
 Redo Log File Sizing Advisor
Redo Log File Sizing Advisor
Oracle Checkpoints
Oracle's checkpoint mechanism ensures that data contained in the buffer cache
is safely written to disk on a regular basis. During a checkpoint, the DBWR
background process flushes dirty blocks contained in the buffer cache to the
database datafiles and the CKPT background process updates the datafile headers
with checkpoint information. Data
that has been transferred to the data files no long requires redo for recovery.
The modified data buffers that have been flushed are marked as free and can
be reused for new data.
The two types of Oracle checkpoints are full and incremental. Full checkpoints will occur when the administrator manually issues a checkpoint command or the database is shutdown using the normal, transactional or immediate options. A full checkpoint ensures that all of the dirty blocks contained in the buffer cache are written to the data files. The database is thought of as being in a synchronized state at this time. Although a normal, or incremental, checkpoint does write blocks that have been dirty the longest time to disk, it does not ensure that all of the dirty blocks contained in the cache are written to the data files. Oracle technicians coined the phrase "lazy checkpointer" to describe incremental checkpoints.
One (out of several) reasons Oracle can fire an incremental checkpoint is when it switches from one log group to another. When Oracle fills a log group, a checkpoint is fired and Oracle then begins writing to the next redo log group. This continues in a circular fashion; when all log groups are filled, Oracle reuses the first group.
A common rule of thumb is to adjust the redo log file's size so that Oracle performs a log switch every 15 to 30 minutes. Log switches that occur more frequently may have a negative impact on performance. Log switches that occur several times a minute have a definite impact on database performance.
Using the Redo
Log File Size Advisor in Oracle 10G
If you have the FAST_START_MTTR target parameter set for your database, you
will be able to use 10G Grid Controls' redo log file advisor to help you determine
the initial size of your redo log files.
We start by activating 10G Grid Control or 10G Database Control and navigating to the Administration Home page. Since I'm using an early version of Database Control in this exercise, those of you using a later version of Grid or Database Control may see something a little different. When I click on the Redo Log Group navigation link, Database Control responds by displaying the Redo Log Groups Main Administration page. Notice that I have selected "Sizing Advice" from the drop down menu.
When I do that, you'll notice that Database Control responds by displaying an error message telling me that setting FAST_START_MTTR target is required to be set before the tool will offer advice on the proper sizing of the online redo logs. If you would like to learn more about FAST_START_MTTR_TARGET, please refer to my blog titled "A Few More of Oracle 10G's Automatic Features."
This next screenshot shows sizing advice from 10G Grid Control for a database that does have FAST_START_MTTR_TARGET set. 10G Grid Control is advising me that the optimal size for the online redo log group files is 104 megabytes.
You don't have to use the 10G Database/Grid Control SGTs (Sissy GUI Tools) to provide this advice. If you have FAST_START_MTTR target set, the sizing advice will be contained in the OPTIMAL_LOGFILE_SIZE column in the dynamic performance table V$INSTANCE_RECOVERY.
If you look at the Oracle documentation, every section that discusses the Redo Log File Size Advisor provides the same advice "It is recommended that the user configure all online redo logs to be at least this value." I think the key words are "at least this value." Personally, I use the recommended value as a starting point and then double-check the advisor's advice by performing a manual sizing review of the redo log files.
Manually Determining
the Optimal Redo Log File Size
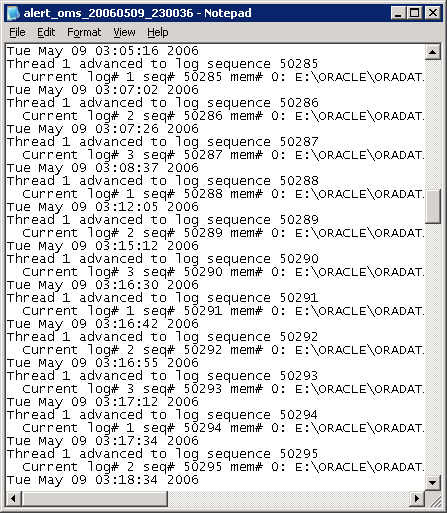
Checking messages in the alert log is another easy way to determine how fast
Oracle is filling and switching logs. Here's an example of a production database's
alert
log that shows redo log switches occurring too frequently. Notice that the
timestamps show that the logs are switching every minute or so.
If the following messages are found, you can be sure that performance is definitely being affected:
Thread 1 advanced
to log sequence 248
Current log# 2 seq# 248 mem# 0: /orant/oradata/logs/redolog2a.log
Thread 1 cannot allocate new log, sequence 249
Checkpoint not complete
The "checkpoint not complete" messages are generated because the logs are switching so fast that the checkpoint associated with the log switch isn't complete. During that time, Oracle's LGWR process has filled up the other redo log groups and is now waiting for the first checkpoint to successfully execute. It can't overwrite the contents of the redo log until the information covered by that log is flushed to the data files. Oracle will stop processing until the checkpoint completes successfully.
Performance can be dramatically improved by increasing the log sizes so that logs switches occur at the recommended interval of 15 to 30 minutes. Identify the current size of the redo log members from V$LOG, record the number of log switches per hour and increase the size of the log to allow Oracle to switch at the recommended rate of one switch per 15 to 30 minutes.
For example, if the database log size is 1 megabyte and you are switching logs every 1 minute, you will need to increase the log size to 30 megabytes in size to allow it to switch every 30 minutes.
The problem is that many applications have workloads that vary dramatically throughout each 24-hour time-period. In addition, application-processing workloads may vary according to the days of the calendar month. Month-end and mid-month processing may increase the number of changes occurring in the database. This higher level of activity may cause the redo logs to be filled much more quickly than during off-peak times. The DBA must make sure that the on-line redo logs don't switch too often during periods of high activity and switch often enough during times of low processing workloads. In addition, administrators must also be concerned about how the size of the online redo logs affect instance recovery. The less checkpoints taken, the longer instance recovery will take.
The LOG_CHECKPOINT_TIMEOUT, LOG_CHECKPOINT_INTERVAL and FAST_START_MTTR_TARGET parameters can help to decrease the time of instance recoveries. For more information, please refer to my blog titled "A Few More of Oracle 10G's Automatic Features."
Data Loss
It is important to note that these parameters will not reduce the amount of
data lost in certain database recovery scenarios. For example, let's say we
lose a single database datafile. We restore the datafile from the backup and
begin the recovery process. Since we will be recovering the datafile up to the
current point-in-time, we'll need all of our archived and online redo logs that
were active since the backup was taken. We'll use all of the information contained
in the archived and online logs to "redo" all of the changes that
took place. The only data that will be lost will be from transactions that were
in-flight (active) when the failure occurred.
If a lost or damaged archived or online redo log is used as input to our database recovery, the amount of data lost will be directly proportional to the amount of time that redo log or logs were active. We will be forced to restore all of the database datafiles from the backup and recover the database up to the bad or missing archived or online redo log. All data after that point will not be recovered.
In case of a bad archive log, the farther back in time the bad archive log corresponds to, the more data that will be lost. Since we now know that the size of the redo logs determine how long the log will be active, the larger the log, the more data loss there will be if we use a bad or missing log as input to our recovery.
That's why administrators multiplex both their online and archived redo logs. They ensure that their online redo log groups have multiple members on different disk drives and send their archives off to more than one destination.
I have seen administrators size their online redo logs to accommodate their highest periods of activity and create PL/SQL programs to ensure that the logs switch every 15 to 30 minutes during times when activity is low. The intelligence in the programs vary from just waking up and doing a log switch to checking to see when the last log switch occurred before executing the log switch command.
I have also seen the initialization parameter ARCHIVE_LAG_TARGET be used to force log switches at regular intervals. Although the parameter is intended to control the amount of data that is lost in a standby database environment during a catastrophic failure scenario, some savvy administrators set their online redo logs to accommodate peak activity and set ARCHIVE_LAG_TARGET to ensure the logs switch at regular intervals during lower activity time periods.
Whatever method you use, one of the keys to good database performance is to ensure that you aren't switching logs at too fast of a rate. Use the sizing advice provided above to help you on you way.
Thanks for reading (and happy sizing),
Chris Foot


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}