
ETL for the “Unstructured” Data Mart
A Guide to This Series
This article is part of a series1 discussing the integration of iterative data (commonly known as “structured data,”) and narrative data (commonly referred to as “unstructured data”). In short, iterative data repeats, whereas narrative data tells a story.
In a collection of iterative data such as a relational database table, the meaning of the data is iterative. But in narrative data (books, Web pages, emails, astute articles such as this one) the meaning across a set of instances is not repetitive (at least an author hopes not!). Unified management of iterative and narrative data is somewhat like the Six Million Dollar Man — “we have the technology” — the challenging part that we are now faced with is applying it.
The most recent article in this series2 introduced the concept of the Narrative Star Schema. Such a schema can potentially support very targeted search capabilities on narrative data — documents — that in their native form would need to be read by humans … a very time-consuming, sequential access method. A diagram of this schema is shown in figure 1 below; more details can be found in the previous article.
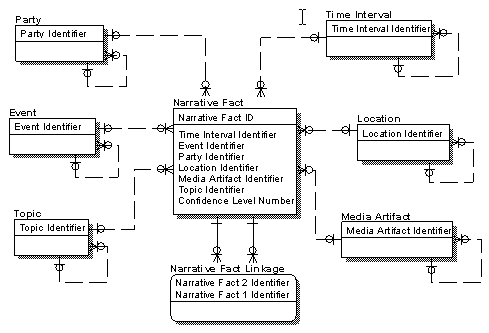
Figure 1: The Narrative Star Schema.
In this installment, we’ll describe the types of software products that provide the ETL (Extract, Transform and Load) functions required to populate a data mart implemented with this type of schema. These ETL functions can be summed up as tokenizing, recognizing, categorizing, and linking. Figure 2 below shows a high-level flow of these functions.
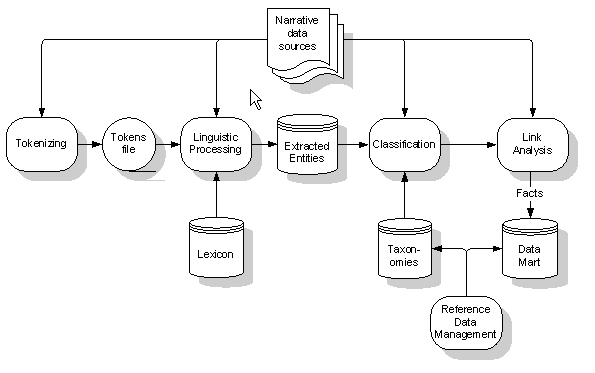
Figure 2: ETL Flow for populating the Narrative Data Mart.
There are two major functions in populating any star schema: building dimensions and building facts that reference the dimensions. In the world of narrative data, dimensions are taxonomies; facts are links. Documents, i.e., narrative data files, are the sources for facts. They may also be sources for dimensions in cases to which automated taxonomy building is applied.
The Web search engines with which we are all familiar are very good at tokenizing. This is where the process begins.
Tokenizing: Search Engines
Tokenizing is a process that divides up one or more narratives into distinct strings, or tokens, of characters, which are likely to have some meaning simply because of their occurrence in narrative form. Computer programs can be very good at parsing text into tokens, given a relatively simple set of rules for recognizing contiguous characters, spaces, punctuation, and “stop words” — words whose sole purpose is to connect other, more meaningful character strings together in a narrative.
Here’s a news flash: if you you think you’re searching the Web when you submit a search query using Yahoo!, Google, or Alta Vista, you’re wrong — what you’re actually doing is querying a data mart. The data marts underlying these tools are very large, very specialized and optimized data structures — specifically, indexes. In general, all they include are cross-references between tokens and Web pages. The background processes of these search engines include ETL functions to populate these indexes.
For those readers inclined toward experimentation, a downloadable version of an interesting text processing and extraction product, WebQL, is available from QL2 Software. Download requests can be submitted at www.ql2.com/unstructured_data_tool.php.
The word-tokens extracted by such a search tool, rather than just being used to build an index, can be passed on to subsequent processes that can bestow meaning on the word-tokens.
Recognizing: Linguistics
The token-recognition rules underlying search engines are quite basic compared to the more advanced software that can apply additional rules to the word-tokens output from a search engine. Such software products typically combine sophisticated linguistic and statistical processing with extensive proprietary reference tables, dictionaries, “lexicons,” or “knowledge bases,” to enable the inference of domain-specific meaning within a set of tokens. Products enabling this functionality are an outcome of studies in the fields of computational linguistics (CL) and natural language processing (NLP).
Linguistic processing enables recognition of parts of speech, e.g., the token “John” has a high likelihood of being a proper noun; “walked,” a verb in the past tense. Linguistics programs can also infer syntactical relationships among tokens in the context of a sentence (anybody remember diagramming sentences in grade school?), recognize synonyms, and adjust meanings based on the context of an entire document.
So when this step is done, we have not only a set of words, but also how they may be related syntactically, and some general idea as to what they could signify — most importantly, via a name designation.
Categorizing: Taxonomies
“Taxonomy building involves two tasks: the creation of the hierarchy, and the definition of the business rules that route documents to the appropriate category.”3
A taxonomy can be thought of a vocabulary arranged in a hierarchical fashion. One way to create a taxonomy is to pay a visit to www.vivisimo.com. There you’ll find a Web search engine that returns more than just a list of links — it builds a taxonomy at run time, categorizes its result set into this taxonomy, and gives the user the ability to navigate the taxonomy hierarchy.
This real-time “dimensionalization” done by Vivisimo is termed clustering. Clustering can result in a different taxonomy each time it’s done, based on the search terms and input data. It’s kind of like Forrest Gump’s box of chocolates — you never know what you’re gonna get.
On the other hand, classification, such as that supported by products such as Verity Collaborative Classifier, supports the construction and maintenance of pre-defined taxonomies. Taxonomy-management products also provide functions to define and manage rules for assigning extracted entities to categories — i.e., dimension members. These rules are invoked during our ETL process.
As pointed out earlier in this series, taxonomies and dimensions are, in general, independent implementations of essentially equivalent reference data.
“There are usually a number of internal or external resources that can assist in taxonomy design or the creation of business rules, including existing …product lists …”4
A strong corporate reference data management strategy can increase the effectiveness of managing reference data — on products, for example — in the various forms that may be required across an organization. As shown in figure 2, taxonomies and dimensions can, and should, be managed together as part of this strategy.
Connecting the Dots: Linking
The next transformation step in our narrative ETL flow involves recognizing and extracting links. Detecting links — connections between and among dimension members — is necessary to construct narrative facts. Just as is the case when constructing conventional fact table rows from iterative data, all dimension members referenced by a fact must have been recognized first, in earlier steps.
Link extraction builds on the prior extraction of entity instances and their categorization into dimension members. Recognizing links between members of any two dimension members — for example, a location for a person of interest — is challenging, let alone determining and building an n-dimensional fact.
Verity’s Relational Taxonomies, Megaputer’s PolyAnalyst Text OLAP, and NetOwl Extractor’s Link and Event Configuration are products that deduce links between extracted entities.
“Verity's Relational Taxonomy technology lets users browse through multiple taxonomies at the same time to quickly locate highly relevant information where the taxonomies intersect.”5
One step remains in our ETL process, and the construction of our link/facts will be complete.
Confidence Levels
An important concept in the extraction of narrative facts and dimensions is that of confidence levels. Typically in the world of iterative data, each data value is explicitly related to its meaning, by way of its assignment to a specific named column or field. A distinguishing characteristic of narrative data is the absence of these specific data-metadata assignments. The transformation of narrative data to iterative data is in large part the execution of educated guesses, the outcome of which is the deduction of data-metadata assignments.
For example, in a narrative data source, there will be no Person table, with a Name column in which the value of “John Adams” is stored. In our narrative-iterative transformation, based on a given set of rules, we can declare, with some level of confidence, that “John Adams” is the Name of a Person, and make this assignment at run time. Well, exactly how confident are we that “John Adams” is the name of a person?
The value of this confidence level — effectively, metadata about this assignment — can be determined, again, based upon rules. Some rule/input combinations are known to yield more consistently accurate results. For example, in an input document, if the token “D.C.” immediately follows the token “Washington,” our confidence is increased that the combination designates the name of a Location, rather than a Party such as “Washington Irving.”
Confidence-level values are relative, of course, rather than absolute. Each narrative fact can and should be assigned a confidence-level value based on the confidence levels of the rules by which it was created.
Business Applications
A “narrative data mart” can be of considerable value to any enterprise in which a significant percentage of data of interest appears in narrative or “unstructured” form — that is, just about any enterprise. The following table shows some examples of potential narrative dimension members for three types of enterprises. The facts that could be potentially represented and accessed effectively by users can be visualized by juxtaposing examples of dimension members from multiple cells in any column.
“Utilizing Text OLAP exploration engine, the user of PolyAnalyst can easily define dimensions of interest to be considered in text exploration and quickly dissect the results of the analysis across various combinations of these dimensions to gain insights in the investigated issue.”6
| Application / Narrative Dimension | Health Care | Law Enforcement | Customer Service |
| Event | Admission, Drug Reaction, Procedure, Symptom Presentation | Incident, Arrest | Help Desk Call, Service Call, Sale |
| Location | Home, Hospital | Jurisdiction, Municipal Area | Home, Office, Retail Outlet |
| Media Artifact | News Release, Government Advisory, Subscription Document | News Release, Communication Intercept | Email, Telephone transcription |
| Party | Patient, Doctor, Pharmacist | Suspect, Official | Customer, Technician, Reseller, Competitor |
| Topic | Protocol, Medication, Dosage | Weapon, Contraband, Stolen Property | Product, Feature |
| Fact Linkage | Family Relationship, Drug Interaction | Gang Membership | Product Configuration |
Table 1: Narrative Data Mart Applications.
Watch for the next installment of this series, which will present the user interface for this data mart, as well as other means for agile interaction with large quantities of narrative data.
References
More information on products mentioned in this article can be found at the following sites:
Megaputer, Inc., www.megaputer.com
NetOwl, Inc. www.netowl.com
QL2 Software, Inc. www.ql2.com
Verity, Inc., www.verity.com
Vivisimo www.vivisimo.com
1 Earlier articles can be found in EWSolutions’ Real World Decision Support newsletter, January, April, July 2004 issues, January and April 2005 issues; and DM Review, March 2004.
2 “A Star Schema Model for Narrative Data,” www.ewsolutions.com/newsletter.asp.
3 “Classification, Taxonomies and You,” Verity, Inc.
4 Ibid.
5www.verity.com/products/dictionary/relational-taxonomies.html
6http://www.megaputer.com/products/pa/algorithms/text_olap.php3
--
Bill Lewis is a Principal Consultant with Enterprise Warehousing Solutions. Bill's 20-plus years of information technology experience span the financial services, energy, health care, software and consulting industries. In addition to his current specializations in data management, meta data management and business intelligence, he has been a leading-edge practitioner and thought leader on topics ranging from software development tools to IT architecture. He has contributed to several online and print journals, and is the author of Data Warehousing and E-Commerce.
Bill Lewis
Last modified 2006-01-06 11:12 AM