given resource. For example, consider the following scenario:

If Program 2, holding no other competitive locks, requests a lock currently held by Program 1, DB2 tries to obtain the lock for a period of time. Then it quits trying. This example illustrates a timeout. This timeout scenario is also applicable to row locks, not just page locks.
The length of time a user waits for an unavailable resource before being timed out is determined by the IRLMRWT DSNZPARM parameter. You also can set this period of time by using the RESOURCE TIMEOUT field on the DB2 installation panel DSNTIPI.
When a lock is requested, a series of operations is performed to ensure that the requested lock can be acquired (refer to figure 2). Two conditions can cause the lock acquisition request to fail: a deadlock or a timeout.
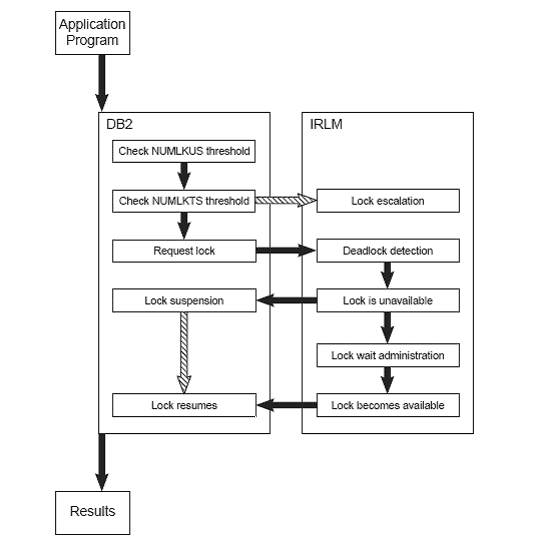
Figure 2: Processing a lock request.
A deadlock occurs when two separate processes compete for resources held by one another. DB2 performs deadlock detection for both locks and latches. For example, consider the following processing sequence for two concurrently executing application programs:

A deadlock occurs when Program 1 requests a lock for a data page held by Program 2, and Program 2 requests a lock for a data page held by Program 1. A deadlock must be resolved before either program can perform subsequent processing. DB2’s solution is to target one of the two programs as the victim of the deadlock and deny that program’s lock request by setting the SQLCODE to -911. This deadlocking scenario is also applicable to row locks, not just page locks. A graphic depiction of a deadlock is shown in figure 3.
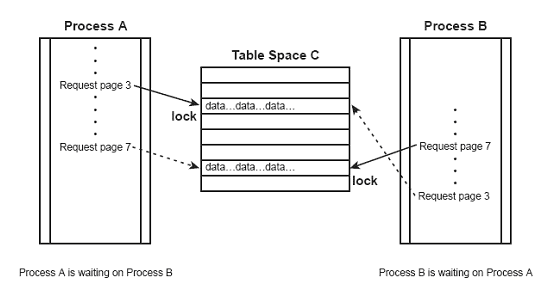
Figure 3: A deadlock.
The length of time DB2 waits before choosing a victim of a deadlock is determined by the DEADLOK IRLM parameter. You also can set this parameter using the RESOURCE TIMEOUT field on the DB2 installation panel DSNTIPJ.
Summary
In the first part of this article, we examined the high-level basics of DB2 for z/OS locking, including the reason a DBMS needs a locking mechanism, locks versus latches, the BIND parameters that impact locking, and the impact on your programs. In the next installment of this series, we will take a look at the types of locks, lock compatibility, and lock suspensions, timeouts, and deadlocks. In the final part of this three-part article we will examine some additional details on locking including partition independence, lock avoidance and locking in a data sharing context – as well as offer a compendium of guidelines and suggestions for implementing efficient applications in terms of DB2 locking.
--
Craig Mullins is an independent consultant and president of Mullins Consulting, Inc. Craig has extensive experience in the field of database management having worked as an application developer, a DBA, and an instructor with multiple database management systems including DB2, Sybase, and SQL Server. Craig is also the author of the DB2 Developer’s Guide, the industry-leading book on DB2 for z/OS, and Database Administration: Practices and Procedures, the industry’s only book on heterogeneous DBA procedures. You can contact Craig via his web site at http://www.craigsmullins.com.
Contributors : Craig S. Mullins
Last modified 2006-04-03 12:17 PM