
Availability with Clicks of a Button Using DB2’s HADR
The IBM® DB2® Universal Database™ for Linux®, UNIX®, and Windows® (DB2 UDB) Version 8.2 release became available in September 2004. This release is packed with all sorts of features such as CLR stored procedures (yes, you read that right — since early September 2004) and advanced self-managing capabilities such as a backup utility that throttles itself and can run after a certain number of transactions have completed. Yet the most talked-about feature is the new high-availability disaster recovery (HADR) technology. In this article, we’ll talk about HADR and some of the benefits that it can deliver to enterprises that seek simplicity, ease of scalability for OLTP applications, and the highest levels of availability.
The Thought Behind High-availability Disaster Recovery
The HADR technology has its heritage in the Informix® High-Availability Data Replication (HDR) technology, which has been around for many years. In fact, the Informix HDR technology is used to run most of the 911 emergency call centers in North America, so if they can rely on it — and you know that you want them to choose the best availability technology around — it seems like a good basis for the HADR technology.
After IBM acquired Informix, the DB2 product development team worked with the development team of HDR to engineer a new generation of this availability technology. The result: HADR (no matter how good is a finished product, most of us would go back and make changes, if we could).
With this knowledge, the DB2 development team set out to engineer HADR. The basis of HADR lies in the following design goals:
- Ultra-fast failover with the option for zero transaction loss
- Easy setup and administration
- Negligible impact on performance
- Software upgrades without interruption
- Automatic failover for applications
The HADR solution had to provide ultra-fast failover. Other technologies today (for example, database clustering) typically require longer recovery times. In contrast, HADR supports CRM, ERP, SCM, and custom applications “out of the box,” and is applicable to all sorts of applications. The goal for HADR was to deliver sub-minute failover. In fact, some customers are now reporting results with failover in as little as three seconds.
Aside from minimizing the mean-time-to-repair (MTTR) of a database outage, the HADR solution had to be simple to set up. HADR can be set up with mere clicks of a button, or the manual setting of five simple database configuration parameters.
Human error is the number one cause of downtime in today’s technology infrastructure. In fact, the mean-time-between-failure (MTBF) of hardware systems can be expressed in centuries, while the MTBF for humans is very short. Quite simply, the more complex is a solution, the greater the likelihood that human error will lead to its outage.
Since the cornerstone of HADR is availability, the systems involved in the HADR pair have to perform well, too. After all, the measurement of availability isn’t just if the database server is “alive” and processing transactions. If your clients come to your Web site and have to wait two minutes to process their shopping cart for order completion, they’re likely to go to a competitor’s site. And if you’re a DBA who’s tied to a stringent service-level agreement that dictates query response times to the marketing division at three seconds, then 3.5 seconds is an unavailable machine. With this in mind, the architecture behind HADR had to ensure that the performance impact of the HADR software would be negligible.
Outages aren’t just downed computers and slow running machines. To minimize outages, planned downtime has to be minimized as well. Since the DB2 UDB V8.1 release, multiple features were added to minimize planned downtime: throttlable utilities, online table and index reorganizations, dynamic configuration parameters, dynamic resource allocation (CPU and memory) to LPARs, online tablespace loads, and more. HADR takes availability to a new level by giving DBAs the ability to upgrade their software without taking an outage. (This doesn’t just apply to DB2 UDB — for example, you can apply operating system patches.)
Availability characteristics have to be extended to the client as well. If an outage occurs, how do you reroute the client to the back-up node? While different vendors have different methods of addressing this, the HADR solution keeps the holds to the “simplicity” approach by delivering automatic client rerouting for applications using any supported DB2 UDB high-availability strategy — HADR, Q-Replication, or database clustering — in a simple one-place, one-step configuration.
How High Availability Disaster Recovery Works
The easiest way to think about HADR is to think log shipping — only this time, it’s highly efficient as transactions are shipped from memory rather than log files.
The problem with log shipping was that you could always be out the number of transactions in the log file. For performance reasons, you typically create larger log files, which means more transactions in the log being shipped, and more transactions being lost in the event of a failure.
HADR starts with two machines — a primary server and a standby server. The primary server processes transactions and ships log entries to the standby server, while the standby server (which starts as a clone of the primary via a snapshot, flash copy, or restore from backup) receives log entries from the primary and reapplies the transactions on the standby.
If the primary server fails, the standby can take over the transactional workload in seconds as the standby becomes the new primary server. If the failed machine becomes available again, it can be automatically reintegrated back into the HADR pair, and the old primary server becomes the new standby server.
The following illustrates the HADR architecture:
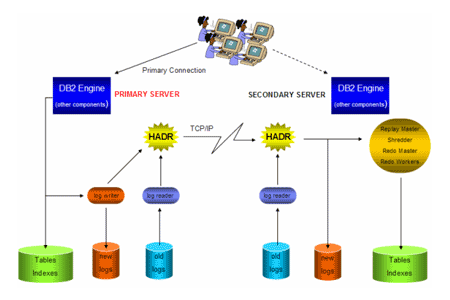
Figure 1: HADR architecture.
As transactions run against the database, they are “replayed” on the standby server. The log buffer entries are streamed across the network wire (using any TPC/IP network connection), shredded, and run on the standby.
You define the synchronization mode when setting up an HADR solution. HADR supports three synchronization modes: asynchronous, near-synchronous, and synchronous, shown as follows:
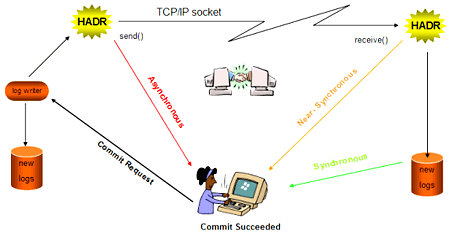
Figure 2: HADR’s three supported synchronization modes.
Note: It’s not only a COMMIT operation that flushes the log buffer; there are parameters and other operations that affect the timeliness of a log flush, too. But for simplicity, the following explanations assume that only a COMMIT will flush the log buffer.
In synchronous mode, when the client application requests a COMMIT operation, the database manager will not return a successful return code until the log buffer containing the transaction has been sent to the standby server, replayed, and hardened to disk. With this setting, you are guaranteed never to lose a transaction — ever.
On the opposite end of the spectrum is asynchronous mode. In this mode, a COMMIT operation completes when a send() socket call is made to the wire protocol. The transaction is put into the wire with little consideration after that point. If data is lost on the wire or something happens to the primary or standby servers while the transaction is being streamed, you could lose transactions. In fact, you could lose more than just a single transaction, since multiple transactions could be flowing across the wire, or being processed on the standby server when an outage in the topology occurs.
In between these two settings is near-synchronous, which is the mode that we recommend to most customers when deploying an HADR solution. (In fact, it’s the default setting for HADR.) In this mode, a successful return code is not given to the client application until the log buffer (which contains the transaction) is flowed across the wire and that buffer is in memory on the standby server. In this case, you could potentially lose the transactions in a log buffer in the rare instance of experiencing simultaneous failure of both the primary and standby servers and then choosing to start up the standby server as your new primary.
Setting up HADR
One of the main goals in designing the HADR was to enable quick and easy setup of an HADR environment. DB2 UDB V8.2 provides the Configure HADR Databases wizard to set up the primary and standby servers for HADR. This wizard helps you perform the following tasks, which are required to set up an HADR environment:
- Identify the two machines that will serve as the HADR pair.
- Prepare the primary database for log shipping.
- Perform a database backup to create a restore point for the standby server.
- Copy the backup image from the primary server to the standby server.
- Perform the restore action on the selected standby database.
- Move any database objects not included in the backup image.
- Update the service files for TCP/IP communication on both servers.
- Update HADR-related configuration parameters on both databases.
- Provide an option to start HADR.
The following shows one of the panels from this wizard:
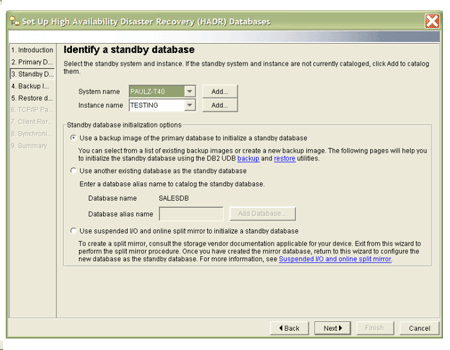
Figure 3: One panel from the Configure HADR Databases wizard.
If you’re a DBA of the command-line persuasion, you can still easily set up HADR using commands or scripts. In fact, we can fit the instructions for setup in one-fifth of a page:

Figure 4: Instructions for setting up HADR.
To manually set up HADR, you need to perform three simple steps to have a high-availability cluster:
1. Clone the primary database to the standby server
The first step is to make a copy of the database on the standby server. You can do this simply enough by taking a backup of the primary (online if needed) and restoring that backup image of the primary database on the standby server. Then, you’ll have two servers with exact copies of the same database. Note, however, that the primary server might have processed transactions during the restore operation, and, therefore, would be further ahead than the standby server (we’ll cover that later in the article).
2. Update five configuration parameters on each server
Before you start HADR, you need to let DB2 UDB know where the primary and standby servers are on the network. To do this, update the required HADR database configuration parameters as follows:
HADR_LOCAL_HOST |
the host name of the local server |
HADR_REMOTE_HOST |
the host name of the peer in the HADR cluster |
HADR_LOCAL_SVC |
the port number on which the server listens for HADR communications |
HADR_REMOTE_SVE |
the port number on which the peer listens for HADR communications |
HADR_REMOTE_INST |
the instance name of the peer server |
Whether you set up HADR via the wizard or the CLP, you need to set these parameters. Setting these parameters neither enables HADR on a database nor indicates whether a database is a primary or standby server. This separation allows DBAs to disable HADR with ease without losing the HADR configuration.
There are two other optional parameters that you can use for HADR. The first is the timeout value, which tells DB2 UDB for how long the primary server should wait if it cannot contact the standby server before it begins to ignore the standby server. Although it’s beyond the scope of the article to go into this in detail, it’s important to note that a failure of the standby server or the network does not cause a failure on the primary server.
The second optional parameter is called SYNCMODE. This parameter can take on one of three values:
- SYNC means the that two servers will stay completely in sync down to the last COMMIT operation, so you are guaranteed never to lose a transaction.
- NEARSYNC means that you will never lose a transaction unless both the primary and standby servers fail simultaneously and you then start up the standby as the primary.
- ASYNC means that log buffers are sent asynchronously to the standby server every time a transaction commits, which has less impact on the production server.
3. Start HADR on the standby and primary servers
At this point, you have two servers, each have a copy of the same database, and you have specified how each server can talk to each other (over TPC/IP). All that is left to do is start HADR. You start HADR on the standby server with the following command (use spaces to indent these code lines and not the arrow “indent” button)
db2 start HADR on database PROD as STANDBY
This causes the standby server to contact the primary server and “catch up” with the transactions it missed while it was down. The standby server will tell the primary server where it is located in the log file and will pull over any log files that have been created since the backup was created to catch itself up to the current active log.
The next step is to start HADR on the primary server with the following command to get the two databases in peer state:
db2 start HADR on database PROD as PRIMARY
That’s it! Going forward, any time the log buffer is flushed to disk on the primary server (because the log buffer is full or because some transaction is committed), the log buffer that contains the transaction is sent to the standby server and applied to keep it synchronized.
Once HADR is set up, you can manage its operations using the CLP or a wizard.
Performing a Takeover
HADR has two forms of takeover. The first is sometimes called a normal takeover or a switch roles takeover. In this form, the primary database becomes the standby, and the standby database turns into the primary. This can be extremely useful for performing maintenance such as applying patches (covered later in the article in more detail). To perform the takeover in this manner, simply log on to the standby server and run the following command:
db2 TAKEOVER HADR ON DATABASE <db_name>
The standby server will contact the primary server to tell it to turn itself into a standby server. Then, the primary server will flush its last log buffer and force off any in-flight transactions. These transactions will be switched over to the new primary server, which is the old standby server. The new primary server will then receive the final log buffer and open itself up for new transactions.
In the event of a failure on the primary server, one simple command turns the standby server into the primary server:
db2 TAKEOVER HADR ON DATABASE <db_name> BY FORCE
Using the BY FORCE option tells DB2 UDB not to coordinate the switching of roles (since the primary server is not available to talk to, anyway). In this mode, the standby server becomes the primary database and begins to accept new transactions from end-user applications.
When the old primary database comes back online, simply start HADR on that server as a standby. This will cause the failed database to contact the new primary server and resynchronize itself into a peer state with it. This reintegration is guaranteed if you are using the synchronous mode, and is possible (as long as no transactions were lost) using the near-synchronous and asynchronous modes.
Monitoring HADR
DB2 UDB provides many mechanisms by which you can monitor HADR. For example, DBAs can use SQL to retrieve information about the status of HADR. The following shows an example of some HADR-specific output from the GET DATABASE SNAPSHOT command:
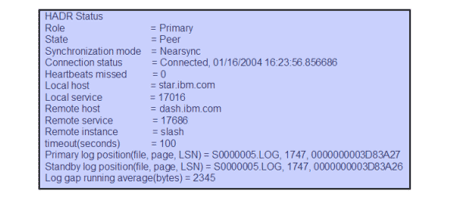
Figure 5: HADR-specific output from the GET DATABASE SNAPSHOT command.
You can see in the previous example that the State of the two servers is Peer. Peer state means that the two servers are synchronized and that the log buffers are shipped directly from the primary to the standby server when flushed.
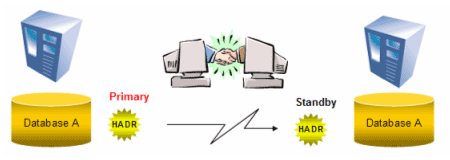
Figure 6: The two servers are synchronized and the log buffers are shipped directly from the primary to the standby server when flushed.
Other states can indicate that the standby is catching up to the primary server, and so on.
The Connection status of the HADR pair is also returned in the database snapshot output. In this case, you can see whether two servers are connected and the time when they were connected. The connection status could also show that the two servers were disconnected or congested.
Other information includes Heartbeats missed (a key indicator if something on the wire is causing a problem for HADR), Log gap running average (which could identify network latency or if the standby server can’t keep up for some reason), and more.
Automatic Failover for Applications with Automatic Client Reroute
Automatic Client Reroute (ACR) is another feature that was first introduced in the DB2 UDB V8.2 release.
ACR isn’t tied to HADR technology; it can be used with HADR, clustering software, in a partitioned database environment, with replication, and so on. ACR provides a method by which applications can be automatically and transparently reconnected to the standby server without the application or end user being exposed to a communications error. While it’s out of the scope of this article to cover all the details of ACR, the architecture behind it follows the theme of “simplicity” implicit in the HADR design goals.
For the ACR feature, identify an alternate server to which you could connect if the primary database becomes unavailable in the server’s configuration (1) shown in figure 7. Whenever a DB2 UDB client (2) makes a successful connection to the primary database server (3), the alternate server information is returned to the client and stored there (4). In the event of a failure (5), once the ACR technology has verified that the primary database has indeed experienced an outage, the connection is transferred to the alternate server (6).
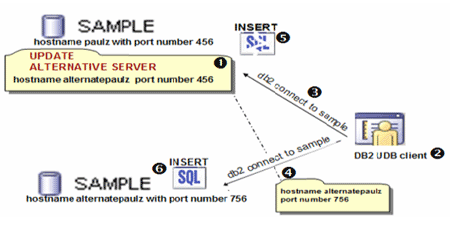
Figure 7: Alternate server to which you could connect if the primary database becomes unavailable in the server’s configuration.
That’s how ACR works. All you have to do to set up ACR is run one command on the server to specify the hostname and port number of the standby server — that’s it! No tinkering on the client end is needed.
Software Upgrades on the Fly
As we mentioned earlier, availability is more than just a server that’s responding to client requests. One aspect of availability lies under planned maintenance. This involves database and non-database specific tasks. You can use HADR to apply maintenance to your software or hardware without taking the database down. For example, you might want to apply a Fix Pack to DB2 UDB, a service pack to your operating system, or swap out some hardware components.
With HADR, you can take the standby server “down,” apply maintenance, and bring it back online. HADR will then automatically resynchronize the standby and catch up to the primary by applying the transactions it missed during the maintenance period. Once peer state is achieved, simply perform a switch roles takeover, then take the new standby down, apply the patch, and have HADR resynchronize itself with the new primary server. An example is shown in figure 8. The Web surfer represents the database that client applications connect to in order to process their transactions.
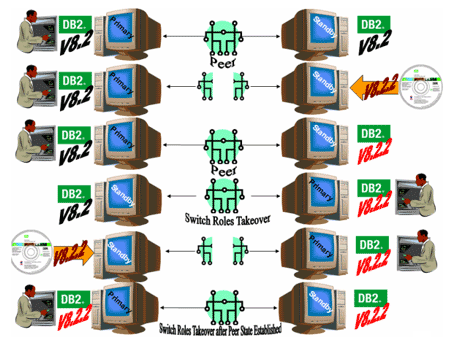
Figure 8: Taking the primary server down for maintenance, then bringing it back online.
The Benefits of HADR
So now that you understand the technology behind HADR, what are the benefits?
First, this kind of solution provides total protection and disaster recovery for your entire solution stack. What if a failure occured at the disk, or at the disk controller, or in the SAN or in the coupling software provided to run a cluster? For example, DBAs typically protect their databases from corruption using some sort of RAID configuration, but if a disk arm writes a corrupt page to disk, that error is replicated in a RAID scenario. HADR provides total protection of the entire stack at a highly competitive cost.
HADR doesn’t require the disk takeover time at failover that makes typical clustering solutions take so long to recover from a failure. This feature leads to very fast failover times. How fast? Running an SAP workload with 600 simulated SAP users, DB2 UDB demonstrated that it could fail over database transactions to the standby server in 11 seconds — eight seconds of which was the timeout period configured for the detection of the server failure (to avoid false failovers). In other words, DB2 UDB was able to failover in just three seconds.
HADR is able to fail over the workload so quickly because, despite what the name “standby” implies, DB2 UDB isn’t just standing around waiting for something bad to happen. In fact, it’s doing quite the opposite — it is busy at work ensuring that the MTTR is minimal, and that your buffer pools are primed with the data pages it expects to fetch in response to your resubmitted applications after a failure occurs.
How so? All of the update transactions that are shipped across the wire require DB2 UDB on the standby server to retrieve the corresponding data and index pages into the buffer pool. This greatly reduces restart recovery time on the standby server in the event of a failure because the memory structures are “hot” with the most recent updates.
In addition, consider what happens when most users experience an outage (which would be exposed to them on a Web application as Retry or Cancel buttons). Typically, users resubmit the same transactions. Or perhaps the application is well written to automatically retry a transaction upon failure — and that primed buffer pool on the standby is likely ready to service those same requests from memory — without disk I/O to retrieve the data pages, since they are likely in the buffer pool for recovery.
It’s worth spending a little more time on this standby misnomer. In addition to the previous point that HADR is busy at work making your environment primed for takeover, HADR takes place at the database level, so you can set up an active/active type scenario in which each server is performing work for the database server in the HADR pair, as shown in figure 9:
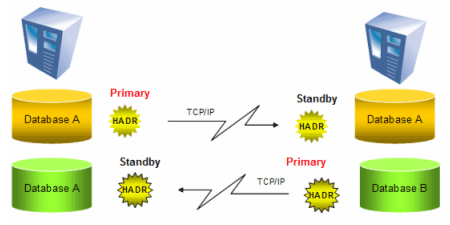
Figure 9: Active/active type scenario in which each server is performing work for the database server in the HADR pair.
Many clients ask us for a readable standby database. Before diving into this subject at great length, (which is out of the scope of this article), we ask them to list their priorities for their solution. For example, many vendors’ solutions don’t allow the database to be in roll-forward mode and readable at the same time. To support a readable standby, the recovery operations on these standby machines are frozen until an outage occurs. That isn’t availability. Solutions for reading an HADR standby database include creating a snapshot of the database using software from other vendors, creating a disk mirror of the primary system, or leveraging the DB2 UDB replication technologies. Just remember that the goal of HADR is availability.
What’s more, in the event of a failure, clients still experience the same performance with HADR that they experienced before the outage. In an active/active environment, performance would drop by roughly 50 percent in a two-node cluster. Some clients might choose to “over-configure” their servers to accommodate this, which only creates idle capacity on both servers, already in a hybrid standby mode. It’s interesting to note that some application vendors state in their documentation that if their software is deployed on a cluster for some specific databases, one of the nodes must be idle.
The bottom line is that HADR only limits activity on the HADR standby database — that’s it. There is nothing to prevent you from using the standby server for other DB2 UDB and non-DB2 UDB activities, as another HADR pair, for Q and A, for reporting from a snapshot database, and more. It’s outside the scope of this article to go into these details, but you should always start with the question, “what does availability mean to you?”
Wrapping It Up
As you can see, HADR is a powerful, yet incredibly simple, solution that you can leverage in DB2 UDB to follow even the most stringent SLA availability requirements. It’s available for all editions of DB2 UDB, requires only a single processor license for the standby machine, allows for reintegration, provides well beyond sub-minute failover, and more.
Want to learn more about the HADR technology? Stay tuned for a podcast in which we’ll talk about this technology in more depth, and answer any questions you have after reading this article.
--
Chris Eaton is a Senior Product Manager for DB2 Universal Database at IBM, primarily focused on planning and strategy for DB2 UDB. Chris has been working with DB2 on the Linux, UNIX, and Windows platforms for over 13 years. From customer support to development manager of the DB2 Control Center team to Externals Architect and now as Product Manager for DB2 UDB, Chris has spent his career listening to customers and working to make DB2 software better. Chris is also the author of The High Availability Guide for DB2, available from Prentice Hall.
Paul C. Zikopoulos, BA, MBA, is an award-winning writer and speaker with the IBM Database Competitive Technologies team. He has more than nine years of experience with DB2 products and has written numerous magazine articles and books about it. Paul has co-authored the books DB2 Version 8: The Official Guide, DB2: The Complete Reference, DB2 Fundamentals Certification for Dummies, DB2 for Dummies, and A DBA’s Guide to Databases on Linux. Paul is a DB2 Certified Advanced Technical Expert (DRDA and Cluster/EEE) and a DB2 Certified Solutions Expert (Business Intelligence and Database Administration). Currently he is writing a book on the Apache Derby/IBM Derby database. You can reach him at paulz_ibm@msn.com
Trademarks
IBM, DB2, DB2 Universal Database, and Informix are trademarks of International Business Machines Corporation in the United States, other countries, or both.
Windows is a trademark of Microsoft Corporation in the United States, other countries, or both.
UNIX is a trademark of The Open Group in the United States, other countries, or both.
Linux is a trademark of Linus Torvalds in the United States, other countries, or both.
Other company, product, and service names may be trademarks or service marks of others.
Disclaimer
The opinions, solutions, and advice in this article are from the authors’ experiences and are not intended to represent official communication from IBM or an endorsement of any products listed within. Neither the authors nor IBM are liable for any of the contents in this article. The accuracy of the information in this article is based on the authors’ knowledge at the time of writing.
Contributors : Paul C. Zikopoulos, Chris Eaton
Last modified 2006-11-28 04:13 PM