
Terabyte Data Warehouse Table Design Choices - Part 2
Part 1 | Part 2
Introduction
In the first part of this article, I discussed partitioning large terabyte tables using various different keys, combinations of keys, and the important points of proper space definition for indexspaces and tablespaces. In this article, the discussion will be on design alternatives for large terabyte data warehousing tables using DB2 Version 8 for Linux, UNIX and Windows (LUW). DB2 LUW provides many design options such as Multi-Dimensional Clusters (MDC) and a UNION ALL views technique for managing maintenance and performance in your large data warehouse environment.
An Overall Design Consideration
The design points are different on the UNIX and Windows machines because the number of I/O channels and number of CPUs can vary tremendously from system to system. Each system configuration variation presents different CPU to I/O channel ratios. These different ratios can have a dramatic effect on overall performance, regardless of the partitioning techniques incorporated to design your multi-terabyte data warehouse properly. To address this CPU to I/O ratio, the general industry consensus is to have a CPU for every six to nine DASD drives. This recommendation can vary based on the memory cache associated with some of the new DASD configurations. If you want great performance, stick to this recommendation of six to nine DASD drives per CPU; there are a large majority of shops that can testify that it is still very valid.
Multi-Dimensional Clusters (MDC)
The MDC table definitions’ option was introduced in DB2 Version 7 for LUW and, in Version 8, it offers a way to spread out your data across multiple key dimensions. The MDC table definition utilizes multiple keys that allow the data to be separated or sliced along the first column key range then diced into smaller portions based on the next key column. The greater number of columns used in the MDC definition process, the greater the number of slices and dices partitions of data. These MDC separate the data along all of the MDC key column definitions separating the data into cubes of common column key values of information.
The Advantages of MDCs and One Note of Caution
For example, three keys such as 1) the region code, 2) customer number and 3) product SKU id, could result in three different dimensions or axes within a MDC table definition. See Example 1 below. The cube in the example reflects the three different key dimensions separating the data rows into separation parts or cubes within the table. The example shows how if we only had three values for each of the three keys, we could have 27 different combination or cubes. The danger with MDC tables is that if we had thousands of customers or products, then there could be hundreds of thousands of cubes. These MDC key definitions separate parts of the table and provide the table designer with the option to allocate or spread the data cubes to their desired number of different DASD volumes. With MDC tables, one advantage is that the database architect has the flexibility to separate the data to the optimum DASD configuration.
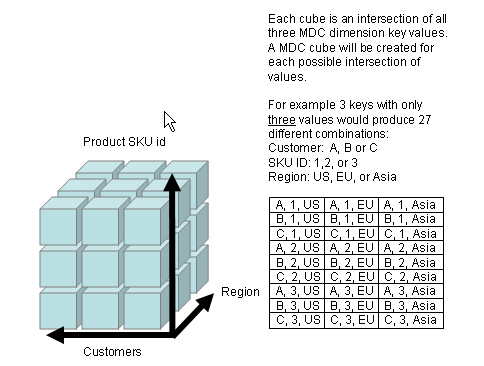
Example 1: MDC cubes
CREATE TABLE BEULKE.MDC_TABLE1 (
REGION_CODE CHAR(2) NOT NULL ,
CUSTOMER_NBR INTEGER NOT NULL ,
PROD_SKU_ID INTEGER NOT NULL ,
PROD_DEPT INTEGER NOT NULL ,
SALE_PRICE DECIMAL(9,2) NOT NULL )
ORGANIZE BY DIMENSIONS (REGION_CODE, CUSTOMER_NBR, PROD_SKU_ID)
IN BEULKE_SPACE1 ;
CREATE TABLE BEULKE.LARGE_PART1 (
REGION_CODE CHAR(2) NOT NULL ,
CUSTOMER_NBR INTEGER NOT NULL ,
PROD_SKU_ID INTEGER NOT NULL ,
PROD_DEPT INTEGER NOT NULL ,
SALE_PRICE DECIMAL(9,2) NOT NULL)
IN BEULKE_UV_SPACE1;
commit;
ALTER TABLE BEULKE.LARGE_PART1
ADD CONSTRAINT RANGKEY1 CHECK (CUSTOMER_NBR > 1 AND CUSTOMER_NBR <
1000) ;
commit;
CREATE TABLE BEULKE.LARGE_PART2 (
CUSTOMER_NBR INTEGER NOT NULL ,
PROD_SKU_ID INTEGER NOT NULL ,
PROD_DEPT INTEGER NOT NULL ,
REGION_CODE CHAR(2) NOT NULL ,
SALE_PRICE DECIMAL(9,2) NOT NULL )
IN BEULKE_UV_SPACE2;
ALTER TABLE BEULKE.LARGE_PART2
ADD CONSTRAINT RANGKEY2 CHECK (CUSTOMER_NBR > 1001 AND CUSTOMER_NBR
< 2000) ;
The other advantage of MDC tables are their use of block index structures that use block allocations for indexes instead of single index pages. By using blocks, the index entries are naturally clustered and at their best case target location. This allows access improvements by caching more index entries, quickly eliminates blocks not accessed by the SQL, and provides a bigger ideal target location for index entries during Update, Delete, and Insert activities.
For the MDC tables, the separation of the data is done based on each of the key column values and appropriately separates the data into the many cube DASD allocations. Since each value change for each MDC key value separates the data into a different cube, the number of cubes can quickly get very large. Analysis should be done to determine the number of values for each of the keys and the number of possible combinations or cubes.
Since the MDC dimension keys dictate the data row cube location, the data remains clustered eliminating the need for data reorganization except for reclaiming space. This feature alone makes MDC tables very attractive for large tables. MDC block indexes can also be leveraged in conjunction with additional standard indexes to provide multiple index access and high performance join activities.
An Important Consideration
Since the DASD allocations are required for each cube, each cube’s potential number of rows needs to be calculated and analyzed. Since each cube contains the intersection of the MDC dimension row values, the number of entries in each cube needs to be calculated. Empty cubes waste DASD and should be avoided; so, it is vital to verify your MDC key dimension choices so that cube density is as consistent as possible. Page size choices (4k, 8k 16k or 32k) provide flexibility to minimize the amount of DASD for each cube. Until the restriction of 255 DB2 rows per page is removed, choosing the best page size will conserve DASD and improve performance.
Analyzing Different Value Ranges
The DB2 Design Advisor can analyze different value ranges of the MDC key columns . The advisor can provide many different aspects for your table design. Unfortunately there are some limitations since the Design Advisor does not currently evaluate MDC table designs that incorporate two full columns for a single dimension key. Check the DB2 manuals for the limitations since the Design Advisor continues to be improved with every new DB2 maintenance FixPak.
Using UNION ALL Views
If you want more control over your partitioning in the DB2 LUW environment, another option is using UNION ALL views. To incorporate this technique, the architect defines the table definition and uses it multiple times with limits or constraints that check the key values of the desired pseudo partitioning keys. This technique allows tight control over the data loaded into each individual table. This technique also allows DB2 container and tablespace definitions to be tailored for the amount of data in each table. The example below specifies how to create the individual tables with the check constraints and then define a UNION ALL view incorporating accessing all the tables.
CREATE VIEW BEULKE.U_ALL_VIEW AS (
SELECT REGION_CODE, CUSTOMER_NBR, PROD_SKU_ID, PROD_DEPT, SALE_PRICE
FROM BEULKE.LARGE_PART1
UNION ALL
SELECT REGION_CODE, CUSTOMER_NBR, PROD_SKU_ID, PROD_DEPT, SALE_PRICE
FROM BEULKE.LARGE_PART2);
NOTE: There is a HIPER APAR IY66248 that requires the base tables to have some considerations for the creation of the base tables to be used in an UNION ALL view. One of the considerations is that the columns of the base table be defined in a different order which was used in this example. This should be corrected in a FixPak shortly.
The applications would then reference the UNION ALL view U_ALL_VIEW, and would get all their appropriate data. Additionally end users would be also able to use all type of SQL standard INSERT, UPDATE and DELETE statements. This technique offers many advantages since it can be used several different ways with specific tablespace and DASD container properties that compress, isolate or have additional indexes on certain parts of the data ranges.
This UNION ALL technique has saved many of my clients with issues related to time-sensitive database designs. These databases usually have an extremely volatile current timeframe, month, or day portion and the older data is rarely updated. Using different container DASD allocations, tablespaces, tables, and index definitions, the settings can be tuned for the specific performance considerations for these different volatility levels and update frequency situations.
What to do with Tiny Tables
Another technique which may be appropriate for tiny tables on DB2 LUW, is to use a new Version 8.1 Fixpak 4 table type called Range Clustered Table (RCT). This table type specifies a column key range for data going into the table. Any data row not fitting into the range is put into an overflow area. This implementation is not really appropriate in its current implementation for large terabyte tables, but it will hopefully be improved to be like range partitioning on the z/OS in the future.
Conclusion
Using MDC and UNION ALL table design techniques for terabytes of data has helped numerous clients solve their tough performance and maintenance issues. Hopefully these techniques can help you be successful with your next terabyte database design.
--
David Beulke is an internationally recognized DB2 consultant, author and lecturer. He is known for his extensive expertise in database performance, data warehouses and internet applications. He is currently a member of the IBM DB2 Gold Consultant program, co-author of the IBM V8 and V7 z/OS DB2 Certification exams, co-author of the Business Intelligence Certification exam, past president of the International DB2 Users Group (IDUG), columnist for DB2 Magazine, former instructor for The Data Warehouse Institute (TDWI), and former editor of the IDUG Solutions Journal. He has helped clients with system and application issues on the mainframe, UNIX and Windows environments and has over 20 years experience in numerous industries. He can be reached at DaveBeulke@cs.com or 703 798-3283.
Contributors : David Beulke
Last modified 2006-01-04 03:27 PM